Storage & Database
- 이번 장에서는 DevOps Engineer Professional (DOP) 을 준비하며 "AWS의 스토리지와 데이터베이스 서비스"에 대해서 알아보도록 한다.
Amazon Aurora
Read Replica
- 최대 15개의 읽기 전용 복제본을 지원한다.
- "동일 AZ", "교차 AZ" 또는 "교차 리전"을 지원한다.
- 복제는 ASYNC이므로 읽기의 최종 일관성이 유지된다.
- 복제본을 자체 DB로 승격시킬 수 있다.
- 애플리케이션은 읽기 복제본을 활성화하기 위해 접속 URL을 변경해야 한다.
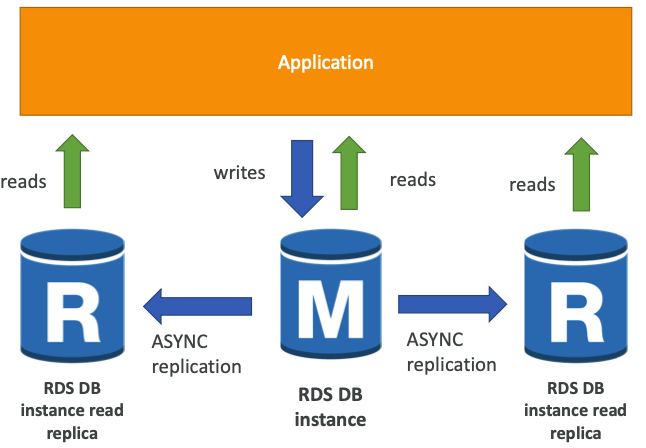
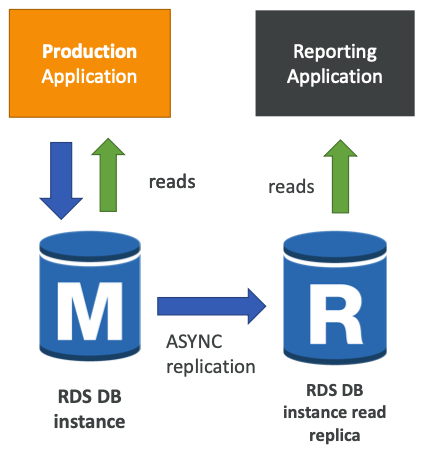
- 정상적인 부하를 처리하는 운영 데이터베이스가 있다.
- 일부 분석을 위해 보고용 애플리케이션을 실행해야 한다.
- 읽기 전용 복제본을 생성하여 그곳에서 새로운 워크로드를 실행한다.
- 운영 데이터베이스는 분석용 애플리케이션으로 인해 영향을 받지 않는다.
- 읽기 전용 복제본은 "SELECT"만 가능하며, "INSERT", "UPDATE", "DELETE"를 지원하지 않는다.
- AWS에서는 데이터가 한 AZ에서 다른 AZ로 이동할 때 네트워크 비용이 발생한다.
- 동일한 리전 & 다른 AZ인 경우 비용이 발생하지 않고, 다른 리전인 경우 전송 비용이 발생한다.

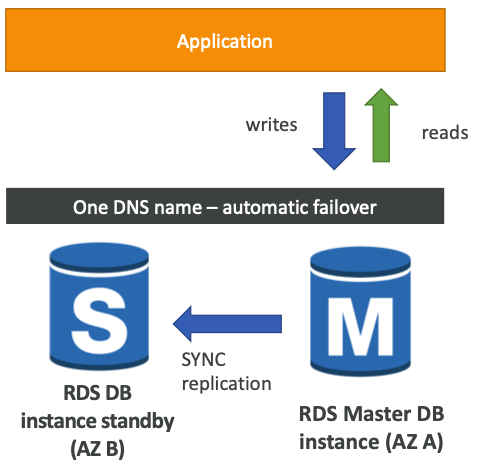
Multi AZ (Disaster Recovery)
- 동기식으로 복제가 이루어진다.
- 동일한 DNS 이름을 사용하므로 장애 발생시 애플리케이션 코드 수정없이 "standby" 상태의 인스턴스를 사용할 수 있다.
- 가용성을 향상시킬 수 있다.
- AZ 장애, 네트워크 손실, 인스턴스 장애 시 자동으로 장애 조치를 실행한다.
- 앱에 수동으로 개입할 필요가 없다.
- 성능 향상을 위한 확장 용도로 사용되지 않는다.
- 읽기 전용 복제본은 재해 복구(DR)을 위해 다중 AZ로 설정된다.
