Advanced Amazon S3
이번 장에서는 SAA를 준비하며 S3의 심화 기능에 대해서 알아보도록 한다.
S3 MFA-Delete
- “MFA”는 S3에서 중요한 작업을 수행하기 전에 사용자가 장치에서 코드를 생성하도록 한다.
- “MFA-Delete”를 사용하려면 S3 버킷에서 "버전 관리"를 활성화해야 한다.
- 아래의 작업들을 위해 MFA가 필요하다.
- 객체 버전을 영구적으로 삭제한다.
- 버킷에서 버전 관리를 일시 중지한다.
- 아래의 작업들은 MFA가 필요하지 않다.
- 버전 관리 활성화
- 삭제된 버전 목록 확인
- 버킷 소유자(루트 계정)만 “MFA-Delete”를 활성화 또는 비활성화할 수 있다.
- “MFA-Delete”는 현재 CLI를 통해서만 활성화할 수 있다.
S3 기본 암호화(Default Encryption) vs 버킷 정책(Bucket Policies)
- “강제 암호화”하는 한 가지 방법은 “버킷 정책을 사용하고 암호화를 거부하는 것”이다.
아래는 암호화 헤더없이 S3 객체를 PUT하기 위한 API 호출이다.

- 또 다른 방법으로는 S3에서 “기본 암호화” 옵션을 사용하는 것이다.
- 참고로 버킷 정책은 “기본 암호화”보다 우선되어 평가된다.
S3 액세스 로그
- 감시의 목적으로, S3에 대한 모든 액세스 관련 로그를 다른 버킷에 저장할 수 있다.
- 승인 또는 거부된 모든 계정에서 S3에 대한 모든 요청은 다른 S3 버킷에 로그인된다.
- 해당 데이터는 “Amazon Athena”와 같은 데이터 분석 도구를 사용하여 분석할 수 있다.
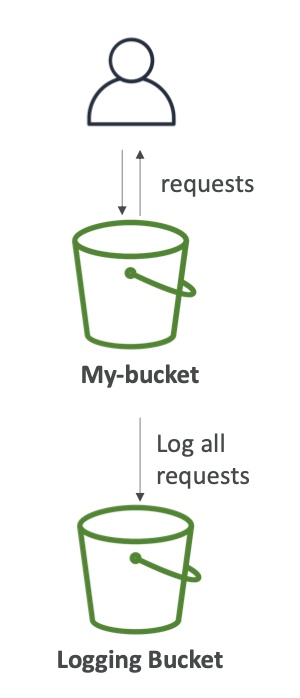
- 단, 로그를 저장하는 버킷을 모니터링의 대상이 되는 버킷으로 지정하면 안된다.
- 로깅 루프가 생성되고 버킷 크기가 기하급수적으로 증가하게 된다.

S3 복제(CRR or SRR)
- 소스 및 대상에서 버전 관리를 활성화해야 한다.
- CRR(Cross-Region Replication)은 교차 지역 복제를 의미한다.
- SRR(Same-Region Replication)은 동일한 지역 복제를 의미한다.
- 버킷은 서로 다른 계정에 있을 수 있다.
- S3 복제는 비동기로 진행된다.
- S3 복제를 위해 적절한 IAM 권한을 부여해야 한다.
- CRR 사용 사례는 아래와 같다.
- Compliance: 규정 준수
- Lower latency access: 짧은 지연 시간 액세스
- Replication across accounts: 계정 간 복제
- SRR 사용 사례는 아래와 같다.
- Log aggregation: 로그 집계
- 프로덕션 계정과 테스트 계정 간의 라이브 복제
S3 복제 - 참고 사항
- 활성화 후에는 새로운 객체만 복제되며 소급 적용되지 않는다.
- 삭제 작업의 경우 참고 사항은 아래와 같다.
- 소스에서 대상으로 삭제 마커를 복제할 수 있다.(optional)
- 악의적 삭제를 방지하기 위해 버전 ID가 있는 삭제는 복제되지 않는다.
- 복제 “연쇄(Chaining)”가 존재하지 않는다.
