ETL vs EAI vs Kafka
이번 장에서는 ETL과 EAI에 대해서 알아보고 최근 많이 사용되고 있는 Kafka에 대해서 알아본다.
ETL(Extracting & Transformation & Loading)
1990년대 소매 조직에서 구매자 트렌드를 분석하기 위해 사용되기 시적하였다.

ETL은 다양한 데이터 소스에서 데이터를 추출(Extracting)하여 필요한 데이터로 변환(Transformation)하고 데이터를 필요로 하는 곳으로 로딩(Loading)하는 것을 의미한다.
ELT을 쉽게 할 수 있게 제공해주는 툴을 제공하는 업체들이 존재하며 원하는 데이터로 변환하는 비즈니스 로직이 있어야 한다. 주로 데이터베이스의 데이터를 통합하는데 많이 사용되며 대용량 데이터를 일정 주기마다 배치성으로 처리한다. 일정 주기로 작동되는 만큼 GB 단위의 큰 데이터를 다루며 Real Time으로 작동되지 않는다.
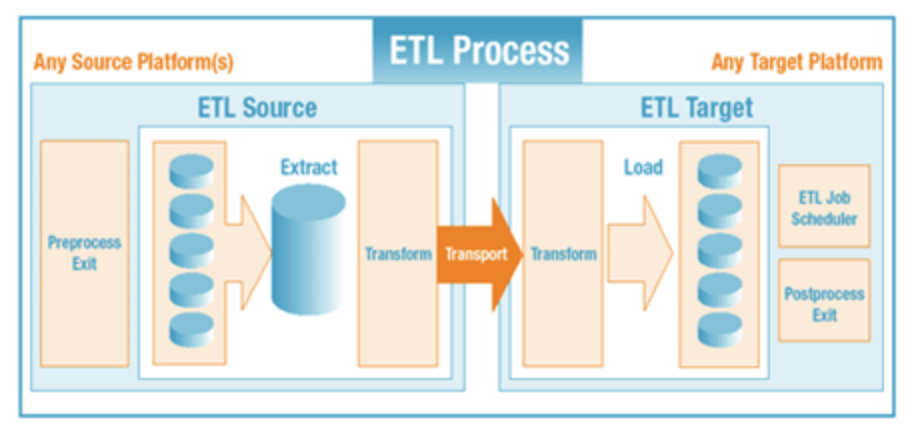
ETL은 아래와 같은 단점을 가지고 있다.
- 모든 DB나 서비스가 공유하는 글로벌 스키마(Global Schema)가 필요하다.
- 데이터 정리 및 큐레이션이 수동이기 때문에 오류 발생률이 높다.
- 운영 비용이 높고, 시간과 자원이 집약적이다.
- ETL 툴은 데이터베이스와 데이터 웨어하우스에 초점이 맞춰져 있다.
EAI(Enterprise Application Integration)
EAI는 기존 애플리케이션간에 Point To Point 방식의 복잡함을 해결하기 위하여 등장하였다.
Point To Point 방식은 애플리케이션간에 강한 결합력이 생기게 되고 인터페이스가 분산화되어 있으며 표준화되어 있기 때문에 복잡할 수 밖에 없다. 또한 데이터의 정합성을 맞추거나 유지보수에 큰 어려움이 발생한다.

