Cluster Design
- 이번 장에서는 Certified Kubernetes Administrator (CKA) 을 준비하며 "클러스터 아키텍처를 디자인하는 방법"에 대해서 자세하게 알아보도록 한다.
클러스터 설계
클러스터 설계 전 고려 사항

- 클러스터의 목적
- 학습, 개발, 테스트, 운영 등
- 클라우드 도입 수준
- 클라우드 제공업체 관리 플랫폼 사용, 자체 호스팅 등
- 워크로드 유형
- 클러스터에서 실행될 워크로드의 종류
- 호스팅 될 애플리케이션의 수
- 웹 애플리케이션, 빅데이터, 분석 등
- 지속적인 트래픽 또는 버스트 트래픽 등 네트워크 트래픽 유형 고려
클러스터 유형별 설계
- 학습 목적:
- Minikube 또는 Kubeadm을 사용한 단일 노드 클러스터 (로컬 VM 또는 클라우드 환경)
- 개발 및 테스트 목적:
- 단일 마스터 및 다중 워커 노드로 구성된 다중 노드 클러스터
- Kubeadm, GKE, kOps (AWS) 등 사용
- 클러스터 규모 및 리소스 요구 사항:
- 클러스터 최대 규모:
- 최대 5,000개 노드
- 최대 150,000개 파드
- 최대 300,000개 컨테이너
- 노드당 최대 100개의 파드
- 노드 리소스 요구 사항:
- 클러스터 규모에 따라 노드 리소스 요구 사항이 달라진다.
- GCP, AWS 등 클라우드 제공업체는 노드 수에 따라 적절한 노드 크기를 자동으로 선택해준다.
- 온프레미스 환경은 클라우드 제공업체 권장 리소스 사양을 참고하면 된다.
- 클러스터 최대 규모:
- 스토리지 구성:
- 고성능 워크로드: SSD 기반 스토리지
- 다중 동시 액세스: 네트워크 기반 스토리지
- 다중 파드 간 공유 액세스: 영구 스토리지 볼륨
- 다양한 스토리지 클래스 정의 및 애플리케이션별 적절한 클래스 할당
노드 구성
- 노드 유형:
- 물리적 머신 또는 가상 머신
- VirtualBox, GCP, AWS, Azure 등 다양한 환경 지원
- 클러스터 구성 예시:
- 1개 마스터 노드 및 2개 워커 노드로 구성된 클러스터
- 마스터 노드 역할:
- 컨트롤 플레인 컴포넌트(API 서버, etcd 서버 등) 호스팅
- 워크로드 호스팅 가능(운영 환경에서는 권장되지 않음)
- 워커 노드 역할:
- 워크로드 호스팅
- 운영 체제:
- 64비트 Linux 운영 체제
- etcd 클러스터 분리:
- 대규모 클러스터에서는 etcd 클러스터를 마스터 노드에서 분리하여 별도의 클러스터 노드에 배치 가능(고가용성 구성)
배포 도구
- 온프레미스: Kubeadm
- GCP: Google Container Engine(GKE)
- AWS: kOps
- Azure: Azure Kubernetes Service(AKS)
쿠버네티스 인프라스트럭처 선택
쿠버네티스 배포 환경
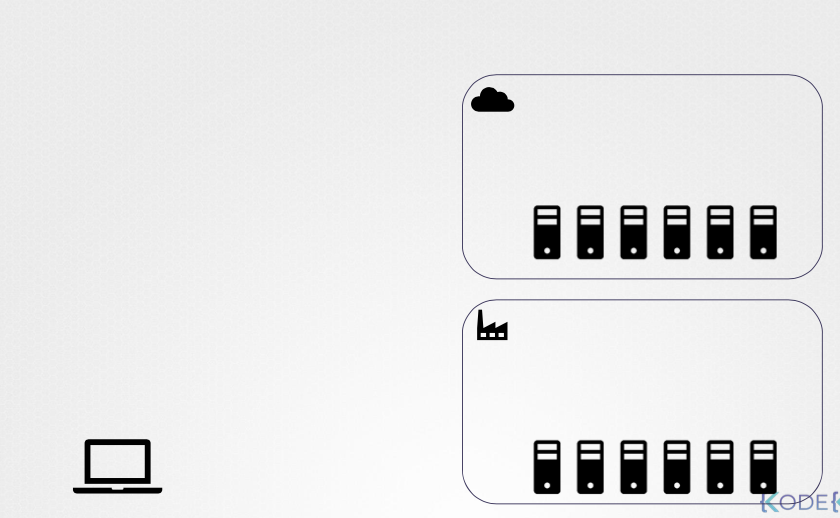
- 다양한 환경 지원: 쿠버네티스는 랩톱, 물리/가상 서버 (온프레미스), 클라우드 등 다양한 환경에서 배포가 가능하다.
