Kinesis
- 이번 장에서는 DevOps Engineer Professional (DOP) 을 준비하며 "Kinesis 서비스"에 대해서 알아보도록 한다.
Kinesis Overview
- 실시간으로 손쉽게 스트리밍 데이터를 수집, 처리 및 분석이 가능하다.
- 실시간 데이터를 수집한다. 애플리케이션 로그, 메트릭, 웹 사이트 클릭 스트림, IoT 원격 측정 데이터
- Kinesis Data Streams: 데이터 스트림 캡처, 처리 및 저장
- Kinesis Data Firehose: 데이터 스트림을 AWS 데이터 저장소로 적재한다.
- Kinesis Data Analytics: SQL 또는 Apache Flink로 데이터 스트림을 분석한다.
- Kinesis Video Streams: 비디오 스트림 캡처, 처리 및 저장한다.
Kinesis Data Streams
- 1 ~ 365일 사이의 데이터 보존 기간
- 데이터 재처리(재생) 기능
- Kinesis에서 한 번 데이터를 삽입하면 삭제가 불가능 (데이터 불변성)
- 동일한 파티션을 공유하는 데이터가 동일한 샤드로 이동
- Producers: AWS SDK, Kinesis Producer Library(KPL), Kinesis Agent
- Consumers:
- 데이터 생성: Kinesis Client Library(KCL), AWS SDK
- 관리: AWS Lambda, Kinesis Data Firehose, Kinesis Data Analytics
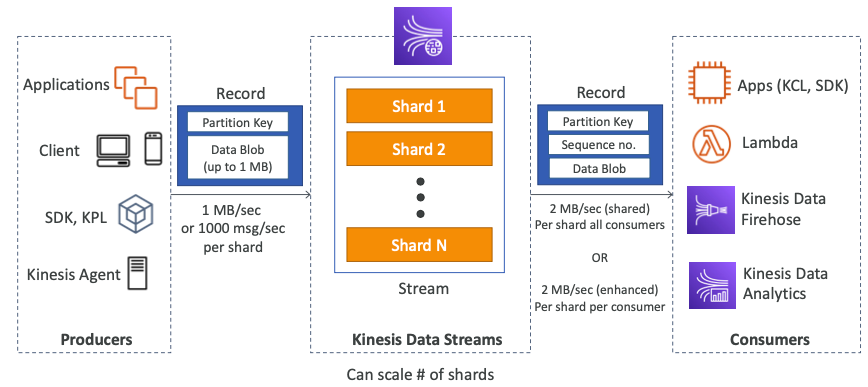
- Kinesis Data Streams(KDS)는 시스템에서 빅데이터를 스트리밍하는 방법이다.
- KDS는 여러개의 샤드로 구성되어 있으며 샤드에는 번호가 할당된다.
- 1번, 2번, N번 등이 될 수 있으며 미리 프로비저닝해 둬야 한다.
- 사용자는 KDS를 시작할 때 총 6개의 샤드가 생성되기를 원한다.
- 데이터가 모든 샤드에 분할되고 샤드가 수집 및 소비율로 스트림 용량을 정의한다.
- 프로듀서는 데이터를 KDS로 전송하며 여러 종류를 지원한다.
- 프로듀서는 애플리케이션, 데스크톱, 모바일, SDK, KPL, Kinesis 에이전트 등 여러 종류를 지원한다.
- 프로듀서는 레코드를 KDS에 만들고, 레코드는 기본적으로 파티션 키와 데이터 블롭으로 구성된다.
- 데이터의 최대 크기는 1MB이며 파티션 키는 레코드가 어느 샤드로 이동할지 결정한다.
- 프로듀서가 KDS로 데이터를 전송할 때 샤드별로 초당 1MB 또는 초당 1,000개의 메시지를 전송할 수 있다.
- 따라서, 샤드가 6개인 경우 초당 6MB를 전송하거나, 초당 6,000개의 메시지를 전송할 수 있다.
- 데이터가 KDS에 저장되면 많은 컨슈머들이 사용할 수 있다.
- 컨슈머는 KCL, SDK, 람다, Kinesis Data Firehose, Kinesis Data Analytics 등 다양한 종류를 지원한다.
- 컨슈머가 레코드를 받으면 파티션 키와 시퀀스 번호도 할당받는다.
- 시퀀스 번호는 레코드가 샤드 어디에 있는지 나타낸다.
- 데이터 블롭도 전달받으며 데이터 그 자체를 의미한다.
- KDS에는 다양한 소비 모드가 있다.
- 초당 2MB의 처리량이 샤드별로 모든 컨슈머에게 공유된다.
- 향상된 컨슈머 모드를 활성화한다면 샤드별로 컨슈머당 초당 2MB를 전달할 수 있다. (향상된 팬아웃)
Capacity Modes
- 프로비저닝 모드(Provisioned Mode):
- 프로비저닝된 샤드의 수를 선택하거나 수동으로 확장하거나 API를 사용할 수 있다.
- 각 샤드는 1MB/s의 입력(또는 초당 1,000개의 레코드).
- 각 샤드당 2MB/s의 출력(클래식 또는 향상된 fan-out 소비자(Consumer)).
- 시간당 프로비저닝 된 샤드당 지불
- 온디멘드 모드(On-demand Mode):
- 용량을 프로비저닝하거나 관리할 필요가 없다.
- 프로비저닝된 기본 용량(초당 4MB 또는 초당 4,000개 레코드)
- 지난 30일 동안 관측된 처리량 피크(Peak)를 기반으로 자동 확장된다.
- 시간당 & 스트림당 지불하며 GB당 데이터 In/Out을 기반으로 지불한다.
Security
- IAM 정책을 사용하여 Access/Authorization 제어가 가능하다.
- HTTPS 엔드포인트를 사용하여 전송 중 데이터를 암호화할 수 있다.
- KSM를 통해서 저장되는 데이터를 암호화할 수 있다.
- 클라이언트 측에서 데이터의 암호화/복호화를 구현할 수 있다.
- Kinesis에서 VPC 내에서 액세스할 수 있는 VPC 엔드포인트를 구축할 수 있다.
- CloudTrail을 사용하여 API 호출을 모니터링할 수 있다.