- 버킷1 → 버킷2에 대한 복제가 있고, 버킷2 → 버킷3 복제가 있는 경우, 버킷1에 생성된 객체가 버킷3에 복제되지 않는다.
S3 사전 서명된(Pre-Signed) URLs
- SDK 또는 CLI를 사용하여 “사전 서명된 URL”을 생성할 수 있다.
- 다운로드를 위한 URL(CLI를 통해 쉽게 생성이 가능하다.)
- 업로드를 위한 URL(SDK를 사용해야 하며, 생성이 어렵다.)
- 기본값 3600초 동안 유효하며
--expires-in의[TIME_BY_SECONDS]값을 사용하여 만료 시간을 변경할 수 있다. - “사전 서명된 URL”이 제공된 사용자는
GET/PUT에 대한 URL을 생성한 사용자의 권한을 상속한다. - “사전 서명된 URL”의 사용 예시는 아래와 같다.
- 로그인한 사용자만 S3 버킷에 프리미엄 비디오를 다운로드하도록 허용할 수 있다.
- URL을 동적으로 생성하여 끊임없이 변화하는 사용자 목록이 파일을 다운로드하도록 허용할 수 있다.
- 일시적으로 사용자가 버킷의 정확한 위치에 파일을 업로드할 수 있도록 허용할 수 있다.
S3 Storage Classes
- 현재 제공되는 S3 스토리지 클래스의 종류는 아래와 같다.
- Amazon S3 Standard - General Purpose
- Amazon S3 Standard-Infrequent Access (IA)
- Amazon S3 One Zone-Infrequent Access
- Amazon S3 Intelligent Tiering
- Amazon Glacier
- Amazon Glacier Deep Archive
- Amazon S3 Reduced Redundancy Storage(deprecated, 더 이상 사용되지 않음)
S3 Standard - General Purpose
- 객체는 다중 가용지역에 걸쳐 있으며 높은 내구성(99.999999999%)을 제공한다.
- Amazon S3에 10,000,000개의 객체를 저장하는 경우 평균적으로 10,000년에 한 번 단일 객체의 손실이 발생할 것으로 예상할 수 있는 내구성이다.
- 99.99% 가용성
- 2개의 동시 설비 장애 유지
- 대표적인 사용 사례는 아래와 같다.
- 빅데이터 분석
- 모바일 및 게임 애플리케이션
- 콘텐츠 분포
S3 Standard - Infrequent Access(IA)
- 액세스 빈도가 낮지만 필요할 때 신속하게 액세스해야 하는 데이터에 적합하다.
- 객체는 다중 가용지역에 걸쳐 있으며 높은 내구성(99.999999999%)을 제공한다.
- 99.9%의 가용성
- Amazon S3 Standard에 비해 저렴한 비용
- 2개의 동시 설비 장애 유지
- 대표적인 사용 사례는 아래와 같다.
- 재해 복구
- 백업을 위한 데이터 저장소
S3 One Zone - Infrequent Access(IA)
- “IA”와 동일하지만 데이터가 단일 AZ에 저장된다.
- 단일 AZ에 있는 객체의 높은 내구성(99.999999999%)을 제공하지만, 가용지역이 파괴되면 데이터가 손실된다.
- 짧은 대기 시간 및 높은 처리량을 제공한다.
- 전송 데이터 및 저장 데이터 암호화에 대해 SSL을 지원한다.
- IA에 비해 20% 정도 저렴한 비용에 사용할 수 있다.
- 대표적인 사용 사례는 아래와 같다.
- 온프레미스 데이터의 2차 백업 사본 저장 및 또는 재생성할 수 있는 데이터 저장
S3 Intelligent Tiering
- S3 Standard와 동일한 짧은 대기 시간 및 높은 처리량
- 적은 월별 모니터링 및 자동 계층화 요금
- 액세스 패턴 변화에 따라 두 액세스 계층 간에 객체를 자동으로 이동
- 여러 가용 영역에 있는 객체의 99.999999999% 내구성을 위해 설계되었다.
- 전체 가용 영역에 영향을 미치는 이벤트에 대해 복원력이 있다.