- 요구 사항 및 환경 고려: 요구 사항, 클라우드 생태계, 배포할 애플리케이션 종류에 따라 적절한 솔루션 선택이 필요하다.
로컬 환경 배포

- Linux:
- 바이너리 수동 설치 및 로컬 클러스터 설정 (복잡)
- 자동화 솔루션 사용 (Minikube, Kubeadm)
- Windows:
- Hyper-V, VMware Workstation, VirtualBox 등 가상화 소프트웨어 사용
- Linux VM 생성 후 쿠버네티스 설치
- Windows VM에서 Docker 컨테이너로 쿠버네티스 컴포넌트 실행 (Linux 기반 Docker 이미지 사용)

- 로컬 배포 솔루션:
- Minikube: 단일 노드 클러스터 배포, VirtualBox 등 가상화 소프트웨어 활용, 학습용
- Kubeadm: 단일/다중 노드 클러스터 배포, VM 사전 프로비저닝 필요, 개발/테스트용
운영 환경 배포

- 턴키 솔루션(Turnkey Solutions):
- VM 프로비저닝 후 도구/스크립트를 사용하여 쿠버네티스 클러스터를 구성한다.
- VM 유지 관리 및 패치/업그레이드 책임은 사용자에게 있다.
- 클러스터 관리 및 유지 보수를 위한 도구/스크립트를 제공한다.
- 예시: kOps(AWS), OpenShift, Cloud Foundry Container Runtime, VMware, Cloud PKS, Vagrant
- 호스팅 솔루션(Hosted Solutions):
- 클라우드 제공업체가 VM 및 쿠버네티스 클러스터를 배포 및 구성한다.
- VM 유지 관리 및 패치/업그레이드 책임은 제공업체에게 있다.
- Kubernetes as a Service (KaaS) 형태
- 예시: Google Container Engine (GKE), OpenShift Online, Azure Kubernetes Service (AKS), Amazon Elastic Container Service for Kubernetes (EKS)
턴키 솔루션 상세

- OpenShift(Red Hat):
- 온프레미스 쿠버네티스 플랫폼
- 추가 도구 및 GUI 제공, CI/CD 파이프라인 통합이 용이하다.
- Cloud Foundry Container Runtime:
- 오픈 소스 프로젝트, BOSH 도구를 사용하여 고가용성 쿠버네티스 클러스터를 배포 및 관리할 수 있다.
- VMware Cloud PKS:
- VMware 환경에서 쿠버네티스를 활용할 수 있다.
- Vagrant:
- 다양한 클라우드 제공업체에 쿠버네티스 클러스터 배포를 위한 스크립트를 제공한다.
호스팅 솔루션 상세
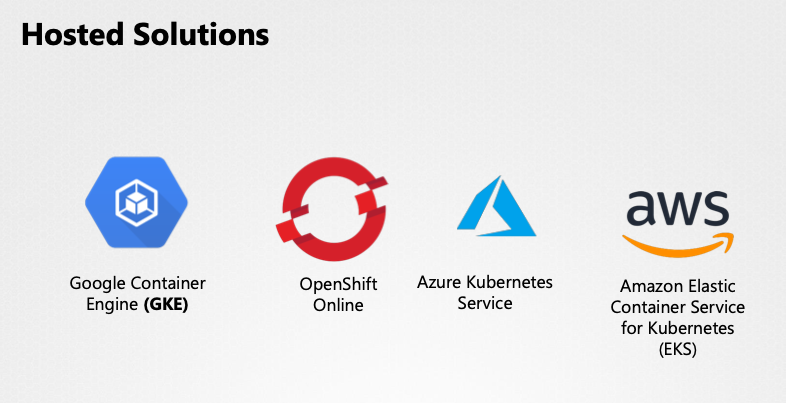
- Google Container Engine(GKE):
- Google Cloud Platform의 KaaS
- 간편한 클러스터 배포 및 관리가 가능하다.
- OpenShift Online(Red Hat):
- 완전 기능의 쿠버네티스 클러스터 온라인 접근을 제공한다.
- Azure Kubernetes Service(AKS):
- Azure에서 제공하는 KaaS다.
- Amazon Elastic Container Service for Kubernetes(EKS):
- AWS에서 제공하는 KaaS다.