애플리케이션들이 EAI를 통해서 중앙집중적으로 통신하게 되면 애플리케이션간의 결합도가 낮아지게 된다. 결합도가 낮아지기 때문에 능률적으로 서로다른 애플리케이션간의 커뮤니케이션을 통합시킬 수 있다.
ETL은 여러 데이터 소스에서 데이터를 추출하여 변환하고 새로운 곳에 로딩하는 것을 의미하였다. EAI는 이름처럼 여러 애플리케이션 간의 통합을 의미한다.
여러 곳의 데이터를 통합한다는 관점에서 ETL과 동일하지만 누적되어 있는 데이터베이스의 데이터가 아니라 애플리케이션을 통합한다는 점에서 차이가 있다.
소량의 데이터를 실시간으로 처리한다는 점도 ETL과 차이가 있으며 무엇보다 트랜잭션을 지원한다.
ETL은 데이터베이스, EAI는 애플리케이션에 초점이 맞춰져 있을 뿐 둘의 차이는 실시간으로 처리하는가 배치성으로 한 번에 처리하는가 정도의 차이만 있으므로 ETL이 실시간이라면 EAI라고 볼 수 있다.
Confluent의 발표자료에 따르면 ETL과 EAI의 이러한 한계로 인해 구식의 기술이며 스트리밍 방식을 도입해야 한다고 말하고 있다.
Streaming
그래프를 살펴보면 EAI는 실시간이지만 수평적인 확장을 지원하지 않는다. ETL은 수평적인 확장이 가능하지만 배치성으로 실행되어 실시간으로 처리가 불가능하다. 스트리밍 플랫폼은 실시간이며 수평적인 확장이 가능하다.

물론 ETL과 Streaming를 같은 역할을 하는 기술로 비교하기에는 무리가 있다.
ETL을 구현하는 방법에 배치성으로 데이터를 처리하는 방식이 있고 스트리밍 방식으로 처리하는 방식이 있기 때문이다.
최근 데이터 생태계의 요구사항은 아래와 같다.
- high-volume(큰 용량)
- high-diversity(높은 정확도)
- fault tolerance(내결함성)
- parallelism(병렬성)
- latency(낮은 응답시간)
- delivery semantics(전달 의미론)
- operations and monitoring(운영 및 모니터링)
- schema management(스키마 관리)
이러한 요구사항을 처리하기 위해서 데이터를 모아서 한 번에 처리하는 배치 방식이 아니라 아래와 같이 이벤트 중심으로 데이터를 처리하는 이벤트 중심으로 아키텍처를 구축(Event-centric thinking)하는 것이 좋다.

배치 방식의 ETL이 데이터를 처리하는 방법을 보면 아래의 이미지와 같다.

- 비정형 문자열을 추출한다.
- 화면에 보여질 데이터로 변환한다.
- 데이터웨어하우스나 카산드라와 같은 데이터베이스에 로딩한다.
- P2 필드를 제거한다.
스트리밍 플랫폼을 적용하면 아래와 같이 작동한다.

- 정형화된 뷰 이벤트 데이터를 추출한다.
- P2 필드를 제거하고 상용 메타데이터를 보완한다.
- 상용 뷰 스트림을 로딩한다.
- 필터링되고 보완된 상용 뷰 스트림을 로딩한다.
Kafka
구체적으로 스트리밍 방식으로 데이터 파이프라인을 만들 수 있게 해주기 위해 사용되는 기술이 Apache사의 Kafka다. 카프카는 스트리밍 데이터 파이프라인을 만들 수 있게 해주며, 스트리밍을 하며 반환을 할 수 있게 하여 애플리케이션을 확장 가능하게 통합할 수 있도록 해준다.
Kafka Connect
카프카의 Connect는 ETL에서 E와 L인 추출과 로딩을 담당한다.

구체적으로 Source Connector는 데이터 소스에서 카프카로 데이터를 전달하는 역할을 하고 Sink Connector는 카프카에서 다른 목적지로 데이터를 보내는 역할을 한다.