- 특정 연도 동안 99.9%의 가용성을 위해 설계되었다.
Amazon Glacier
- Archiving 또는 Backup을 위한 저비용 객체 스토리지다.
- 데이터는 장기간(10년)동안 보존된다.
- 온프레미스 자기 테이프(magnetic tape) 스토리지에 대한 대안이다.
- 월 스토리지당 비용은 $0.004/GB이며, 검색하는 경우 검색 비용이 추가된다.
- “Glacier”의 각 항목은 “아카이브”라고 하며 최대 40TB까지 저장할 수 있다.
- “아카이브”는 “Vaults”에 저장된다.
S3 스토리지 클래스 비교
| S3 Standard | S3 Intelligent-Tiering | S3 Standard-IA | S3 One Zone-IA | S3 Glacier | S3 Glacier Deep Archive | |
|---|---|---|---|---|---|---|
| Designed for durability | 99.999999999%(119’s) | 99.999999999%(119’s) | 99.999999999%(119’s) | 99.999999999%(119’s) | 99.999999999%(119’s) | 99.999999999%(119’s) |
| Designed for availability | 99.99% | 99.99% | 99.99% | 99.99% | 99.99% | 99.99% |
| Availability SLA | 99.9% | 99% | 99% | 99% | 99.9% | 99.9% |
| Availability Zones | ≥3 | ≥3 | ≥3 | 1 | ≥3 | ≥3 |
| Minimum capacity charge | N/A | N/A | 128KB | 128KB | 40KB | 40KB |
| Minimum storage duration charge | N/A | 30 days | 30 days | 30 days | 90 days | 180 days |
| Retrieval fee | N/A | N/A | per GB retrived | per GB retrived | per GB retrived | per GB retrived |
스토리지 클래스 가격 비교
| S3 Standard | S3 Intelligent-Tiering | S3 Standard-IA | S3 One Zone-IA | S3 Glacier | S3 Glacier Deep Archive | |
|---|---|---|---|---|---|---|
| Storage Cost(per GB per month) | $0.023 | $0.0125 ~ 0.023 | $0.0125 | $0.01 | $0.004 Minimum 90 days | $0.00099 Minimum 180 days |
| Retrieval Cost(per 1000 requests) | GET $0.0004 | GET $0.0004 | GET $0.001 | GET $0.001 | GET $0.0004 + Expeditied ~ $10.00 Standard ~ $0.05 Bulk ~ $0.025 | GET $0.0004 + Standard ~ $0.10 Bulk ~ $0.025 |
| Time to retrieve | instantaneous | Instantaneous | Instantaneous | Instantaneous | Expedited (1 to 5 minutes) Standard (3 to 5 hours) Bulk (5 to 12 hours) | Standard(12 hours) Bulk(48 hours) |
| Monitoring Cost(per 1000 objects) | $0.0025 |
스토리지 클래스 간 이동

- 스리지 클래스 간에 객체를 전환할 수 있다.
- 자주 접근하지 않는 객체의 경우
STANDARD-IA로 이동한다. - 실시간으로 검색이 필요하지 않은 아카이브 객체의 경우
GLACIER또는DEEP_ARCHIVE로 이동한다. - 수명 주기 구성을 사용하여 객체 이동을 자동화할 수 있다.
S3 수명 주기 규칙
- Transition actions: 객체가 다른 스토리지로 트랜지션 되는 시점을 정의한다.
- 생성 60일 후에
Standard IA클래스로 객체 이동 - 6개월 후 보관을 위해
Glacier로 이동
- 생성 60일 후에
- Expiration actions: 일정 시간 후에 만료(삭제)되도록 객체를 구성한다.
- 365일 후에 삭제되도록 액세스 로그 파일을 설정할 수 있다.
- 파일의 이전 버전을 삭제하는 데 사용할 수 있다.(버전 관리가 활성화된 경우)
- 완료되지 않은 multi-part 업로드를 삭제하는 데 사용할 수 있다.
