[부하테스트] 결과 (1차) (링크)의 경우 엑셀 다운로드 시 발생하는 Memory 누수때문에 문제가 발생하였고
[부하테스트] 결과 (2차) (링크)의 경우 Tomcat Thread가 DB Connection을 얻지 못해서 문제가 발생하였다.
2차 부하 테스트에서 발생한 DB Connection 오류를 최소화하기 위하여 HikariCP 공식 Github (링크)를 참고하여 HikariCP 설정을 변경하였고 JPA OSIV (링크) 설정을 OFF로 변경하여 DB Connection을 기존보다 빠르게 반납할 수 있도록 수정하였다. (HikariCP 설정의 경우 MySQL DB에 최적화 된 방식이다. 만약 다른 DB를 사용하고 있다면 다른 최적화 설정을 참고해야한다.)
이번 장에서는 위에서 언급한 두 개의 옵션을 수정하기 전과 성능을 비교하는 벤치마크를 진행해본다.
테스트 방법
모든 테스트는 15분간 진행한다.
동시 요청 유저의 수는 200명으로 고정한다.
유저들은 60초 간격으로 무작위로 요청한다.
테스트 순서는 아래와 같다.
- 설정을 변경하지 않은 경우 (이하 A)
- HikariCP 설정만 변경한 경우 (이하 B)
- OSIV 만 비활성화 한 경우 (이하 C)
- HikariCP와 JPA OSIV 설정 모두 변경한 경우 (이하 D)
테스트 결과
평균 TPS는 큰 차이가 없다.
하지만 성공한 응답만으로 TPS를 산출해보면 아래와 같다.
그러므로 설정 변경 후 TPS가 증가되었다고 볼 수 있다.- A = 2.14 ((3,082 - 1,148) / 900)
- D = 2.72 ((3,158 - 707) / 900)
설정 변경 후에 에러율이 15% 이상 감소되었다.
| 평균 TPS | 요청 Count | 에러 Count | 에러율 | |
|---|---|---|---|---|
| A | 3.24 | 3,082 | 1,148 (500: 32.87%, 504: 4.38%) | 37.2 |
| B | 3.28 | 3,130 | 880 (500: 77.82%, 504: 4.12%) | 25.6 |
| C | 3.28 | 3,135 | 873 (500: 24.18%, 504: 3.67%) | 27.8 |
| D | 3.29 | 3,158 | 707 (500: 19.32%, 504: 3.07%) | 22.4 |
리소스 사용량의 경우 큰 차이가 없어서 생략하였다.
성능 개선
이번에 다룰 내용은 벤치마크 결과와는 무관한 내용이다.
하지만 벤치마크를 진행하면서 HikariCP에 Connection 요청 횟수를 확인하기위해 로그파일을 확인하던 중
성능을 개선할 수 있는 부분이 발견되어 어떤 방식으로 개선하였는지 공유한다.
벤치마크를 진행하는 도중 가장 오랜 시간이 걸린 요청을 내림차순으로 정렬해보면 /api/races/excel-download 인 것을 확인할 수 있다.
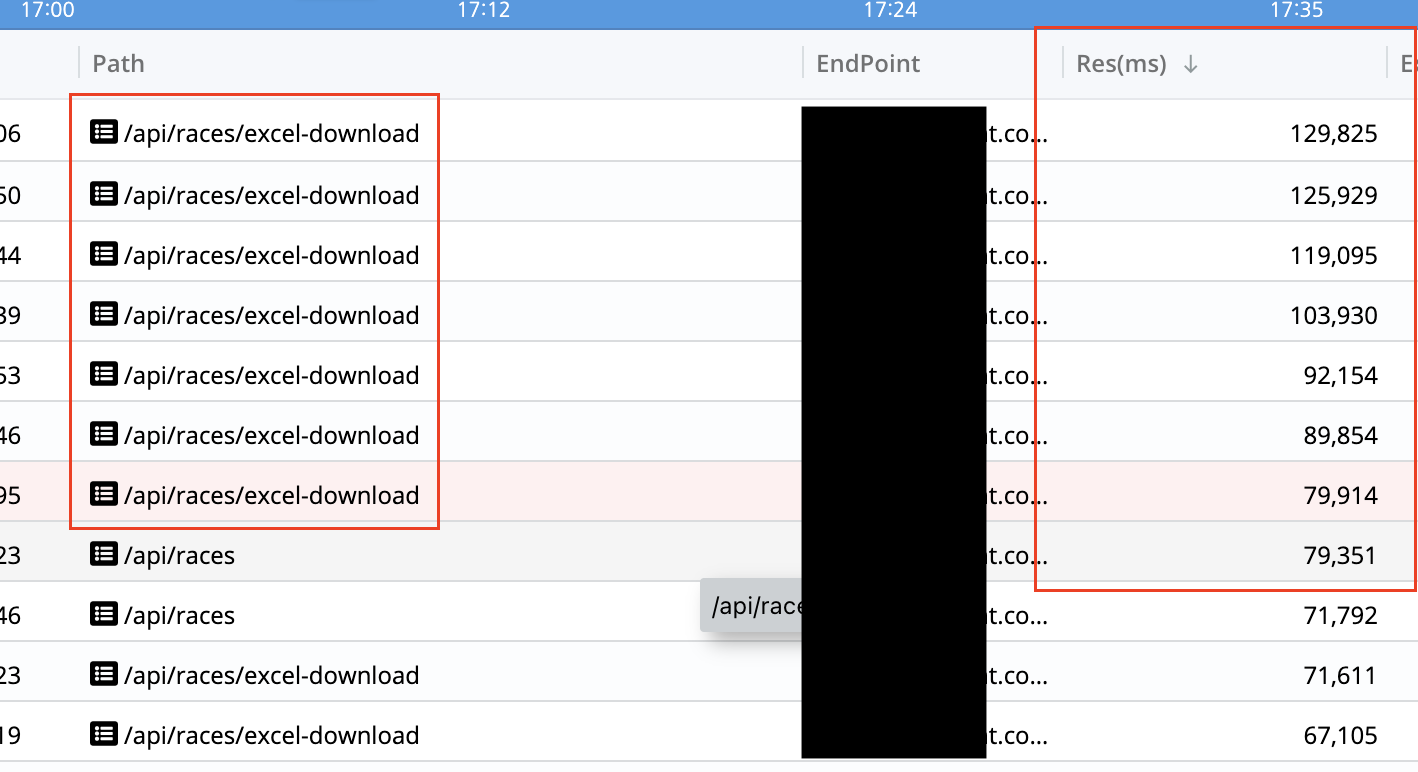
어떠한 이유로 오래걸렸는지 상세한 Transaction내의 작업목록을 확인해본다.
상세 Transaction은 Pinpoint를 통해서 확인하였다.