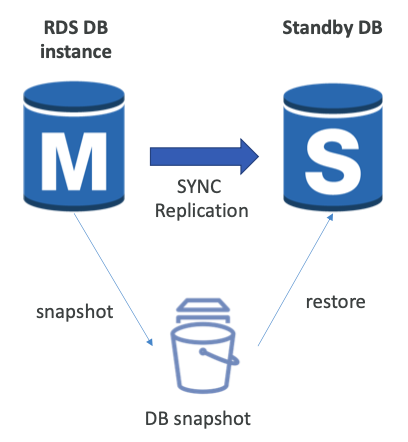
단일 AZ에서 다중 AZ로 전환
- DB 정지가 불필요하므로 다운타임이 0이다.
- 데이터베이스에 대해 "수정"을 클릭하기만 하면 된다.
- 내부적으로 아래의 단계가 발생한다.
- 기존 데이터베이스에서 스냅샷이 생성된다.
- 새로운 AZ에서 스냅샷을 기반으로 복원이 이루어진다.
- 두 데이터베이스 간에 동기화가 설정된다.
Aurora Auto Scaling
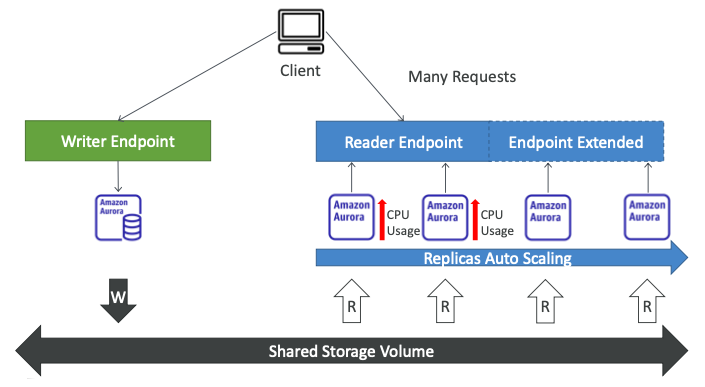
- 하나의 라이터 인스턴스와 여러 개의 읽기 전용 복제본이 있다.
- 라이터 인스턴스는 라이터 엔드포인트를 사용하여 항상 액세스 가능하다.
- 라이터 인스턴스가 다운되면 다른 오로라 인스턴스가 라이터로 승격되고 라이터 엔드포인트가 업데이트되기 때문이다.
- 리더 엔드포인트의 경우 리더 복제본의 수에 따라 업데이트된다.
- 예를 들어, 수신할 요청이 많고 오로라 리더 인스턴스 두 개로 로드가 분산되어 있는 상황이다.
- CPU 사용량이 증가하면, 복제본 오토 스케일링을 설정할 수 있다.
- 결과적으로 두 개의 복제본이 더 추가되고 리더 엔드포인트가 자동으로 업데이트되고 확장된다.
- 예시에서 기억해야 하는 부분은 클라이언트가 라이터 엔드포인트에 연결되야 한다는 점이다.
- 리더 복제본을 찾기 위해서는 리더 엔드포인트에 연결되어야 한다.
Global Aurora
- Aurora Cross Region Read Replicas
- 재해 복구에 유용하게 사용된다.
- 간단하게 설치할 수 있다.
- Aurora Global Database (권장)
- 1개의 기본 리전이 있다. (읽기/쓰기)
- 최대 5개의 읽기 전용 보조 리전을 사용할 수 있으며, 복제 지연 시간이 1초 미만이다.
- 보조 리전당 최대 16개의 복제본 읽기를 생성할 수 있다.
- 대기 시간을 줄이는 데 도움이 된다.
- 하나의 리전에 문제가 생겼을 때, 다른 리전을 승격시키는데 1분 이내의 RTO를 보장한다.
- PostgreSQL용 오로라에서 RPO를 관리하는 기능을 사용할 수 있다.
- 일반적인 지역 간 복제에는 1초 미만이 소요된다.
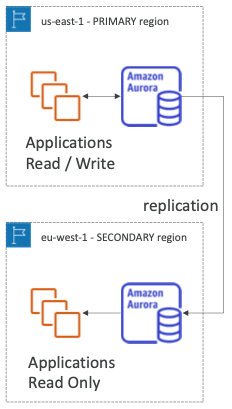
- 주요 리전(
us-east-1)에 있는 애플리케이션과 오로라 인스턴스가 있다. - 읽기 전용의 보조 리전(
us-west-1)에는 애플리케이션과 읽기 전용 오로라 인스턴스가 있다.