- 특정 접두사에 대해 규칙을 생성할 수 있다. (예 -
s3://mybucket/mp3/*) - 특정 객체 태그에 대해 규칙을 생성할 수 있다. (예 -
Department:Finance)
S3 생명 주기 규칙 - 시나리오 1
- Q. EC2에서 실행되는 애플리케이션은 프로필 사진이 Amazon S3에 업로드된 후 썸네일을 생성한다. 이 썸네일은 쉽게 다시 만들 수 있으며 45일 동안만 보관하면 된다. 소스 이미지는 이 45일 동안 즉시 검색할 수 있어야 하며 그 이후에는 사용자가 최대 6시간을 기다릴 수 있다. 솔루션 아키텍트는 어떻게 설계를 할 것인가.
- A1. S3 소스 이미지는 45일 후에
Glacier로 전환하는 수명 주기 구성과 함께Standard일 수 있다. - A2. S3 썸네일은 45일 후에 만료 하도록 수명 주기가 있는
Onezone_IA에 있을 수 있다.
S3 생명 주기 규칙 - 시나리오 2
- Q. 회사의 규칙에 따르면 삭제된 S3 객체를 15일 동안 즉시 복구할 수 있어야 하지만, 이러한 작업은 드물게 발생한다. 15일이 지나면 최대 365일 동안 삭제된 객체를 48시간 이내에 복구할 수 있어야 한다. 솔루션 아키텍트는 어떻게 설계를 할 것인가.
- A1. “삭제된 객체”가 실제로 “삭제 마커”에 의해 숨겨지고 복구될 수 있도록 객체 버전을 사용하려면 “S3 버전 관리”를 활성화해야 한다.
- A2. 이렇게 구버전의 객체를
S3_IA로 전환할 수 있다. - A3. 이후에 구버전 객체를
Deep Archive로 전환할 수 있다.
S3 분석 - 스토리지 클래스 분석
- 객체를 전환할 시기를 결정하는 데 도움이 되도록 S3 Analytics를 사용할 수 있고 객체의 클래스를
SANDARD에서STANDARD_IA로 변경할 수 있다. ONEZONE_IA또는GLACIER에서는 작동하지 않는다.- 보고서는 매일 업데이트되며 처음 시작하는 데 약 24시간에서 48시간이 소요된다.
- 수명 주기 규칙을 통합 또는 개선하기 위한 좋은 방법이다.
S3 기준 성능
- Amazon S3는 높은 요청 비율, 지연 시간 100 ~ 200ms로 자동 확장된다.
- 애플리케이션은 버킷의 접두사당 초당 최소 3,500개의 PUT/COPY/POST/DELETE 및 5,500개의 GET/HEAD 요청을 달성할 수 있다.
- 버킷의 접두사 수에는 제한이 없다.
- 예시 (object path → prefix)
bucket/folter1/sub1/file→/folder1/sub1/bucket/folder1/sub2/file→/folder1/sub2/bucket/1/file→/1/bucket/2/file→/2/
- 4개의 모든 접두사에 읽기를 균등하게 분산하면 GET 및 HEAD에 대해 초당 22,000개의 요청을 달성할 수 있다.
KMS Limitation
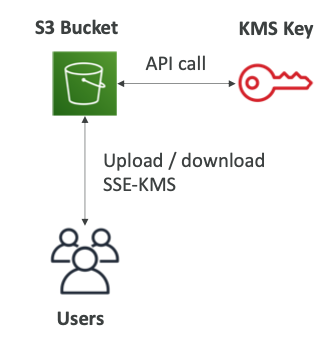
- SSE-KMS를 사용하는 경우 KMS 제한의 영항을 받을 수 있다.
- 업로드할 때,
GenerateDataKeyKMS API를 호출한다. - 다운로드할 때,
DecryptKMS API를 호출한다. - 초당 KMS 할당량 계산한다. (지역에 따라 5,500, 10,000, 30,000 req/s)
- 서비스 할당량 콘솔(Service Quotas Console)을 사용하여 할당량 증가를 요청할 수 있다.