HA 쿠버네티스 클러스터
마스터 노드 장애 시 문제점
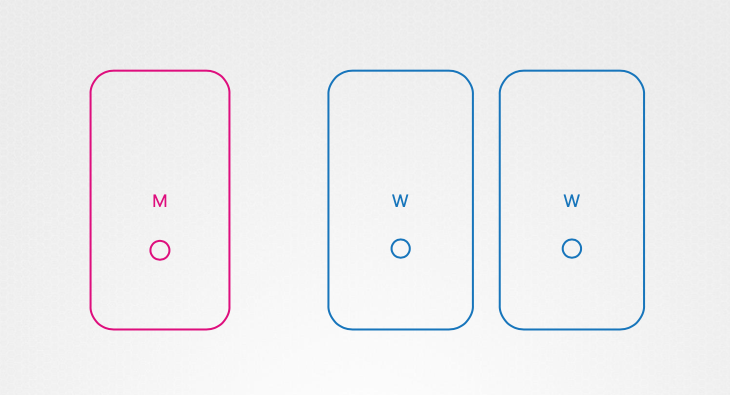
- 애플리케이션 작동 중단: 워커 노드가 작동하고 컨테이너가 실행되는 동안에는 애플리케이션이 계속 실행되지만, 컨테이너 또는 파드가 실패하면 복구할 수 없다.
- 컨트롤 플레인 컴포넌트 장애: 마스터 노드의 컨트롤 플레인 컴포넌트(API Server, Controller Manager, Scheduler)가 작동하지 않아 파드 재 생성 및 스케줄링이 불가능하다.
- 클러스터 관리 불가: kube-apiserver가 작동하지 않아 kubectl 또는 API를 통한 클러스터 관리가 불가능하다.
고가용성(HA) 구성의 필요성
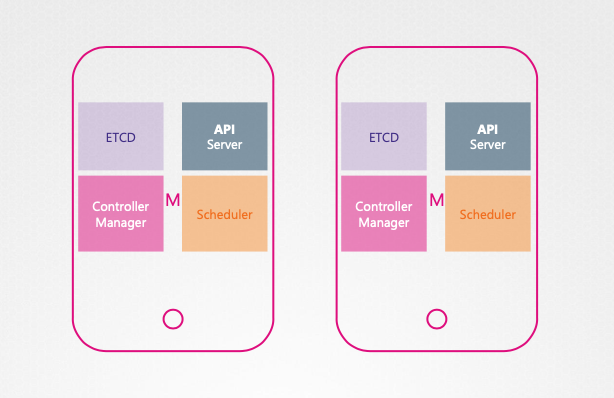
- 단일 장애점 제거: HA 구성은 클러스터의 모든 컴포넌트에 중복성을 제공하여 단일 장애점을 제거한다.
- 마스터 노드 및 컨트롤 플레인 컴포넌트 HA: 마스터 노드와 컨트롤 플레인 컴포넌트의 HA 구성을 도입할 수 있다.
HA 쿠성에서 컨트롤 플레인 컴포넌트 작동 방식
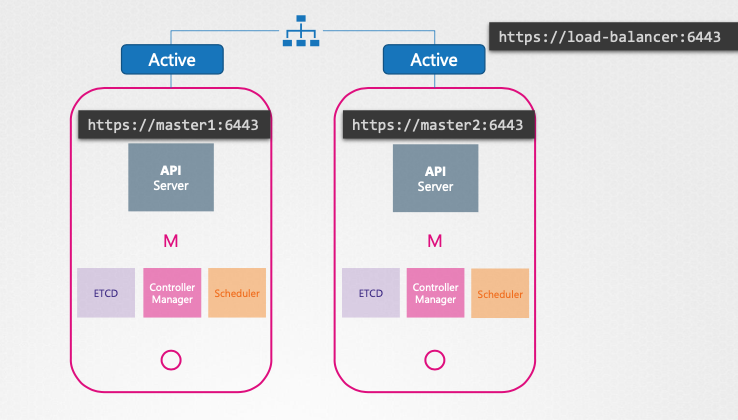
- API Server:
- 활성-활성(active-active) 모드로 작동하여 모든 마스터 노드에서 동시에 실행된다.
- kube-control 유틸리티는 로드 밸런서를 통해 API 서버에 접근한다.
- 로드 밸런서는 Nginx, HAProxy등 다양한 솔루션을 사용할 수 있다.
