Data Engineering
- 이번 장에서는 Solutions Architect Professional (SAP) 을 준비하며 "데이터 엔지니어링"에 대해서 알아보도록 한다.
AWS Kinesis
- Kinesis는 관리형 "데이터 스트리밍" 서비스다.
- 애플리케이션 로그, 메트릭 수집, IoT 데이터 수집, 클릭 스트림 처리에 적합하다.
- "실시간" 빅데이터 처리에 적합하다.
- 스트리밍 처리 프레임워크(Spark, NiFi)에 적합하다.
- 데이터가 세 개의 가용지역에 동기식으로 자동으로 복제된다.
- Kinesis Streams: 대규모로 낮은 지연 시간의 스트리밍 수집
- Kinesis Analytics: SQL을 사용하여 스트림에 대한 실시간 분석 수행
- Kinesis Firehose: 스트림을 S3, Redshift, Elastic Search & Splunk로 적재

- "Kinesis Streams"는 클릭 스트림, IoT, 메트릭, 로그 등을 수집한다.
- 수집되는 데이터는 "Kinesis Analytics"를 통해서 분석을 수행할 수 있다.
- 분석된 데이터를 "Kinesis Firehose"로 보내고 S3 버킷 또는 Redshift에 저장할 수 있다.
Kinesis Streams
- 스트림은 순서에 따라 샤드/파티션으로 나뉜다.

- 기본적으로 데이터 보존 시간은 24시간이며, 최대 365일 저장할 수 있다.
- 데이터 재처리/재생 기능을 제공한다.
- 여러 애플리케이션이 동일한 스트림을 소비할 수 있다.
- 처리량 확장을 통한 실시간 처리가 가능하다.
- Kinesis에 데이터가 삽입되면 삭제할 수 없기 때문에 불변성을 보장한다.
Kinesis Streams Shard
- 용량에 대한 두 가지 모드가 있다.
- On-Demand: 용량 계획이 없고, Kinesis에서 샤드를 자동으로 확장한다.
- Provisioned: 시간이 지남에 따라 샤드를 관리할 수 있다.
- 순차적으로 메시지를 보내거나, 배치로 메시지를 보낼 수 있다.
- 샤드는 시간이 흐르면서 진화할 수 있다. (reshard / merge)
- 샤드별로 레코드를 정렬한다.

Producer & Consumer
- Producer
- AWS SDK: 단순한 프로듀서다.
- Kinesis Producer Library(KPK): C++과 Java와 호환되며 배치, 압축, 재시도를 지원한다.
- Kinesis Agent:
- 로그 파일을 모니터링하여 Kinesis로 직접 전송한다.
- Kinesis Data Streams와 Kinesis Data Firehose에 쓸 수 있다.
- Consumer
- AWS SDK: 단순한 컨슈머다.
- Lambda: Event Source Mapping을 통해서 연동될 수 있다.
- KCL: 체크포인트와 병렬 읽기를 지원한다.
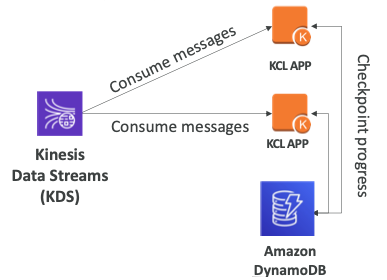
- KDS의 메시지를 KCL APP에서 소비하고 있다.
- KCL 애플리케이션은 온프레미스 서비스일 수도 EC2 인스턴스일 수도 있다.
- DynamoDB에서 하는 작업의 진행을 체크포인트로 확인할 수 있다.
- 또 다른 KCL APP에서 병렬로 진행되는 작업이 DynamoDB 체크포인트로 보내진다.
Limit
- Producer
- 샤드 하나당 1mb/s 또는 1,000/s 제한이 있다.
- 처리량을 늘리기 위해서는 샤드를 추가해야 한다.
- 만약 제한을 초과하는 경우
ProvisionedThroughputException이 발생한다.
- Consumer Classic
- 모든 소비자가 샤드 하나당 2mb/s 제한이 있다.
- 모든 소비자는 샤드 하나당 초당 5개의 API 호출을 받을 수 있다.
- 소비자가 5이라면 모두 한정된 처리량을 읽을 수 있다.
- Consumer Enhanced Fan-Out
- 향상된 소비자 하나 당, 샤드 하나 당 2mb/s 제한이 있다.
- 푸시 모델이기 때문에 API 호출이 필요하지 않다.
- Data Retention
- 기본적으로 24시간동안 데이터를 보존한다.
- 최대 보존 기간을 365일까지 늘릴 수 있다.
Kinesis Data Firehose
- 여러 생산자로부터 데이터를 취합하는 데 사용된다.
- 수많은 종류의 생산자를 사용할 수 있다.
- 애플리케이션, 클라이언트, SDK, Kineiss Agent, Kinesis Data Streams, Amazon CloudWatch, AWS IoT
- Kinesis Data Firehose는 선택적으로 데이터를 변환할 수 있다.
- 변환된 데이터를 원하는 목적지로 전달할 수 있다.
- 써드파티 목적지로는 "Datadog", "Splunk", "New Relic", "mongoDB"가 있다.
- AWS 서비스 목적지로는 "S3", "Redshift", "OpenSearch"가 있다.
- HTTP 엔드포인트로 사용자 지정 목적지를 설정할 수 있다.