Scaling Consumers
GetRecords.IteratorAgeMilliseconds(CloudWatch 지표)- 현재 시간과
GetRecords호출의 마지막 레코드가 스트림에 기록된 시간 간의 차이다. - Kinesis 소비자의 진행 상황을 추적하는데 사용된다. (읽기 위치 추적)
- "IteratorAgeMilliseconds" = 0이면 읽고 있는 레코드가 스트림을 완전히 따라잡는다.
- "IteratorAgeMilliseconds" > 0이면 레코드를 충분히 빠르게 처리하지 않음을 의미한다.
- 현재 시간과

- 이 메트릭은 지속적으로 CloudWatch 메트릭으로 발행된다.
- Auto Scaling EC2 인스턴스 그룹이 있으며 KDS의 컨슈머다.
- "IteratorAgeMilliseconds" 메트릭을 통해 CloudWatch 알람을 생성한다.
- 예를 들어, 5분으로 지정하고 스트림에서 5분 이상 지연이 발생하면 CloudWatch 알람이 트리거되고 스케일 아웃 이벤트가 트리거된다.
Kinesis Data Firehose
- 완전 관리형 서비스로 관리가 필요없고 자동으로 확장하며 서버리스로 작동한다.
- AWS: Redshift, S3, OpenSearch
- 타사 파트너: Splunk, MongoDB, DataDog, NewRelic
- 사용자 지정: 원하는 HTTP 엔드포인트로 전송
- KDF를 통과하는 데이터에 대한 비용을 지불한다.
- Near Real Time
- 전체 배치가 아닌 최소 60초 지연 시간 또는 한 번에 최소 1MB의 데이터를 전송한다.
- 다양한 데이터 형식, 변환, 압축을 지원한다.
- AWS 람다를 사용하여 맞춤형 데이터 변환을 지원한다.
- 백업 S3 버킷에 실패한 데이터 또는 모든 데이터를 전송 가능하다.
예시
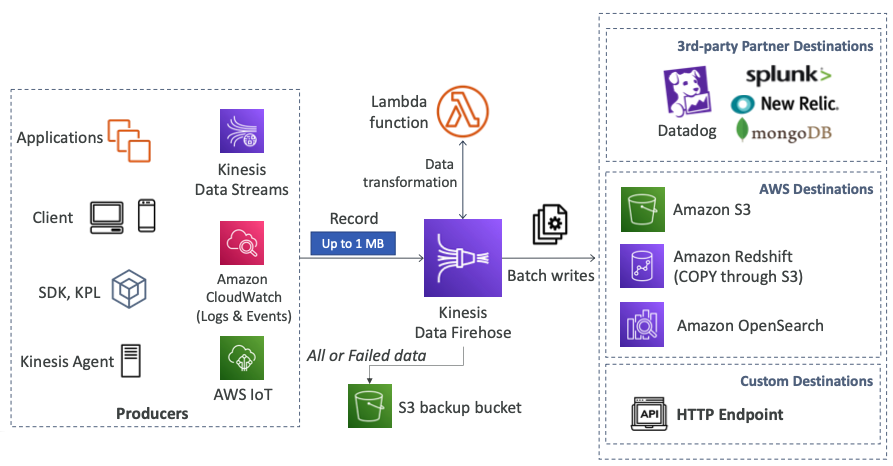
- Kinesis Data Firehose (KDF)는 프로듀서로부터 데이터를 가져올 수 있다.
- 프로듀서는 우리고 보았던 대부분의 서비스가 될 수 있으며 KDF로 레코드를 전송한다.
- 애플리케이션, 데스크톱, 모바일, SDK, Kinesis Agent, KDS, CloudWatch, AWS IoT 등...
- KDF는 선택적으로 람다 함수를 사용하여 데이터를 변환할 수 있다.
- KDF는 세 가지 종류의 목적지가 있다.
- 처음으로 써드파티 제공자의 서비스다.
- Datadog, Splunk, New Relic, mongoDB가 있다.
- 두 번째로는 AWS 서비스다.
- S3, Redshift, OpenSearch가 있다.
- 세 번째로는 커스텀 목적지다.
- HTTP 엔드포인트가 있다.
KDS vs KDF
- Kinesis Data Streams
- 대규모 데이터 수집을 위한 스트리밍 서비스다.
- 사용자 지정 코드 작성 (Producer/Consumer)
- 실시간 (~200ms)
- 확장 관리 (Shard Splitting/Merging)
- 1 ~ 365일 기간 동안의 데이터 저장
- 재생(Replay) 기능 지원
- Kinesis Data Firehose
- S3/Redshift/OpenSearch/써드파티/사용자 지정 HTTP 엔드포인트를 지원한다.
- 완전 관리형 서비스
- 거의 실시간(Near Real-Time, 버퍼 시간 최소 60초)
- 자동 스케일링
- 데이터 저장을 미지원
- 재생(Replay) 기능 미지원
Kinesis Data Analytics
- SQL을 사용하는 "Kinesis Data Streams" & "Firehose"는 실시간 데이터 분석을 위해 사용될 수 있다.
- Amazon S3의 참조 데이터를 추가하여 스트리밍 데이터를 풍부하게 생성할 수 있다.
- 완전 관리형 서비스이기 때문에 프로비저닝할 서버가 없다.
- 자동으로 스케일링이 된다.
- 실제 소비율에 대해서만 지불한다.
- Kinesis Data Streams: 실시간 분석 쿼리에서 스트림을 생성한다.
- Kinesis Data Firehose: 분석 쿼리 결과를 대상으로 전송한다.
- 시계열 분석, 실시간 대시보드, 실시간 메트릭 등을 분석하는 데 사용된다.
예시