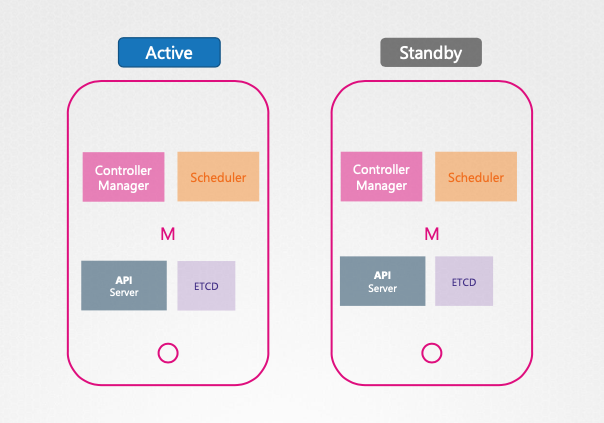
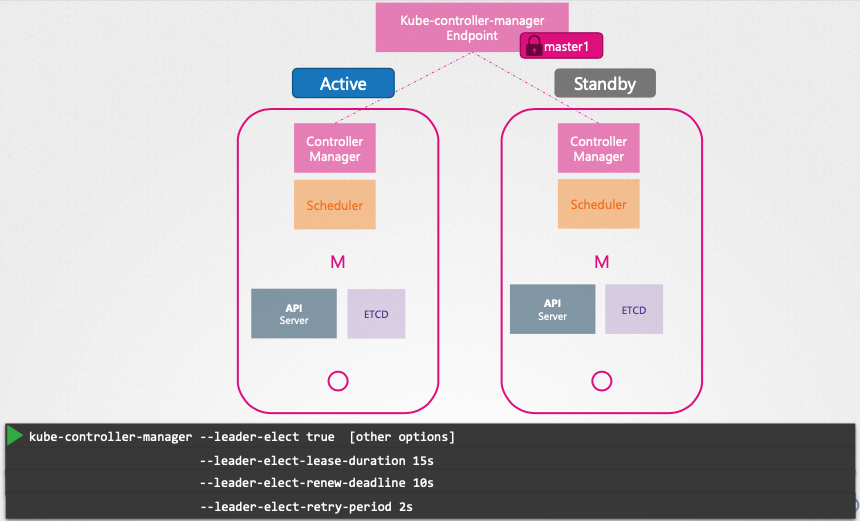
- Controller Manager 및 Scheduler:
- 활성-대기(active-standby) 모드로 작동하여 리더 선출(Leader election) 포르세스를 통해 활성 인스턴스를 결정한다.
- 리더 선출은 etcd의 엔드포인트 객체를 사용하여 구현된다.
- 활성 인스턴스는 리더십을 유지하기 위해 주기적으로 etcd에 갱신(renew)한다.
- 대기 인스턴스는 활성 인스턴스 장애 시 리더십을 획득한다.
- 관련 명령줄 옵션:
leader-elect,leader-elect-lease-duration,leader-elect-renew-deadline,leader-elect-retry-period
etcd 클러스터 구성
etcd 토폴로지
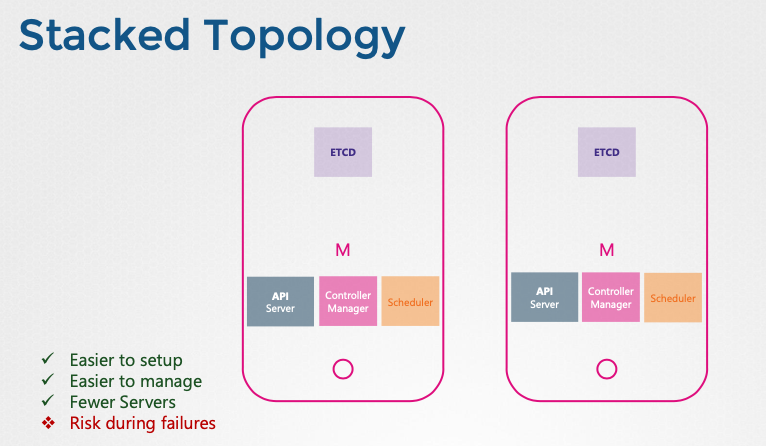
- 스택형 컨트롤 플레인 노드(stacked control plane nodes): etcd가 마스터 노드에 포함된다. 설정 및 관리가 용이하지만 마스터 노드 장애 시 etcd 데이터도 손실된다.
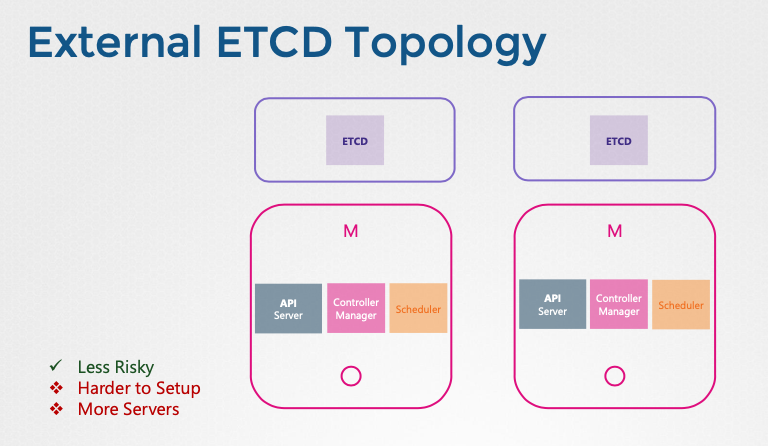
- 외부 etcd 서버(external etcd servers): etcd가 별도의 서버에서 실행된다. 안정성이 높지만, 설정이 복잡하고 더 많은 서버가 필요하다.