- 완전 관리 서비스로 사용자가 관리할 서버가 없으며 자동으로 확장한다.
- Firehose를 통과하는 데이터에 대해서만 비용을 지불한다.
- "거의(Near)" 실시간으로 작동한다.
- 전체 배치가 아니라면 최소 60초 지연된다.
- 한 번에 최소 1MB의 데이터를 제공한다.
- 다양한 데이터 형식, 변환, 변형, 압축을 지원한다.
- AWS 람다를 사용한 맞춤형 데이터 변환을 지원한다.
- 실패한 데이터 또는 모든 데이터를 백업용 S3 버킷으로 전송할 수 있다.
Delivery Diagram

- Firehose가 있고 Source로부터 데이터 스트림을 읽어온다.
- 람다 함수를 통해서 데이터를 변환한다.
- 예를 들어, JSON 형식의 데이터를 CSV 형식으로 변환할 수 있다.
- S3 버킷으로 데이터를 출력하고 출력된 데이터는 Redshift로 복사된다.
- 기록, 변환에 실패한 데이터, 전송에 실패한 데이터는 다른 S3 버킷에 저장할 수 있다.
Buffer Sizing
- Firehose는 버퍼에 기록을 축적한다.
- 버퍼가 시간 및 크기 규칙에 따라 플러시된다.
- 버퍼 크기 (예: 32MB): 해당 버퍼 크기에 도달하면 플러시된다.
- 버퍼 시간 (예: 1분): 해당 시간에 도달하면 플러시된다.
- 자동으로 버퍼 크기를 늘려 처리량을 늘릴 수 있다.
- 전송되는 데이터의 양이 많다면 버퍼의 크기 때문에 플러시가 발생한다.
- 전송되는 데이터의 양이 적다면 버퍼의 시간 때문에 플러시가 발생한다.
- Kinesis Data Streams에서 S3까지 실시간 플러시가 필요한 경우 람다를 사용해야 한다.
Kinesis Data Streams vs Kinesis Data Firehose
- Kinesis Data Streams
- 규모에 맞게 소비할 수 있는 스트리밍 서비스다.
- 사용자 정의 코드를 작성한다. (생산자/소비자)
- 실시간으로 동작한다. (~200ms)
- 샤드 분할과 병합을 차트화하여 규모와 처리량을 늘린다.
- 1 ~ 365일간의 데이터를 저장한다.
- 여러 소비자가 동일한 데이터를 소비할 수 있고 데이터를 재실행하는 기능을 지원한다.
- Kinesis Data Firehose
- 스트리밍 데이터를 S3/Redshift/OpenSearch/써드파티/사용자 지정 HTTP로 전달한다.
- AWS에 의해 완전 관리된다.
- 거의 실시간으로 작동한다. (버퍼 시간 또는 버퍼 크기)
- 자동으로 확장한다.
- 데이터를 저장하는 기능을 제공하지 않는다.
- 데이터를 재실행하는 기능을 지원하지 않는다.
Kinesis Data Analytics
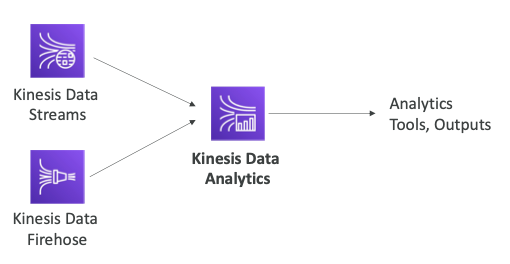
- Kinesis Data Stream가 있고 전송되는 스트림에서 연산이 필요한 로직이 있다.
- Kinesis Data Analytics이 스트림에서 나오는 데이터를 분석한다.
- 결과물은 다른 분석 도구나 대시보드 등으로 전달될 수 있다.
- Kinesis Data Analytics는 Kinesis Data Firehose에서 데이터를 읽어올 수 있다.

- 중앙에 Kinesis Data Analytics가 있고 총 세개의 입력 스트림이 있다.
- 참조 데이터나 참조 테이블을 추가할 수 있는 옵션이 있다.
- 입력 스트림과, 참조 테이블을 이용하면 SQL 쿼리를 생성할 수 있다.
- 쿼리의 결과로 출력 스트림을 생성한다.
- 출력 스트림은 Kinesis Data Streams와 Kinesis Data Firehose에 의해 소비된다.
사용 사례
- 스트리밍 ETL: 열 선택, 스트리밍 데이터에 대한 간단한 변환한다.
- 연속성 메트릭 생성: 모바일 게임용 라이브 리더보드를 생성한다.
- 반응형 분석: 특정 기준을 찾아 경고(필터링)를 구축한다.
기능
- 소모된 리소스에 대해서만 비용을 지불한다.
- 가격이 저렴하지 않다.
- 서버리스로 자동으로 확장된다.
- IAM 권한을 사용하여 스트리밍 소스 및 대상에 대한 액세스를 제한할 수 있다.
- SQL 또는 Flink를 사용하여 계산을 작성한다.
- 스키마 검색을 지원한다.
- 람다를 전처리 용도로 사용할 수 있다.
Streaming Architecture
실시간 전송 계층
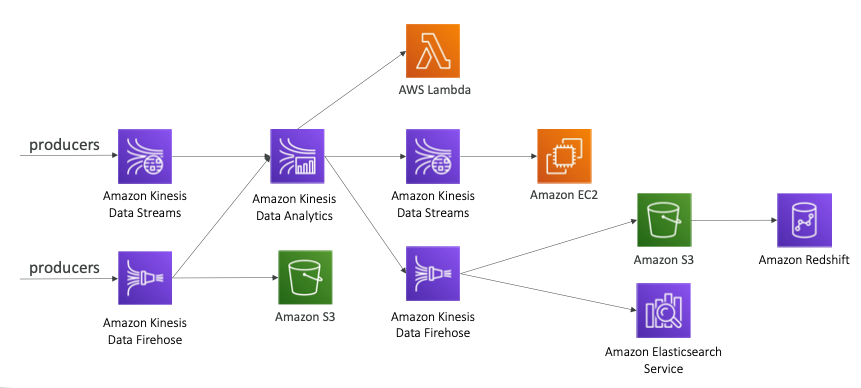
- 데이터 생산자들이 데이터 스트림을 생산하여 Kinesis Data Streams로 전달할 수 있다.
- 실시간 데이터 분석을 위해서 Kinesis Data Analytics를 생성할 수 있다.
- 람다 함수를 통해서 데이터 분석이나 변환을 할 수 있다.
- 처리된 데이터를 Kinesis Data Streams에서 다시 소비하여 EC2 인스턴스로 전달할 수 있다.
- 또는 S3나 Elasticsearch 서비스로 데이터를 전송하고 Redshift에 데이터를 저장할 수 있다.
- Kinesis Data Firehose로 전송된 데이터를 S3 버킷에 바로 저장할 수 있다.
초당 1KB 크기의 메시지 3,000개 처리
- 두 아키텍처는 모드 정상적으로 작동한다.
- Kinesis를 사용하는 경우 초당 3MB를 처리하기 위해서 총 세 개의 샤드가 필요하다.
- 3 * $0.015/hr = $32.4/month
- 단, 결과를 S3에 저장하려면 반드시 Kinesis Data Firehose를 사용해야 한다.
- DynamoDB + Stream을 사용하는 경우 초당 3MB를 처리하기 위해서 3,000 WCU 용량 유닛을 작성해야 한다.
- $1,450.90/month
- DynamoDB를 사용하기 때문에 데이터를 장기간 저장할 수 있다.
비교 차트