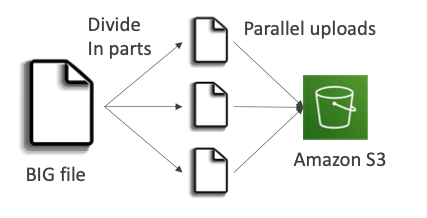
S3 Performance
- Multi-Part 업로드
- 100MB 이상의 크기에 권장되고, 5GB이상 크기에 필수적으로 사용된다.
- 업로드 병렬로 업로드하도록 하여 전송 속도를 향상시킬 수 있다.
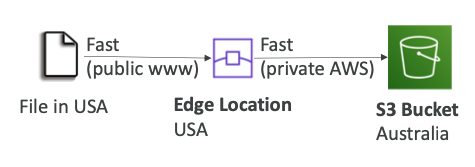
- S3 Transfer Acceleration
- 대상 리전의 S3 버킷으로 데이터를 전달할 AWS 엣지 로케이션으로 파일을 전송하여 전송 속도를 높인다.
- multi-part 업로드와 호환된다.
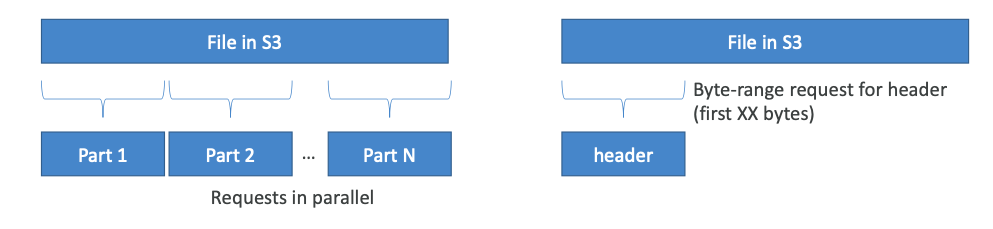
S3 Byte-Range Fetches
- 특정 바이트 범위를 GET 병렬화로 요청할 수 있다.
- 장애가 발생하였을 때 복원력을 향상시킨다.
- 다운로드 속도를 높이는데 사용할 수 있다.
- 부분 데이터만 검색하는 데 사용할 수 있다. 예를 들어, 파일의 헤드
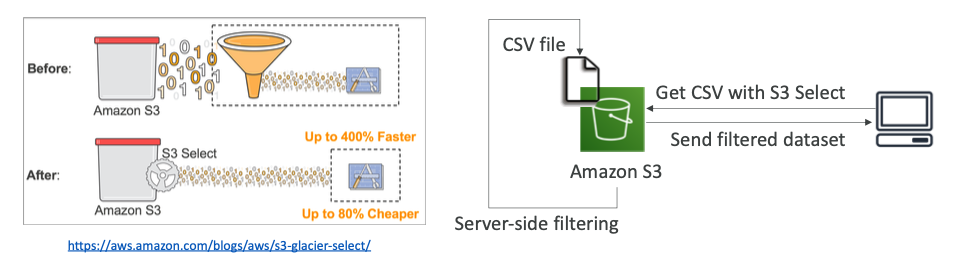
S3 Select & Glacier Select
- 서버 측 필터링을 수행하면 SQL을 사용하여 더 적은 데이터를 검색할 수 있다.
- 행 또는 열을 기준으로 필터를 할 수 있다. (단순 SQL 문)
- 네트워크로 전성되는 데이터의 양을 줄이고, 클라이언트의 CPU 사용률을 줄일 수 있다.
S3 Event Notifications
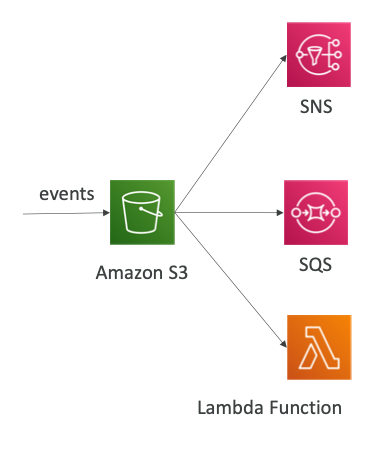
S3:ObjectCreated,S3:ObjectRemoved,S3:ObjectRestore,S3:replication...- 객체명에 필터링을 할 수 있다. (*.jpg)
- 사용 사례: S3에 업로드된 이미지의 썸네일 생성
- “S3 Event”의 경우 원하는 수 만큼 생성할 수 있다.