Unplanned Failover
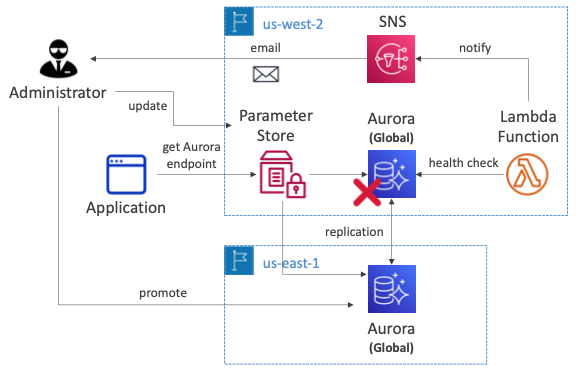
- 글로벌 데이터베이스가 있고 오로라 라이터 엔드포인트를 SSM Parameter Store에 저장한다.
- 어떤 데이터베이스에 연결하여 데이터를 쓸지 클라이언트가 이해하기 쉬워진다.
- 라이터 엔드포인트는
us-west-2를 가리키고 있으며 오로라의 기본 리전이다.- 장애가 발생할 경우 다른 리전을 기본 오로라 데이터베이스로 승격할 수 있어야 한다.
- 자동화를 적용하기 위해 오로라 데이터베이스에 대한 상태 확인을 수행하는 람다 함수를 만들 수 있다.
- 람다 함수는 상태 확인이 실패하는 경우 함수는 SNS 토픽에 알림을 전송하고 관리자에게 이메일을 보내게 된다.
- 만약 다운타임을 원하지 않는다면 수동으로 Parameter Store를 업데이트하여 새 라이터 엔드포인트를 추가하고 승격시킬 수 있다.
- Parameter Store에서 오로라 엔드포인트를 새로고침하기 위해서 애플리케이션 로직도 있어야 한다.
Global Application
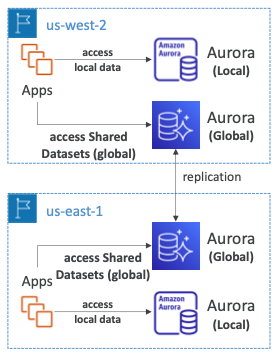
- 애플리케이션은 로컬 오로라 데이터베이스에 있는 리전에 특정된 로컬 데이터에 액세스한다.
- 글로벌 오로라 데이터베이스에서 글로벌 데이터 세트에 액세스할 수 있다.
- 두 데이터베이스 중 하나는 라이터가 되고 다른 하나는 리더가 된다.
Amazon ElastiCache
- RDS가 관리되는 관계형 데이터베이스를 얻는 것과 동일한 방식으로 관리되는 캐시를 얻을 수 있다.
- ElastiCache는 관리형 Redis 또는 관리형 Memcached다.
- 캐시는 매우 높은 성능과 낮은 지연 시간을 가진 인메모리 데이터베이스다.
- 읽기 집약적인 워크로드를 위해 데이터베이스의 부하를 줄이는 데 도움이 된다.
- 애플리케이션을 Stateless 상태로 만드는 데 도움이 된다.
- AWS에서 OS 관리/패치, 최적화, 설정, 구성, 모니터링, 장애 복구 및 백업 관리를 제공한다.
- ElastiCache를 사용하면 애플리케이션 코드가 크게 변경되어야 한다.
DB Cache
- 애플리케이션은 ElastiCache를 사용할 수 없는 경우 RDS에서 가져와 ElastiCache에 저장하도록 쿼리한다.
- RDS의 부하를 완화하는 데 도움이 된다.
- 캐시에 최신 데이터만 사용되도록 하려면 무효화 전략이 있어야 한다.
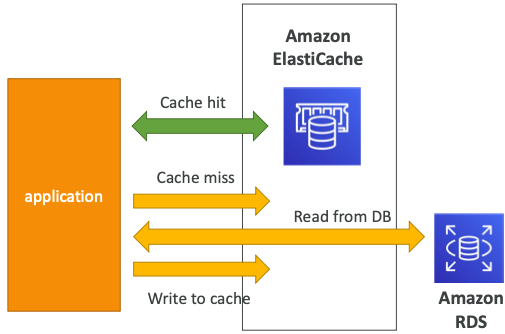
User Session Store
- 사용자가 애플리케이션에 로그인한다.