API 서버와 etcd 통신
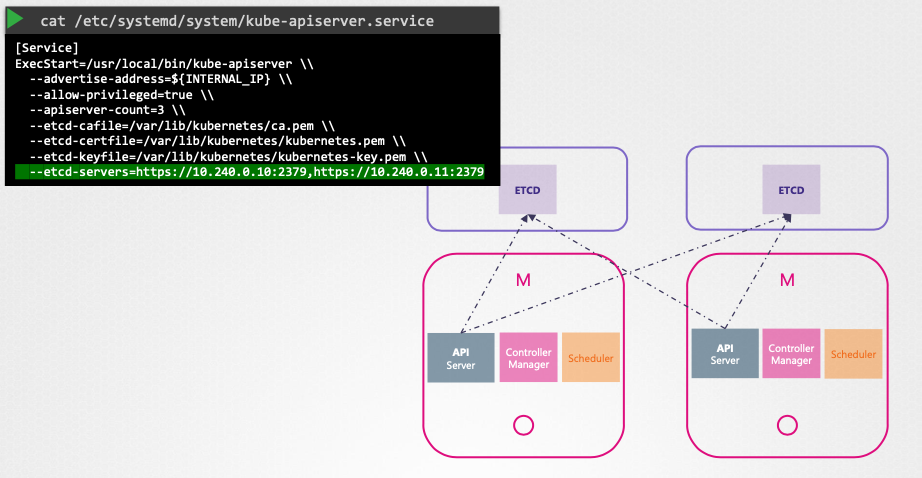
- API 서버는 etcd 서버와 통신하여 클러스터 데이터를 저장하고 검색한다.
- API 서버 설정 옵션을 통해 etcd 서버 주소를 지정한다.
- etcd는 분산 시스템이므로 API 서버는 etcd 클러스터의 어느 인스턴스에든 접근할 수 있다.
- kube-apiserver 설정에 etcd 서버 목록을 지정한다.
etcd in HA
etcd 개요

- etcd란?: 분산, 신뢰성 있는 키-값 저장소로, 단순하고 안전하며 빠르다.
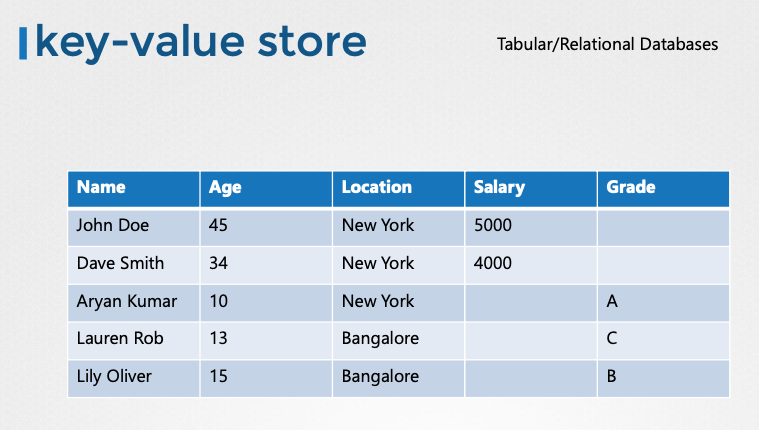
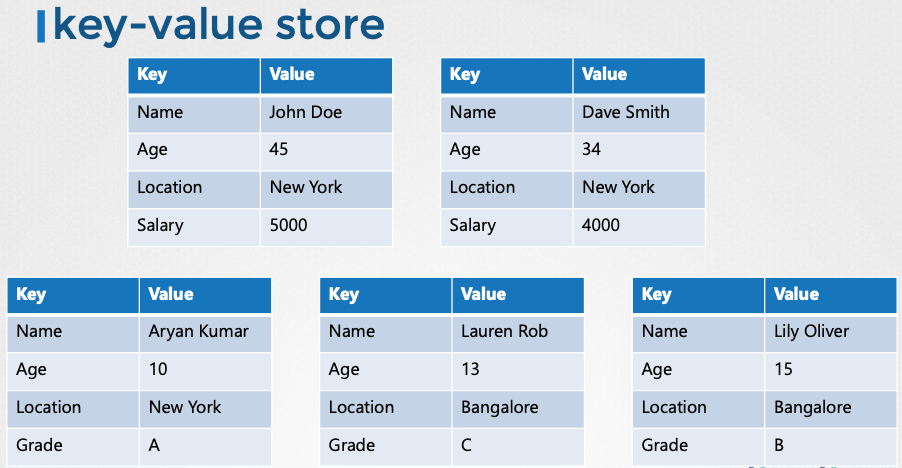

- 키-값 저장소: 데이터를 문서 또는 페이지 형태로 저장하며, 각 개별 데이터는 파일 형태로 관리된다.
- JSON/YAML 데이터 형식: 복잡한 데이터는 JSON 또는 YAML 형식으로 저장 및 검색된다.