- Kinesis Data Streams
- 데이터가 불변이기 때문에 한 번 삽입하면 바꿀 수 없다.
- 최대 1년까지 저장할 수 있다.
- 샤드 당 정렬된다.
- 소비자는 EC2, 람다, KDF, KDA, KCL 중에 선택할 수 있다.
- KDS를 사용하는 경우 200ms의 지연 시간이 있으며, KDF를 사용하는 경우 1분의 지연 시간이 있다.
- SQS
- 데이터가 불변이기 때문에 한 번 삽입하면 바꿀 수 없다.
- 데이터 저장 기간은 1 ~ 14일이다.
- SQS Standard에 대한 정렬은 지원하지 않는다.
- 소프트 제한이 있지만 필요한 경우 늘릴 수 있다.
- 소비자는 EC2, 람다 중 선택할 수 있다.
- 10 ~ 100ms의 짧은 지연 시간이 발생한다.
- SQS FIFO
- 데이터가 불변이기 때문에 한 번 삽입하면 바꿀 수 없다.
- 데이터 저장 기간은 1 ~ 14일이다.
- 그룹 ID당 정렬이 이루어진다.
- 배치를 사용하지 않으면 초당 300개, 배치를 사용하는 경우 초당 3,000개의 메시지 처리를 지원한다.
- 소비자는 EC2, 람다 중 선택할 수 있다.
- 10 ~ 100ms의 짧은 지연 시간이 발생한다.
- SNS
- 데이터가 불변이기 때문에 한 번 삽입하면 바꿀 수 없다.
- 데이터를 저장하는 기능을 제공하지 않는다.
- 정렬 기능을 제공하지 않는다.
- 소프트 제한이 있다.
- 소비자는 EC2, 람다, 이메일, SQS 등이 될 수 있다.
- 10 ~ 100ms의 짧은 지연 시간이 발생한다.
- DynamoDB
- 데이터가 가변이다.
- 데이터는 무기한 저장할 수 있으며 TTL을 통해서 수명을 지정할 수 있다.
- 정렬 기능을 제공하지 않는다.
- 확장성을 위해서 WCU, RCU를 이용해 데이터베이스를 생성하고 프로비전해야 한다.
- 소비자는 DynamoDB 스트림이 될 수 있다.
- 10 ~ 100ms의 짧은 지연 시간이 발생한다.
- S3
- 데이터가 가변이다.
- 데이터는 무기한 저장할 수 있으며 수명 주기 정책을 설정할 수 있다.
- 정렬 기능을 제공하지 않는다.
- 접두사 당 3,500개의 PUT 요청과 5,500개의 GET 요청으로 제한된다.
- 소비자는 SDK, S3 이벤트가 될 수 있다.
- 10 ~ 100ms의 짧은 지연 시간이 발생한다.
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
- Amazon Kinesis를 대신할 수 있는 서비스다.
- AWS에서 완벽하게 관리되는 Apache Kafka다.
- 클러스터를 생성, 업데이트, 삭제할 수 있다.
- MSK는 사용자를 위해 Kafka 브로커 노드 및 Zookeeper 노드를 생성 및 관리한다.
- MSK 클러스터를 VPC, 다중 AZ(최대 3개)에 구축할 수 있다.
- 일반적인 Apache Kafka 장애에서 자동으로 복구된다.
- 원하는 시간 동안 EBS 볼륨에 데이터가 저장된다.
- MSK 서버리스
- 용량을 관리하지 않고 MSK에서 Apache Kafka를 실행한다.
- MSK는 자동으로 리소스를 프로비저닝하고 컴퓨팅 및 스토리지를 확장한다.
Apache Kafka High Level

- 카프카 클러스터는 여러 브로커로 구성되어 있다.
- 데이터를 생산하는 생산자는 브로커 토픽으로 데이터를 전송한다.
- 생산자는 Kinesis, IoT, RDS 등이 될 수 있다.
- 하나의 브로커로 전달된 데이터는 다른 브로커들로 복제된다.
- 여러 종류의 서비스들이 소비자가 될 수 있으며 토픽에서 데이터를 폴링한다.
- 소비자는 EMR, S3, SageMaker, Kinesis, RDS 등이 될 수 있다.
Kinesis Data Streams vs Amazon MSK
- Kinesis Data Streams
- 1MB 메시지 크기 제한이 있다.
- 샤드가 있는 데이터 스트림이다.
- 샤드 분할 및 병합이 가능하다.
- TLS를 통해 전송 중 암호화를 제공한다.
- KMS를 통해 저장되는 데이터를 암호화할 수 있다.
- Amazon MSK
- 기본적으로 1MB 메시지 크기 제한이 있으며 더 큰 값으로 변경할 수 있다.
- 카프카 토픽에는 파티션이 있다.
- 토픽에 파티션을 추가할 수 있으며 제거는 할 수 없다.
- PLAINTEXT 또는 전송 중 암호화를 제공한다.
- KMS를 통해 저장되는 데이터를 암호화할 수 있다.
MSK Consumer
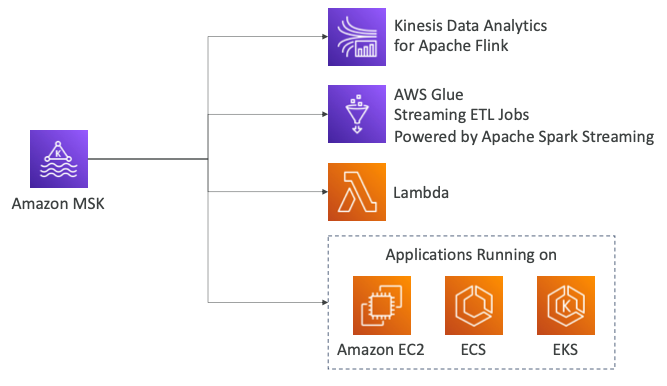
- MSK의 데이터를 소비하는 여러가지 방법이 있다.
- Kinesis Data Analytics for Apache Flink를 사용하여 Flink 애플리케이션이 메시지를 소비하도록 할 수 있다.
- ETL를 위해서 AWS Glue를 사용할 수 있다.
- 람다 함수를 사용하여 메시지를 소비할 수 있다.
- EC2, ECS, EKS에서 실행되는 애플리케이션에서 메시지를 소비할 수 있다.
AWS Batch
- 도커 이미지로 배치 작업을 실행한다.
- 실행할 수 있는 두 가지 옵션이 있다.
- AWS Fargate 에서 실행
- VPC의 인스턴스(EC2 및 스팟 인스턴스)에서 동적 프로비저닝을 통한 실행
- 배치 작업의 요구 사항의 볼륨에 따라 최적의 양을 선택할 수 있다.
- 클러스터를 관리할 필요가 없고 서버리스로 작동한다.
- 사용되는 기본 리소스에 대한 비용만 지불하면 된다.
- 이미지 배치 프로세스, 수천 개의 동시 작업 실행 등에 사용된다.
- Amazon EventBridge를 사용하여 배치 작업을 예약한다.
- AWS Step Function을 사용하여 배치 작업을 오케스트레이션한다.