- 애플리케이션이 세션 데이터를 ElastiCache에 기록한다.
- 사용자가 우리 애플리케이션 중 다른 인스턴스에 요청을 전달한다.
- 인스턴스가 세션 저장소에서 데이터를 검색하고 사용자가 이미 로그인되어 있다고 판단한다.
Redis vs Memcached
- Redis
- Multi AZ와 함께 자동 Failover를 제공한다.
- 복제본 읽기를 통해 읽기를 확장하고 가용성이 높다.
- 지속적인 데이터 내구성을 제공하며 AOF (Append Only File), 백업 및 복원 기능을 제공한다.
- Memcached
- 데이터 파티셔닝을 위한 다중 노드(sharding)를 제공한다.
- 데이터가 비영구적이다.
- 백업 및 복원 기능이 없다.
- 멀티 스레드 아키텍처를 제공한다.
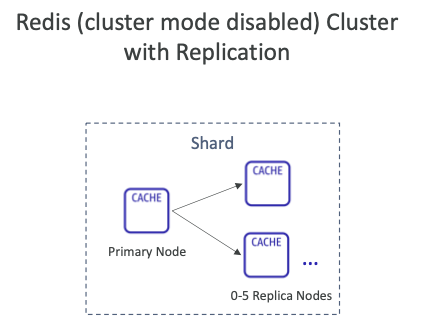
복제: 클러스터 모드 비활성화
- 기본 노드는 1개, 최대 5개의 복제본을 가질 수 있다.
- 비동기식 복제가 이루어진다.
- 기본 노드는 읽기/쓰기에 사용된다.
- 기본 노드를 제외한 노드들은 읽기 전용으로 사용된다.
- 하나의 샤드에 있는, 모든 노드는 모든 데이터를 가지고 있다.
- 노드 장애 시 데이터 손실을 방지할 수 있다.
- 장애 조치를 위해 기본적으로 다중 AZ가 활성화된다.
- 읽기 성능 확장에 도움이 된다.
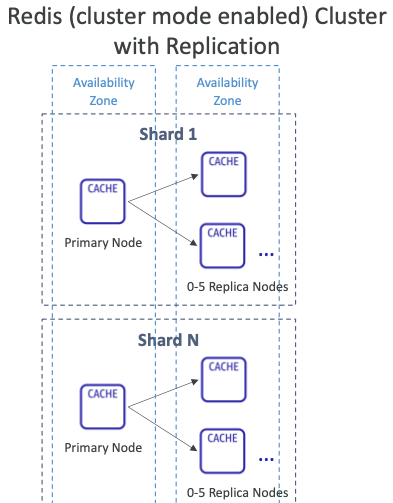
복제: 클러스터 모드 활성화
- 데이터가 여러 샤드로 분할되어 쓰기 확장에 도움이 된다.
- 각 샤드에는 기본 노드와 최대 5개의 복제본 노드가 있습니다. (클러스터 비활성화와 동일)
- 다중 AZ 기능이 제공된다.
- 클러스터당 최대 500개의 노드를 가질 수 있다.
- 단일 마스터 = 500개의 샤드
- 1개의 마스터 & 1개의 복제본 = 250개의 샤드
- 1개의 마스터 & 5개의 복제본 = 83개의 샤드
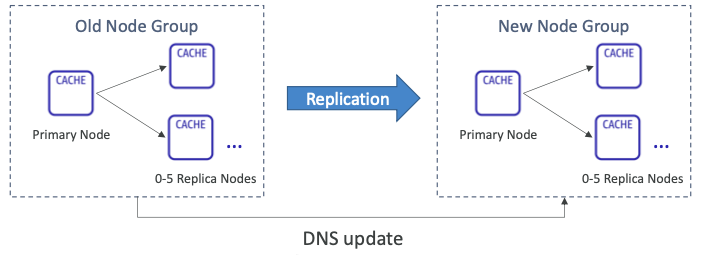
Redis 확장: 클러스터 모드 비활성화
- Horizontal:
- 읽기 전용 복제본을 추가/제거하여 수평 확장/축소한다. (최대 5개의 복제본)
- Vertical:
- 더 크거나 더 작은 노드 유형으로 확장/축소할 수 있다.
- ElastiCache는 내부적으로 새 노드 그룹을 생성한 후 데이터 복제 및 DNS 업데이트를 수행한다.
Redis 확장: 클러스터 모드 활성화
- 두 가지 모드가 있다.