etcd 분산 시스템의 이해

- 데이터 중복성: etcd 데이터를 여러 서버에 분산 저장하여 데이터 손실을 방지한다.
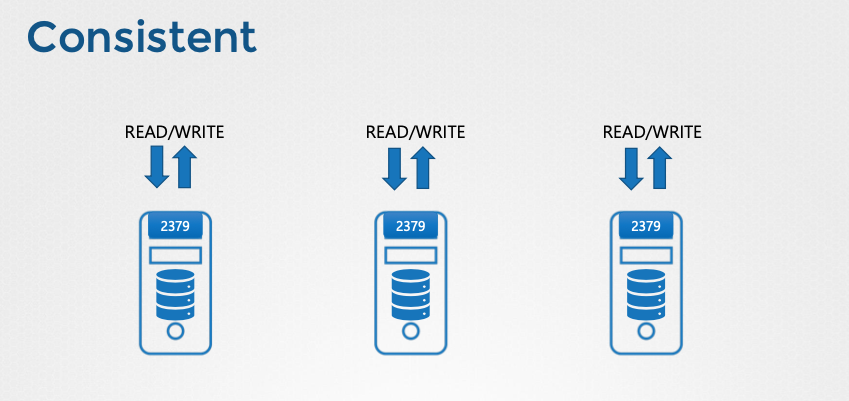
- 데이터 일관성 유지: 여러 etcd 인스턴스 간에 동일한 데이터 복사본을 유지하여 데이터 일관성을 보장한다.
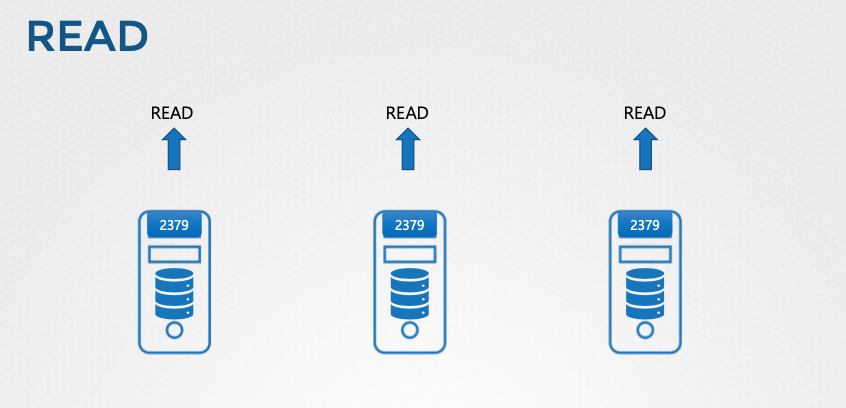
- 읽기 작업: 모든 etcd 노드에서 동일한 데이터를 읽을 수 있다.
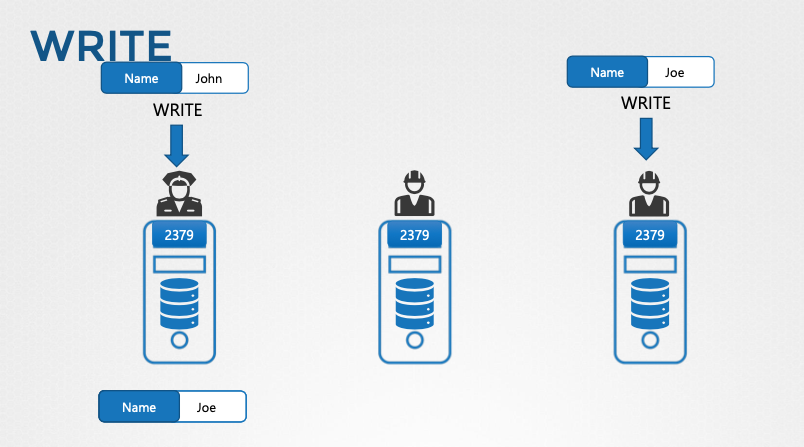
- 쓰기 작업:
- 모든 etcd 노드에서 쓰기 요청을 받을 수 있지만, 실제 쓰기 작업은 리더 노드에서만 처리된다.
- 리더 노드는 다른 팔로워 노드에게 데이터 복사본을 전송하여 데이터 일관성을 유지한다.