- S3 이미지를 썸네일로 만드는 작업의 아키텍처를 구성해본다.
- AWS Batch에서 배치 작업을 생성하면 ECS에 의해 관리된다.
- 스팟 인스턴스 또는 Spot Instance(Spot Fleet), Fargate를 사용할 수 있다.
- S3에 파일이 업로드되면 업로드 이벤트가 람다 또는 EventBridge로 전달된다.
- 람다 함수는 AWS SDK를 이용해 배치 작업을 시작하기 위한 API를 호출할 수 있다.
- EventBridge는 ECS와 직접 연계되어 배치 작업을 트리거할 수 있다.
- 배치 작업이 실행되기 위해 ECR에서 도커 이미지를 실행한다.
- 배치 작업은 S3 API를 호출하여 파일을 검색할 수 있다.
- S3 API를 호출할 수 있도록 배치 작업이 올바른 IAM 역할을 갖도록 구성해야 한다.
- 썸네일 또는 이미지 파일의 메타데이터를 DynamoDB에 저장할 수 있다.
Batch vs Lambda
- Lambda
- 시간 제한이 있다.
- 런타임이 제한되어 있어 기본 제공 런타임에 엑세스하거나 AWS 람다만을 위해 빌드된 도커 이미지를 사용할 수 있다.
- 한정된 임시 디스크 공간을 사용할 수 있다.
- 서버리스로 작동한다.
- Batch
- 시간 제한이 없다.
- 도커 이미지로 패키지화된 모든 런타임을 지원한다.
- 디스크 공간을 EBS/Instance Store에 의존한다.
- EC2 또는 Fargate에 의존한다.
Compute Environment
- Managed Compute Environment
- AWS Batch를 통해 환경 내에서 용량 및 인스턴스 유형을 관리한다.
- EC2 온디맨드 또는 스팟 인스턴스를 선택할 수 있다.
- 온디맨드 Fargate 또는 스팟 인스턴스 Fargate를 선택할 수 있다.
- 스팟 인스턴스에 대한 최대 가격을 설정할 수 있다.
- 자체 VPC 내에서 실행할 수 있다.
- Private 서브넷 내에서 시작하는 경우 해당 서브넷이 ECS 서비스에 액세스할 수 있는지 확인이 필요하다.
- NAT 게이트웨이/인스턴스를 사용하거나 ECS용 VPC 엔드포인트를 사용할 수 있다.
- Unmanaged Compute Environment
- EC2 인스턴스 구성, 프로비저닝 및 확장을 제어 및 관리할 수 있다.
Managed Compute Environment
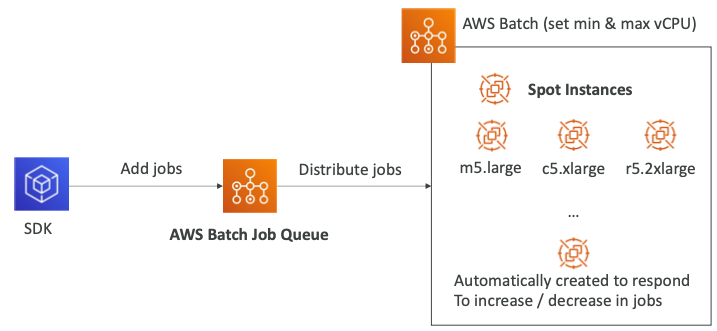
- 배치 작업이 있고 컴퓨팅 환경에서 최소 혹은 최대 vCPU를 얼마를 사용할지 설정한다.
- 예를 들어, 스팟 인스턴스 m5.large, c5.xlarge, r5.2xlarge를 설정할 수 있다.
- 실행되는 인스턴스의 유형은 중요하지 않으며 중요한 것은 vCPU를 얼마나 설정했는가 이다.
- "AWS Batch Job Queue"를 통해서 작업을 EC2 인스턴스로 분산시킨다.
- AWS 배치에 작업을 보내려면 SDK를 이용해 작업 큐에 작업을 추가해야 한다.
- 이러한 작업은 람다나 CloudWatch Events 또는 Step Function으로 할 수 있다.
- 배치 작업 큐에 작업이 많을 경우 자동 스케일링을 설정할 수 있다.
- 관리되는 컴퓨팅 인스턴스를 통해 자동적으로 새로운 스팟 인스턴스나 온디맨드 인스턴스를 생성해 작업 증가 또는 감소에 대응할 수 있다.
Multi Node Mode
- Multi Node: 대규모, HPC(고성능 컴퓨팅)에 적합하다.
- 여러 EC2/ECS 인스턴스를 동시에 활용할 수 있다.
- 긴밀하게 연결된 워크로드에 적합하다.
- 단일 작업을 나타내며 작업에 대해 생성할 노드의 수를 지정한다.
- 1개의 메인 노드와 많은 자식 노드를 생성할 수 있다.
- 스팟 인스턴스와 함께 사용할 수 없다.
- EC2 시작 모드가 배치 그룹 "클러스터"인 경우 더욱 효과적이다.