- SQL 애플리케이션용 Kinesis Data Analytics (KDA)가 중앙에 위치해있다.
- KDA는 KDS와 KDF로부터 데이터를 읽을 수 있다.
- KDA는 SQL문을 적용하여 실시간 분석을 수행할 수 있으며 참조 데이터를 합칠 수 있다.
- 예를 들어, S3 버킷에서 데이터를 참조하여 실시간으로 데이터를 보강할 수 있다.
- KDS와 KDF로 데이터를 보내 실시간 쿼리에서 스트림을 생성할 수 있다.
- 데이터가 KDF로 전송되는 경우 S3, Redshift 또는 OpenSearch와 같은 목적지로 전송될 수 있다.
- 데이터가 KDS로 전송되는 경우 람다를 사용하여 실시간으로 데이터를 처리하거나 애플리케이션을 사용하여 데이터를 처리할 수 있다.
Kinesis Data Analytics for Apache Flink
- Flink(Java, Scala, SQL)를 사용하여 스트리밍 데이터를 처리 및 분석할 수 있다.

- AWS의 관리 클러스터에서 "Apache Flink" 애플리케이션을 실행할 수 있다.
- 컴퓨팅 리소스 프로비저닝, 병렬 계산, 자동 확장을 지원한다.
- 애플리케이션 백업(체크포인트 및 스냅샷)을 지원한다.
- "Apache Flink" 프로그래밍 기능을 사용할 수 있다.
- "Flink"는 "Firehose"로부터 데이터를 읽지 않으며, "Kinesis Analytics for SQL"을 사용해야 한다.
Machine Learning on Kinesis Data Analytics
- RANDOM_CUT_FOREST
- 스트림의 숫자 열에 대한 "이상 탐지용"에 사용되는 SQL 함수다.
- 예를 들어, NYC 마라톤 중 비정상적인 지하철 탑승을 감지하는데 사용할 수 있다.
- KDA 알고리즘은 최근 기록을 사용하여 계산하고 모델을 훈련시킨다.

- 모든 점들이 원 중앙에 있지만 예외적으로 네 개의 빨간색 데이터 포인트가 있는 것을 확인할 수 있다.
- HOTSPOTS
- 데이터에서 상대적으로 "밀집된 영역"에 대한 정보를 찾아 반환한다.
- 예를 들어, 데이터 센터의 과열된 서버 모음을 확인할 수 있다.
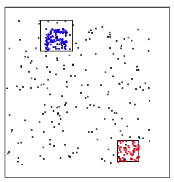
- 파란색 포인트와 빨간색 포인트가 모인 클러스터를 확인할 수 있다.
참고한 강의
'Infrastructure > Certificate' 카테고리의 다른 글
| [DOP] Storage & Database (Resilient Cloud Solutions) (0) | 2024.01.31 |
|---|---|
| [DOP] Route 53 (Resilient Cloud Solutions) (0) | 2024.01.29 |
| [DOP] Container Orchestration (Resilient Cloud Solutions) (0) | 2024.01.29 |
| [DOP] API Gateway (Resilient Cloud Solutions) (0) | 2024.01.28 |
| [DOP] AWS Lambda (Resilient Cloud Solutions) (0) | 2024.01.28 |