- 팔로워 노드는 쓰기 요청을 리더 노드로 전달한다.
etcd 클러스터 기본 작동 방식
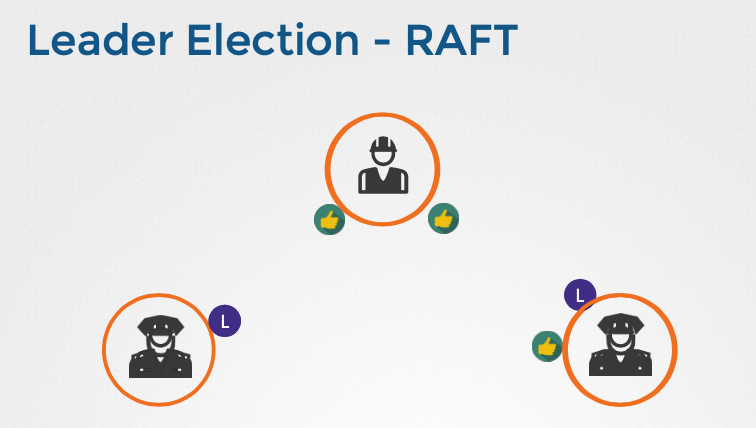
- 리더 선출:
- 클러스터 초기 설정 시, 모든 노드는 리더가 없는 상태로 시작한다.
- 각 노드는 임의의 타이머를 시작하고, 타이머가 먼저 만료된 노드가 리더 선출 요청을 다른 노드에 보낸다.
- 다른 노드들은 요청을 받고 투표로 응답하며, 과반수의 투표를 얻은 노드가 리더로 선출된다.
- 선출된 리더는 주기적으로 하트비트(heartbeat)를 보내 다른 노드들에게 자신의 존재를 알린다.
- 재선출:
- 리더가 다운되거나 네트워크 연결이 끊기면, 다른 노드들은 하트비트를 받지 못하고 재선출 과정을 시작한다.
- 새로운 리더가 선출되고, 클러스터는 정상 작동을 유지한다.
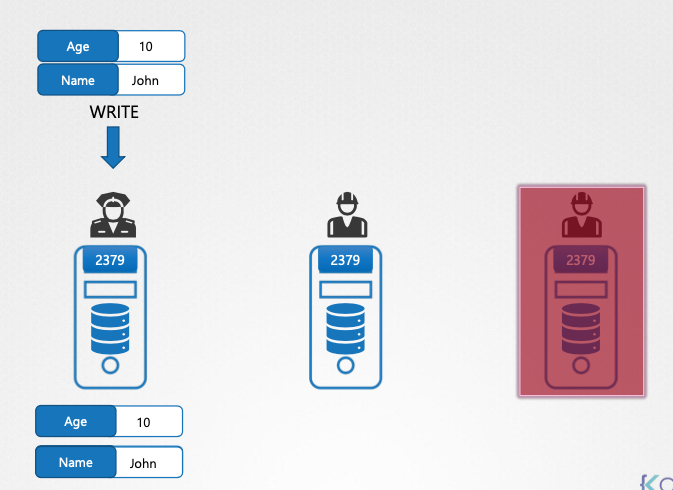
- 쓰기 작업:
- 쓰기 요청은 리더 노드에서 처리되고, 다른 노드들에 복제된다.
- 과반수 노드에 복제가 완료되면 쓰기 작업이 완료된 것으로 간주된다.
쿼럼(Quorum) 및 고가용성(HA)

- 쿼럼 정의:
- 쿼럼은 클러스터가 정상 작동하거나 쓰기 작업을 성공적으로 수행하기 위해 필요한 최소 노드 수다.
- 쿼럼은 다음과 같은 공식으로 계산된다. [(N/2) + 1] (여기서 N은 총 노드 수, []는 올림을 의미)
- 노드 수에 따른 쿼럼 및 장애 허용:
- 1개 노드: 쿼럼 1, 장애 허용 0
- 2개 노드: 쿼럼 2, 장애 허용 0 (실질적인 HA 효과 없음)
- 3개 노드: 쿼럼 2, 장애 허용 1
- 5개 노드: 쿼럼 3, 장애 허용 2
- 7개 노드: 쿼럼 4, 장애 허용 3
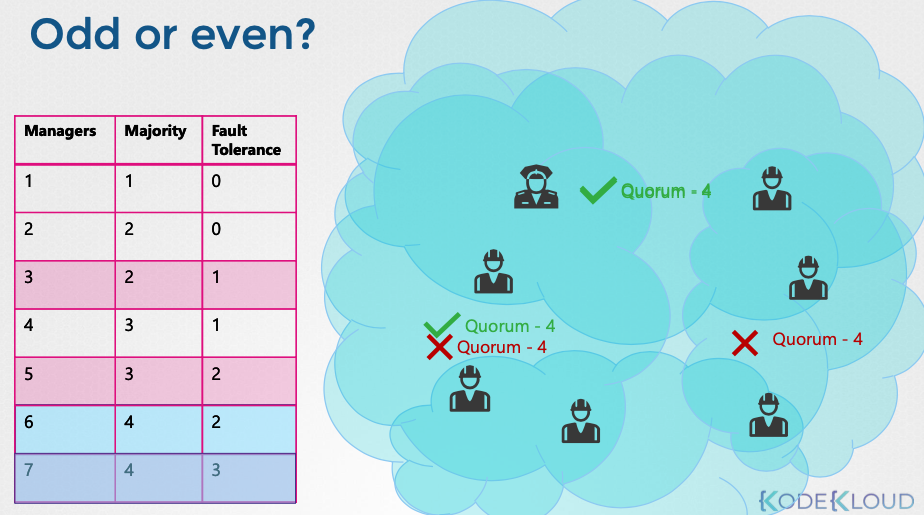
- 홀수 노드 권장 이유:
- 네트워크 분할(network partition) 시, 홀수 노드 클러스터는 쿼럼을 유지할 가능성이 높다.