Amazon EMR
- EMR은 "Elastic MapReduce"의 약자다.
- EMR을 통해 하둡 클러스터를 생성하여 방대한 양의 데이터를 분석 및 처리할 수 있다.
- 클러스터는 수백 개의 EC2 인스턴스로 구성될 수 있다.
- Apache Spark, HBase, Presto, Flink 등을 지원한다.
- EMR은 EC2의 모든 프로비저닝 및 구성을 처리한다.
- CloudWatch를 통한 자동 확장을 지원한다.
- 데이터 처리, 머신러닝, 웹 인덱싱, 빅데이터 처리 등의 작업에 사용된다.
Integration
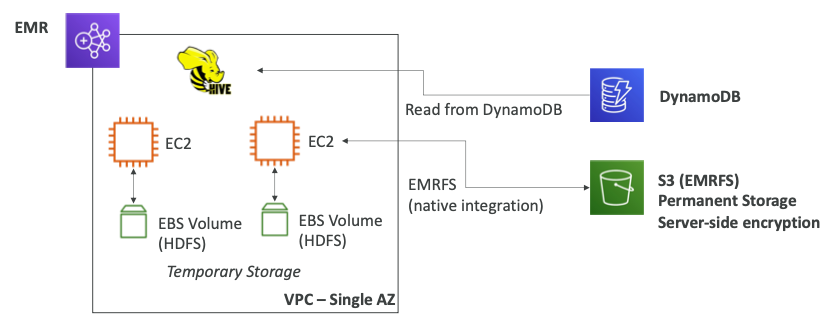
- EMR은 VPC 내에서 실행되고 단일 가용지역에 있다.
- 여러 개의 EC2 인스턴스와 EBS 볼륨이 있으며 EBS 볼륨은 Hadoop의 분산파일 시스템인 HDFS를 실행한다.
- 클러스터의 EC2 인스턴스를 위한 임시 저장소를 제공한다.
- 만약 데이터를 임시 저장소가 아니라 장기간 저장하고 싶다면 EMRFS를 사용해야 한다.
- S3와 네이티브가 통합되며 S3는 다중 AZ이므로 내구성이 더 강한 유형의 저장소다.
- 영구적으로 데이터를 저장할 수 있으며 서버 쪽 암호화도 정의할 수 있다.
- DynamoDB 테이블을 분석하고 싶다면 Hive를 이용하여 EMR을 사용할 수 있다.
노드 유형 & 구매
- 마스터 노드 (Master Node): 클러스터 관리, 조정, 상태 관리를 하며 장기간 실행되어야 한다.
- 코어 노드 (Core Node): 태스크 실행 및 데이터 저장에 사용되며 장기간 실행되어야 한다.
- 작업 노드 (Task Node, 선택사항): 작업만 실행하며 일반적으로 스팟 인스턴스에서 실행된다.
- 구매 옵션
- On-Demand: 안정적이고 예측 가능하며 종료되지 않는다.
- Reserved: 비용 절감 (사용 가능한 경우 EMR이 자동으로 사용)
- Spot Instance: 더 저렴하고, 종료될 수 있으며 신뢰성이 낮다.
- 장기간 실행되는 클러스터 또는 일시적(임시) 클러스터를 가질 수 있다.
Instance Configuration
- Uniform instance groups: 단일 인스턴스 유형 선택 및 각 노드에 대한 구매 옵션을 제공한다. (자동 확장 가능)
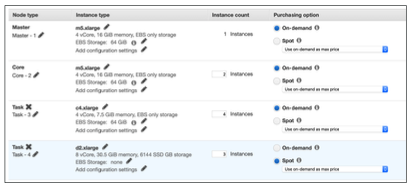
- Instance fleet: 대상 용량 선택, 인스턴스 유형 및 구매 옵션 혼합할 수 있다. (자동 확장 불가)

Running Jobs on AWS

- Strategy1: 장기 실행 작업을 위해 EC2 인스턴스를 프로비저닝하여 Cron job을 실행한다.
- Cron job을 사용할 수 있는 엔지니어에게는 좋은 기능이지만 고가용성을 보장하지 않는다.
- Strategy2: EventBridge와 람다를 조합하여 매시간마다 함수를 호출하도록 구현한다.
- 완전하게 서버리스로 작동한다.
- 람다에서 실행시킬 수 있는 런타임 제한과 람다의 타임아웃 시간을 계산해야 한다.
- Strategy3: 반응형 워크플로로 AWS 내에서 발생하는 이벤트가 람다 함수를 호출하도록 구현한다.
- 이벤트들은 EventBridge, S3 이벤트, API 게이트웨이, SQS, SNS 등이 될 수 있다.
- Strategy4: EventBridge가 일정 시간마다 AWS Batch를 실행하도록 구축할 수 있다.
- Strategy5: EventBridge가 일정 시간마다 Fargate를 실행하도록 구현할 수 있다.
- AWS Batch보다는 적은 기능을 제공하지만 확장성을 제공한다.
- Strategy6: EMR을 사용하여 단계별로 실행할 수 있다.
- 빅데이터 작업을 클러스터링할 때 유용하게 사용될 수 있다.
AWS Glue
- 추출(Extract), 변형(Transform), 적재(Load) 즉, ETL을 담당하는 서비스다.
- 분석을 위한 데이터 준비 및 변환에 유용하게 사용된다.
- 완전환 서버리스 서비스다.