Kafka Streams
카프카의 Stream은 ETL에서 T인 데이터 변환을 담당한다.
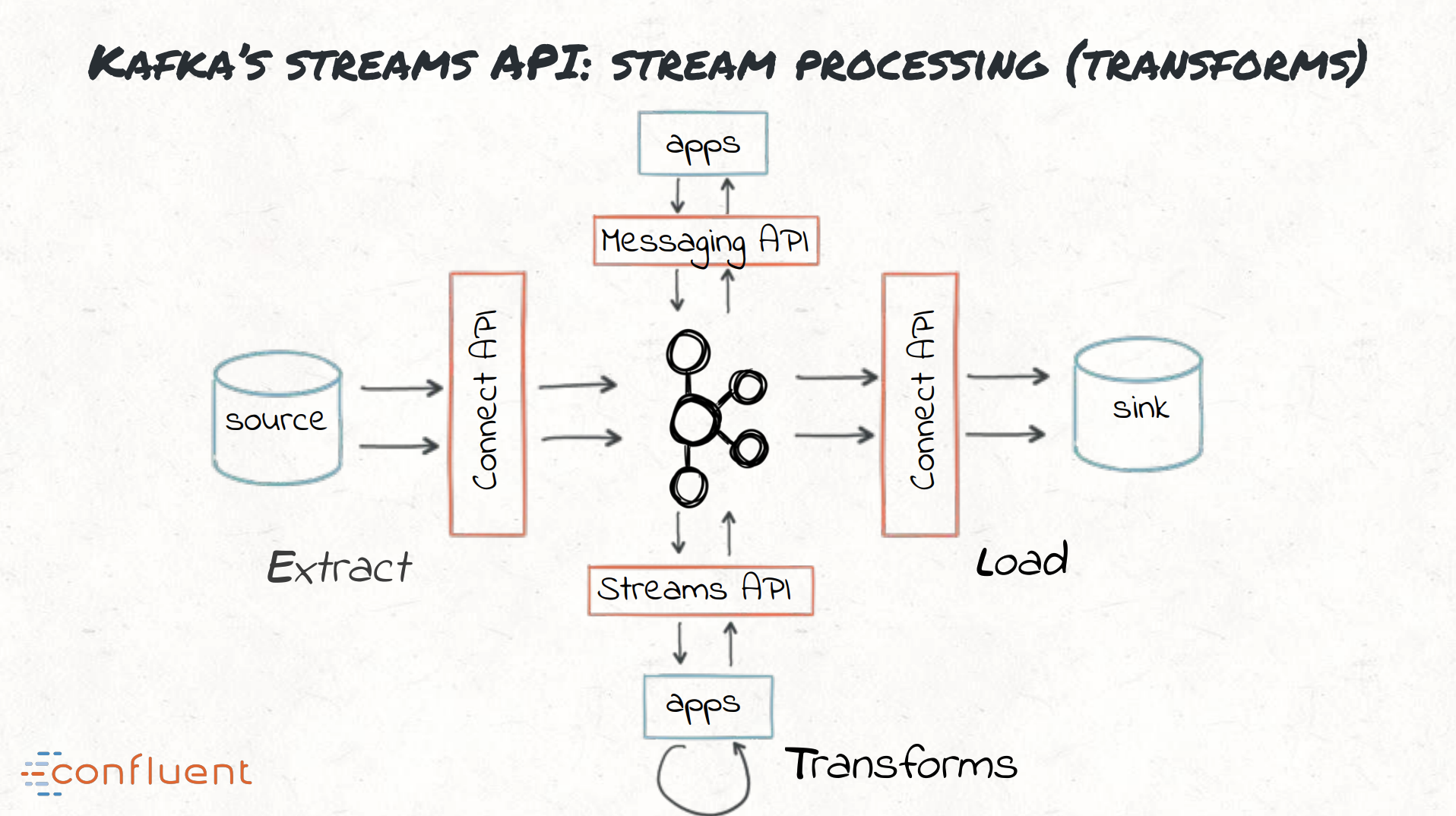
데이터를 변환하기 위한 join, map, filter와 같은 다양한 연산자인 DSL이 존재한다. DSL은 특정 영역을 타겟하고 있는 언어를 의미한다.
참고한 자료
- https://chunun.com/entry/EAI%EC%99%80-ETL%EC%9D%B4%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80
- https://m.blog.naver.com/dktmrorl/222140804526
- https://bcho.tistory.com/334
- https://data-engineer-tech.tistory.com/37
- https://dataonair.or.kr/db-tech-reference/d-story/data-story/?mod=document&uid=62828
- https://wwweb.tistory.com/entry/EAI-ETL-%EB%AF%B8%EB%93%A4%EC%9B%A8%EC%96%B4-%EC%A0%95%EC%9D%98