- 짝수 노드 클러스터는 네트워크 분할 시 쿼럼을 잃고 클러스터가 실패할 수 있다.
- 최소 3개 노드 권장:
- HA를 위해 최소 3개의 노드가 필요하다.
- 1개 노드 장애를 허용하며, 쿼럼을 유지하여 정상 작동을 보장한다.
- 5개 노드 이상은 불필요:
- 5개의 노드는 충분한 장애 허용 능력을 제공한다.
- 추가적인 노드는 복잡성만 증가시키고 성능 저하를 초래할 수 있다.
etcd 설치 및 설정

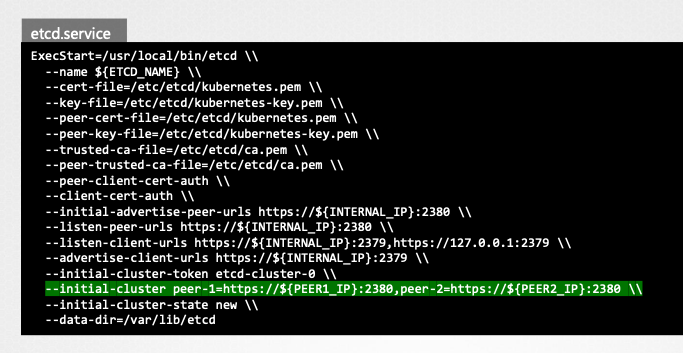
- 설치 과정:
- 최신 etcd 바이너리 다운로드 및 압축 해제
- 필요한 디렉토리 구조 생성
- TLS 인증서 파일 복사
--initial-cluster옵션을 통해 클러스터 피어 정보 설정

- etcdctl 사용법:
- etcdctl은 etcd 클러스터와 상호 작용하는 명령줄 유틸리티다.
- etcdctl API 버전은 v2와 v3가 있으며, v3를 사용하려면
ETCDCTL_API=3환경 변수를 설정해야 한다. etcdctl put <key> <value>: 키-값 데이터 저장etcdctl get <key>: 키에 해당하는 값 조회etcdctl get --keys-only: 모든 키 조회
클러스터 노드 수 결정
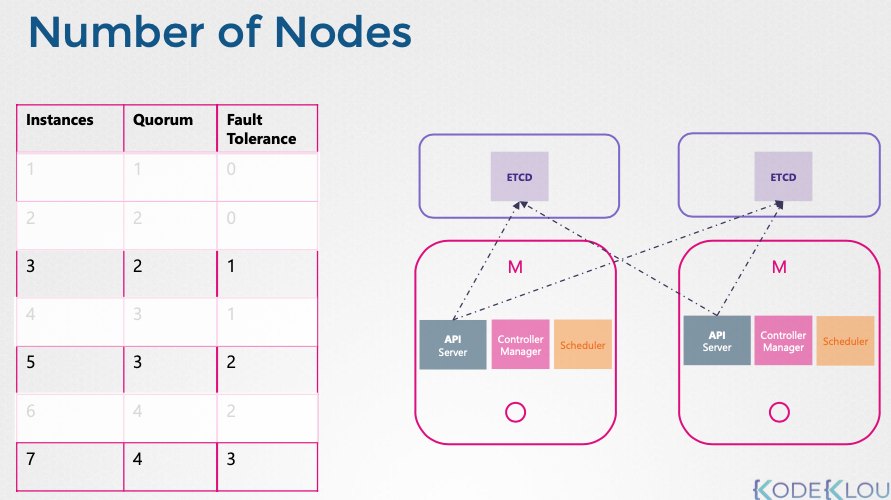
- HA 요구 사항 및 비용 고려:
- HA를 위해 최소 3개 노드 필요
- 높은 장애 허용 능력이 필요하면 5개 노드 권장
- 비용 및 환경 제약을 고려
참고한 강의
'Infrastructure > Kubernetes' 카테고리의 다른 글
| [CKA] Kustomize (Basic) (0) | 2025.03.17 |
|---|---|
| [CKA] Helm (0) | 2025.03.16 |
| [CKA] Networking (Gateway API) (0) | 2025.03.12 |
| [CKA] Networking (Ingress) (0) | 2025.03.12 |
| [CKA] Networking (ClusterDNS) (0) | 2025.03.12 |