- S3 버킷이나 RDS에서 Glue를 사용하여 데이터를 추출할 수 있다.
- Glue에서 데이터를 변환하여 목적지인 Redshift에 적재하도록 구축할 수 있다.
Data Catalog

- Glue 데이터 카탈로그는 데이터셋의 카탈로그다.
- S3, RDS, DynamoDB, JDBC 호환 DB를 사용하면 크롤러가 데이터베이스를 보고 모든 테이블을 찾아 AWS 데이터 카탈로그에 메타데이터를 작성한다.
- 데이터 카탈로그 설정이 완료되면 Glue Jobs (ETL)이 테이블들을 찾아서 필요한 데이터를 가져온다.
- "Amazon Athena", "Amazon Redshift Spectrum", "Amazon EMR"과 같은 서비스들이 Glue 데이터 카탈로그에 의존하고 있다.
Redshift
- Redshift는 PostgreSQL을 기반으로 하지만 OLTP에는 사용되지 않는다.
- OLAP(Online Analytical Processing, 온라인 분석 처리)로 분석 및 데이터 웨어하우징으로 사용된다.
- 다른 데이터 웨어하우스보다 10배 뛰어난 성능, PB 단위의 데이터로 확장된다.
- 행(row) 기반이 아니라 데이터의 컬럼 스토리지다.
- 대규모로 병렬 쿼리를 실행한다. (MPP, Massive Parallel Query Execution)
- 프로비저닝된 인스턴스를 기반으로 진행할 때 지불한다.
- 쿼리를 수행하기 위한 SQL 인터페이스가 있다.
- AWS Quicksight 또는 Tableau와 같은 BI 툴과 통합될 수 있다.
- 데이터는 S3, Kinesis Firehose, DynamoDB, DMS 등에서 로드된다.
- 노드 유형에 따라 최대 100개 이상의 노드, 노드당 최대 16TB의 공간을 제공한다.
- 일부 클러스터에 대해서만 Multi-AZ를 사용하여 여러 노드 프로비저닝이 가능하다.
- Leader node: 쿼리 계획, 결과 집계를 담당한다.
- Compute node: 쿼리를 수행하기 위해 결과를 Leader에게 보낸다.
- 백업, 복구, VPC 보안, IAM, KMS, 모니터링을 제공한다.
- Redshift Enhanced VPC Routing: Copy/Unload가 VPC를 통과한다.
- Redshift는 프로비저닝되므로 지속적으로 사용되는 경우에 사용할만한 가치가 있다.
- 간헐적으로 질의하는 경우에는 Athena를 사용하는 것이 좋다.
Snapshots & DR
- 스냅샷은 클러스터의 시점별 백업으로, 내부적으로 S3에 저장된다.
- 스냅샷은 증분되므로 변경된 내용만 반영된다.
- 스냅샷을 통해서 새로운 클러스터로 복원할 수 있다.
- 자동화하여 "8시간마다", "5GB마다", "일정마다"와 같은 규칙에 따라 스냅샷을 생성할 수 있다.
- 스냅샷의 저장 기간을 설정하여 원하는 기간동안 스냅샷을 유지하고 기간이 지나면 자동으로 삭제되도록 할 수 있다.
- 수동으로 스냅샷을 생성하는 경우 스냅샷을 삭제할 때까지 유지된다.
- 클러스터의 스냅샷(자동 또는 수동)을 다른 AWS 리전에 자동으로 복사하도록 Amazon Redshift를 구성할 수 있다.

- 복제를 위한 소스가 있고 복제가 이루어질 목적지가 있다.
- 스냅샷은 소스 영역에서 KMS를 통해 암호화되어 있다.
- 스냅샷을 복제하기 위해서 스냅샷 암호화를 해제하기 위한 KMS 키를 먼저 복제해야 한다.
- 이후 암호화된 Redshift 스냅샷을 목적지로 복제한다.
Spectrum
- Spectrum을 사용하면 S3의 데이터를 Redshift에 로딩하지 않고 쿼리할 수 있다.
- 쿼리를 실행하려면 Redshift 클러스터가 있어야 한다.
- 쿼리가 수천 개의 Redshift Spectrum 노드에 전송된다.

- Redshift 클러스터가 있고 Leader 노드와 Compute 노드들이 있다.
- 데이터에 대한 쿼리를 수행하면 Redshift가 다수의 Redshift 스펙트럼 노드를 실행하여 S3 데이터셋의 쿼리를 수행한다.
- 결과가 있으면 집계를 위해 Compute 노드로 돌아가고, Leader 노드로 반환한다.
Workload Management (WLM)
- 워크로드 내에서 쿼리의 우선순위를 유연하게 관리할 수 있도록 지원한다.
- 예를 들어, 짧은 시간에 빠르게 실행되는 쿼리가 오래 실행되는 쿼리에 의해 블로킹되지 않도록 한다.
- 여러 쿼리 대기열을 정의한다. (Superuser 큐, 사용자 정의 큐)
- 런타임에 쿼리를 해당 큐로 라우팅한다.
- 자동 WLM: 대기열 및 리소스를 Redshift로 관리한다.
- 수동 WLM: 큐와 리소스를 사용자가 직접 관리한다.
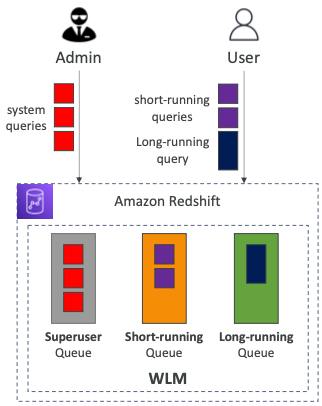
- 관리자와 사용자가 있다.
- 관리자는 쿼리가 가능한 빨리 끝나기를 바라기 때문에 시스템 쿼리를 실행시키고 해당 쿼리는 "Superuser 큐"로 이동한다.
- 사용자는 짧게 실행되는 쿼리와 오래 실행되는 쿼리를 질의한다.
- 짧게 실행되는 쿼리는 "Short-running 큐"로 이동한다.
- 오래 실행되는 쿼리는 "Long-running 큐"로 이동한다.
Currency Scaling
- 사실상 무제한의 동시 사용자 및 쿼리로 일관성 있게 빠른 성능을 제공한다.
- Redshift를 사용하면 자동으로 추가 클러스터 용량(Concurrency-Scaling Cluster)을 추가하여 요청 증가를 처리할 수 있다.
- WLM을 사용하여 동시 확장 클러스터로 전송된 쿼리를 결정하는 기능을 제공한다.
- 초당 요금이 부과된다.

- 일정 수준의 사용자가 질의하는 경우 클러스터가 일정 수준의 노드를 유지한다.
- 만약 더 많은 사용자가 질의하는 경우 일관성 있게 빠른 성능을 유지하기 위하여 "Concurrency-Scaling" 클러스터가 노드를 추가로 증설한다.
- 어떤 쿼리가 "Concurrency-Scaling" 클러스터로 보내질지 WLM 기능을 통해서 결정할 수 있다.
DocumentDB
- 오로라는 PostgreSQL, MySQL의 AWS 구현체다.
- DocumentDB는 NoSQL 데이터베이스로 MongoDB의 규현체다.
- MongoDB를 사용하여 JSON 데이터를 저장, 조회 및 인덱싱한다.
- 오로라와 배포 개념이 유사하다.
- 완벽하게 관리되며 3개의 가용영역에 걸쳐 복제된다.
- 스토리지가 10GB 단위로 자동 증가한다.
- 초당 수백만 건의 요청으로 워크로드에 맞춰 자동으로 확장된다.
Pricing
- 초기 비용 없이 사용한만큼 비용을 지불한다.