Pinpoint 관련된 자료는 [Pinpoint] 개념 (링크)에 정리해두었으니 필요하면 확인해보도록 한다.

해당 API는 최초에 사용자의 요청이 들어오면 최대 다운로드 가능량 (작성일 기준 5000건)을 초과하지 않는지 count 쿼리를 실행한다. 만약 최대 다운로드 가능량을 초과하지 않았다면 실제로 데이터를 뽑아온다. 여기서 overhead가 발생한다. 다시 위의 이미지를 확인해보면 시간이 오래 걸리는 작업은 아래의 목록과 같다.
- 최대 다운로드 가능량을 초과하는지 확인하기 위한 count query (21.886 seconds, 이하 A)
- Pagenation을 처리하기 위한 count query (22.623 seconds, 이하 B)
- 실제 데이터를 가져오는 query (29.123 seconds, 이하 C)
목록을 보면 의문이 생길 것이다. "20초가 넘게 소비되는 count query가 왜 두 번이나?! A랑 B랑 다른 쿼리인가...???" 직접 쿼리를 확인해본다.
A query
SELECT count(AM.idx) FROM allocation_mapping AM INNER JOIN allocation A ON AM.allocation_idx = A.allocation_idx INNER JOIN company_member CM ON A.member_idx = CM.member_idx WHERE 생략B query
SELECT count(AM.idx) FROM allocation_mapping AM INNER JOIN allocation A ON AM.allocation_idx = A.allocation_idx INNER JOIN company_member CM ON A.member_idx = CM.member_idx WHERE 생략
그렇다. 완벽히 동일한 쿼리가 중복으로 요청되고 있었다.
A query에서 요청한 결과를 B query를 요청하는 대신에 사용한다면 사용자는 대략 20초 정도 빠르게 응답받을 수 있게 된다. 이 수치는 기존 요청의 소요시간 대비 2 / 3으로 줄어드는 수치이기 때문에 사용자 입장에서 봤을 때 상당히 단축되었다고 볼 수 있다. 또한 DB Connection을 매 요청마다 대략 20초씩 빠르게 반납할 것이므로 전체적인 TPS에도 상당한 영향을 줄 수 있다.
mysql 7미만 버전에서는 기본적으로 Query Cache 옵션이 활성화 되어 있어서 같은 쿼리가 중복 요청되면 분명 빠르게 응답했어야하는데 B 요청이 오래 걸린 이유는 파악하지 못했다. Aurora는 다른가..???
지금까지 벤치마크를 진행하며 overhead가 발생하는 부분을 발견하고 해결하는 방법에 대해서 알아보았다.
'Stress Test' 카테고리의 다른 글
| [Benchmark] Datasource 분리 (0) | 2022.01.22 |
|---|---|
| [부하 테스트] 분석 (2차) (0) | 2022.01.22 |
| [부하 테스트] 결과 (2차) (0) | 2022.01.22 |
| [부하 테스트] 분석 (1차) (0) | 2022.01.22 |
| [부하 테스트] 결과 (1차) (0) | 2022.01.22 |