- “S3 Event Noticiation”은 일반적으로 몇 초 안에 이벤트를 전달하지만 때로는 1분 이상 걸릴 수 있다.
- 버전이 지정되지 않는 단일 객체에 동시에 두 번 쓰는 경우 단일 이벤트 알림만 전송될 수 있다.
- 쓰기에 성공할 때마다 이벤트 알림이 전송되도록 하려면 버킷에서 버전 관리를 활성화할 수 있다.
S3 - Requester Pays(요청자 지불)

- 일반적으로 버킷 소유자는 버킷과 관련된 스토리지 및 데이터 전송 비용을 모두 지불해야 한다.
- “요청자 지불”버킷을 사용하면 버킷 소유자 대신 요청자가 요청 비용과 버킷에서 데이터 다운로드 비용을 지불한다.
- 다른 계정과 대용량 데이터 세트를 공유하려는 경우에 유용하다.
- 요청자는 AWS에서 인증되어야 하며 익명일 수 없다.
Amazon Athena
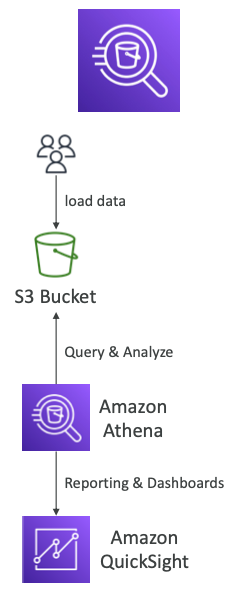
- S3 객체에 대한 분석을 수행하는 서버리스 쿼리 서비스다.
- 표준 SQL 언어를 사용하여 파일을 쿼리한다.
- CSV, JSON ORC, Avro 및 Presto 기반의 Parquet을 지원한다.
- 가격: 스캔된 데이터 TB당 $5.00
- 비용 절감을 위해 압축하거나 열 형식의 데이터를 사용하여 스캔 횟수를 감소시킬 수 있다.
- 사용 사례: Business Intelligence/Analytics/Reporting, analyze & query VPC Flow Logs, ELB Logs, CloudTrail 추적 등을 분석 및 쿼리한다.
- 서버리스 SQL을 사용하여 S3를 분석할 때는 "Amazon Athena"를 사용하는 것을 기억한다.
Glacier Vault Lock

- WORM(Write Once Read Many) 모델에 적용한다.
- 미래에 수정을 위해 잠금 정책을 사용하여 더 이상 변경할 수 없도록 한다.
- 규정 준수 및 데이터 보존에 유용하게 사용된다.
S3 Object Lock
- 버전관리가 활성화되어 있어야 한다.
- WORK(Write Once Read Many) 모델에 적용한다.
- 지정된 시간동안 객체의 버전 삭제를 차단한다.
- 객체 보존
- Retention Period: 고정 기간을 명시한다.
- Legal Hold: 동일하게 객체를 보호하며, 만료 날짜가 없다.
- 모드
- Govenance mode: 사용자는 특별한 권한이 없는 한 객체 버전을 덮어쓰거나 삭제할 수 없으며 잠금을 변경할 수 없다.
- Compliance mode: AWS 계정의 루트 사용자를 포함하여 어떤 사용자도 보호 객체 버전을 덮어쓰거나 삭제할 수 없다. 객체가 “Compliance Mode”에서 잠겨 있으면 보존 모드를 변경할 수 없으며 보존 기간을 단축할 수 없다.
참고 자료
'[IT] Infrastructure > Certificate' 카테고리의 다른 글
| [AWS] Application Integration Services (0) | 2023.03.19 |
|---|---|
| [AWS] Analysis Services (0) | 2023.03.19 |
| [SAA] S3 Introduction (0) | 2022.11.20 |
| [SAA] Classic Solutions Architecture (0) | 2022.11.16 |
| [SAA] Discussions - MyWordPress.com (0) | 2022.11.16 |