- 온디멘드 인스턴스의 경우 초당 비용을 계산하며 최소 사용량은 10분이다.
- 데이터베이스 I/O에 대한 비용을 지불해야 하며 백만 I/Os당 비용을 지불한다.
- 저장되는 데이터의 경우 GB당 매달 비용을 지불해야 한다.
- 내부적으로 S3에 백업되며 GB당 매달 비용을 지불해야 한다.
Amazon Timestream
- 완벽하게 관리되고, 빠르고, 확장성이 뛰어나며, 서버리스로 작동하는 시계열 데이터베이스다.
- 용량 조정을 위해 자동으로 확장되거나 축소된다.
- 하루에 수조 개의 이벤트를 저장 및 분석한다.

- 관계형 데이터베이스보다 1/10의 저렴한 비용으로 1,000배 빠른 속도를 제공한다.
- 쿼리를 스케줄링할 수 있고, 다양한 측정으로 기록할 수 있고 SQL과 완벽한 호환성을 제공한다.
- 최근 데이터는 메모리에 저장되고 오래된 데이터는 비용 최적화 스토리지 계층에 저장된다.
- 시간 시리즈 분석 기능으로 데이터 분석과 거의 실시간으로 패턴을 찾을 수 있다.
- 전송되는 데이터와 저장되는 데이터를 암호화하는 기능을 지원한다.
- IoT 애플리케이션, 운영 애플리케이션의 실시간 분석 등에 사용된다.
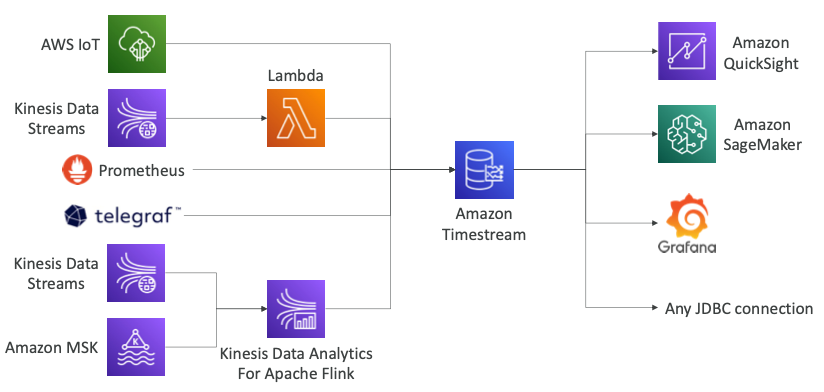
- AWS IoT를 통해서 데이터를 받을 수 있다.
- Kinesis Data Stream으로부터 데이터를 전달받은 람다를 통해서 데이터를 받을 수 있다.
- Prometheus, telegraf와의 통합 정책을 제공한다.
- Kinesis Data Stream, Amazon MSK를 통해 Kinesis Data Analytics로 데이터가 전달되고 전달된 데이터를 Timestream에 저장할 수 있다.
- 저장된 데이터를 기반으로 아래와 같은 작업을 진행할 수 있다.
- QuickSight를 이용해 대시보드를 만들 수 있다.
- SageMaker을 이용해 머신러닝을 할 수 있다.
- Grafana를 이용하여 대시보드를 생성할 수 있다.
- JDBC와 호환되는 애플리케이션과 연결될 수 있다.
Amazon Athena
- S3에 저장된 데이터를 분석하는 서버리스 쿼리 서비스다.
- 표준 SQL 언어(Presto 기반)를 사용하여 파일을 조회할 수 있다.
- CSV, JSON, ORC, Avro 및 Parquet를 지원한다.
- 스캔한 데이터 1TB당 $5.00를 지불해야 한다.
- 일반적으로 보고/대시보드용으로 Amazon Quicksight와 함께 사용된다.
- 비지니스, 인텔리전스/분석/보고, VPC Flow Logs, ELB Logs, CloudTrail 등을 분석 및 쿼리할 때 사용한다.

성능 향상
- 비용 절감을 위해 컬럼 데이터를 사용하여 스캔되는 양을 줄인다.
- Apache Parquet 또는 ORC가 권장된다.
- 성능이 크게 향상된다.
- Glue를 사용하여 데이터를 Parquet 또는 ORC로 변환할 수 있다.
- 소규모 검색을 위해 데이터 압축(bzip2, gzip, lz4, snapy, zlip, zstd 등)을 지원한다.
- 가상 컬럼에서 쉽게 조회할 수 있도록 S3의 파티션 데이터 셋을 지원한다.
s3://yourBucket/pathToTables3://athena-examples/flight/parquet/year=1991/month=1/day=1/
- 128MB보다 더 큰 파일을 사용하여 오버헤드를 최소화하고 성능을 향상시킬 수 있다.
- S3에 아주 작고 많은 파일이 있는 경우보다 큰 파일을 사용하는 경우가 더 높은 성능이 나온다.
Federated Query
- 관계형, 비관계형, 객체형 및 사용자 정의 데이터 소스(AWS 또는 온프레미스)에 저장된 데이터 전반에 걸쳐 SQL 쿼리를 실행할 수 있다.
- AWS 람다에서 실행되는 데이터 소스 커넥터를 사용하여 연합 쿼리를 실행한다. (예: CloudWatch Logs, DynamoDB, RDS 등..)
- 결과를 S3에 다시 저장한다.

Amazon QuickSight
- 대화형 대시보드를 만들기 위한 서버리스 머신러닝 기반의 BI(Business Intelligence) 서비스다.
- 세션별 가격 정책을 통해 빠르고 자동으로 확장 가능하며 내장 가능하다.
- 비즈니스 분석, 빌딩 시각화, 임시 분석 수행, 데이터를 사용하여 BI 확보 등에 사용된다.
- RDS, AUrora, Athena, Redshift, S3 등과 통합된다.
- QuickSight로 데이터를 가져오는 경우 SPICE 엔진을 사용한 인메모리 계산을 제공한다.
- 엔터프라이즈 에디션의 경우 CLS(Column-Level Security)를 설정할 수 있다.

Integration

- QuickSight는 수많은 데이터 소스와 통합될 수 있다.
- AWS Service
- RDS, Aurora, Redshift, Athena, S3, OpenSearch, Timestream
- SaaS
- Salesforce, Jira
- 써드파티
- teradata
- 기타
- 온프레미스 데이터베이스(JDBC), XLSX, CSV, JSON, .TSV, TLF, CLF
Dashboard & Analysis
- 사용자(표준 버전) 및 그룹(엔터프라이즈 버전) 정의
- 이러한 사용자 및 그룹은 QuickSight 내에만 존재하며 IAM과는 다르다.
- Dashboard
- 공유할 수 있는 분석물의 읽기 전용 스냅샷이다.
- 분석물의 구성(filtering, 파라미터, 컨트롤, 정렬)을 보존한다.
- 분석 또는 대시보드를 사용자 또는 그룹과 공유할 수 있다.
- 대시보드를 공유하려면 먼저 게시해야 한다.
- 대시보드를 보는 사용자도 기본 데이터를 볼 수 있다.
Data Engineering

- 분석 계층을 위해 S3를 이용하면 Hadoop을 실행하는 EMR 클러스터에서 데이터를 읽을 수 있다.
- Spark 또는 Hive는 오픈소스 빅데이터 도구에 액세스할 수 있는 권한을 제공한다.
- 온프레미스에서 AWS로 마이그레이션할 때 유용하게 사용된다.
- 만약 Redshift 같은 AWS 서비스를 사용한다면 Redshift나 Redshift Spectrum을 이용해서 데이터 웨어하우징할 수 있다.
- 저장된 데이터를 Redshift Spectrum으로 직접 쿼리하거나 Redshift 웨어하우스에 데이터를 로드해 SQL을 이용해 쿼리를 수행할 수 있다.
- Athena는 서버리스이며 주기적이지 않으며 간헐적으로 쿼리 결과가 필요할 때 사용된다.
- QuickSight는 시각화를 위한 것이고 Redshift나 Athena와 쉽게 통합하여 대시보드를 생성할 수 있다.
- Redshift나 Athena를 내부 쿼리 레이어로 사용해서 데이터를 올바른 형태로 얻을 수 있다.
Big Data Ingestion Pipeline
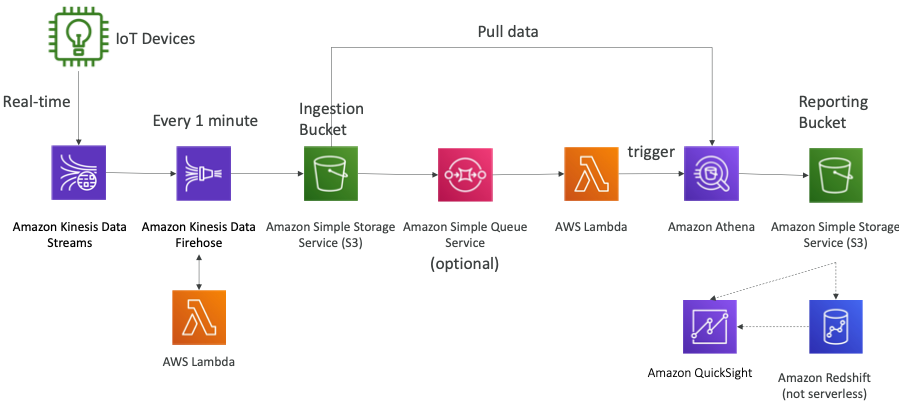
- IoT 장치가 Kinesis Data Streams에서 실시간으로 데이터를 생성하면 Kinesis Data Firehose를 통해 거의 실시간으로 S3 같은 데이터 저장소에 데이터를 저장한다.
- 데이터 변환이 필요한 경우 S3에 데이터가 저장되기 전에 람다 함수를 사용하여 데이터를 변환할 수 있다.
- S3 이벤트를 통해 SQS 큐를 통과하도록 할 수 있으며 통과된 데이터를 람다 함수가 소비하도록 구축할 수 있다.
- 람다 함수는 Athena 작업을 트리거하여 데이터를 S3 버킷에 직접 쿼리하여 레포트 버킷에 데이터를 저장할 수 있다.
- 레포트 버킷에 저장된 데이터를 QuickSight를 통해 대시보드를 생성할 수 있고 Redshift를 이용해 데이터를 생성하거나 입력하고 쿼리할 수 있다.
데이터 저장소 비교
- EMR
- Apache Hive, Spark와 같은 빅데이터 도구를 사용해야 한다.
- 오래 실행되는 클러스터 하나, 자동 확장 기능이 있는 많은 작업, 또는 작업당 클러스터 하나가 필요한 경우에 사용된다.
- Spot, On-demand, Reserved 구매 옵션이 있다.
- DynamoDB 또는 S3에서 데이터에 액세스할 수 있다.
- EBS 디스크(HDFS) 및 S3(EMRFS)의 장기 스크래치 데이터를 저장한다.
- Athena
- 간단한 쿼리 및 집계를 위해 사용되며 데이터는 S3에 저장되어야 한다.
- 서버리스로 단순한 SQL 쿼리, 많은 서비스에 대한 즉시 사용 가능한 쿼리가 필요할 때 사용된다.
- CloudTrail을 통한 감사 쿼리를 사용할 수 있다.
- Redshift
- 고급 SQL 쿼리를 제공하며 서버가 프로비저닝되어야 한다.
- S3에서 서버리스 쿼리에 Redshift Spectrum을 활용할 수 있다.
참고한 강의
'[IT] Infrastructure > Certificate' 카테고리의 다른 글
| [SAP] Deployment & Instance Management (0) | 2024.01.20 |
|---|---|
| [SAP] Monitoring (0) | 2024.01.19 |
| [SAP] Service Communication (0) | 2024.01.17 |
| [SAP] Database (0) | 2024.01.07 |
| [SAP] Caching (0) | 2024.01.07 |