- Online Scaling: 확장 프로세스 중에 요청을 계속 처리한다. (다운타임이 없고, 성능 저하 없음)
- Offline Scaling: 확장 프로세스(백업 및 복원) 중에는 요청을 처리할 수 없다.
추가 구성이 지원된다.(노드 유형 변경, 엔진 버전 업그레이드 등)
- Horizontal: 리샤딩 및 샤드 재분배
- Resharding: 샤드를 추가/제거하여 규모를 확장/축소한다.
- Shard Rebalancing: 샤드 간에 키스페이스를 최대한 균등하게 분배한다.
- 온라인 및 오프라인 확장을 지원한다.
- Vertical: 읽기/쓰기 용량 변경
- 더 크거나 더 작은 노드 유형으로 확장/축소한다.
- 온라인 확장만 지원한다.
Redis Auto Scaling
- 원하는 샤드 또는 복제본을 자동으로 늘리거나 줄인다.
- 대상 추적 및 예약된 확장 정책을 모두 지원한다.
- 클러스터 모드가 활성화된 Redis에서만 작동한다.
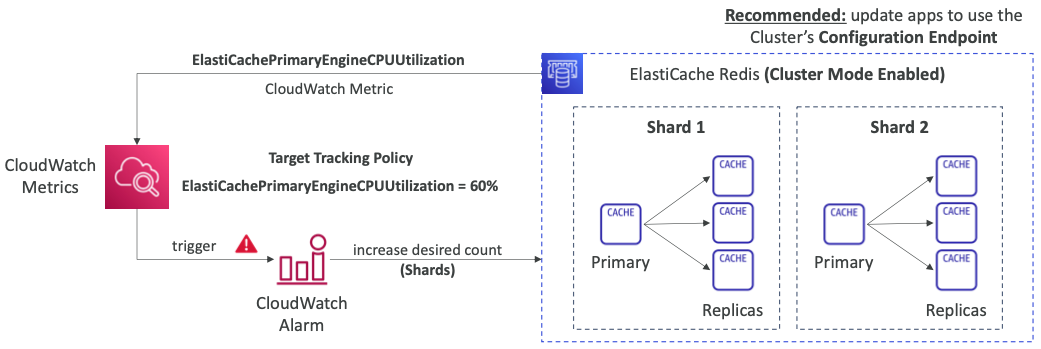
- 클러스터 모드가 활성화된 상태을 때 실제로 Redis용 오토 스케일링을 설정할 수 있다.
- 클러스터의 샤드나 복제본 수를 자동으로 늘리거나 줄일 수 있다.
- 대상 추적 및 예약 스케일링 정책을 모두 지원한다.
- 추적할 메트릭이 CPU 사용률이라고 가정한다.
- 대상 추적 정책을 사용하여 대상 CPU 사용률이 약 60%로 유지되도록 할 수 있다.
- 그러면 CloudWatch 알람을 트리거할 수 있고 알람은 클러스터의 샤드 수를 늘릴 수 있다.
- 애플리케이션이 클러스터에 연결하려면 클러스터의 구성 엔드포인트를 사용해야 한다.
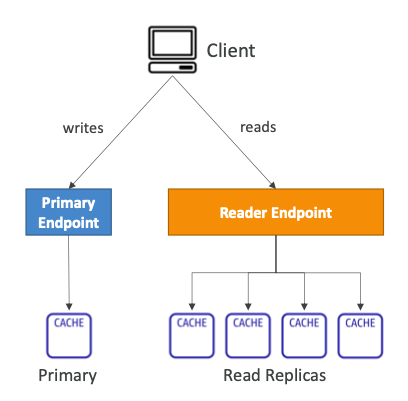
Redis Connection Endpoint
- Standalone Node
- 읽기 및 쓰기 작업을 위한 하나의 엔드포인트
- Cluster Mode Disabled Cluster
- Primary Endpoint: 모든 쓰기 작업용
- Reader Endpoint: 모든 읽기 전용 복제본에 읽기 작업을 균등하게 분할한다.
- Node Endpoint: 읽기 작업용
- Cluster Mode Enabled Cluster
- Configuration Endpoint: 클러스터 모드 활성화 명령을 지원하는 모든 읽기/쓰기 작업용
- Node Endpoint: 읽기 작업용
DynamoDB
- 완벽하게 관리되고 Multi-AZ에 걸쳐 복제가 가능한 고가용성(HA)을 제공한다.
- NoSQL 데이터베이스로 RDB가 아니지만 트랜잭션을 지원한다.
- 대규모 워크로드, 분산형 데이터베이스로 확장할 수 있다.
- 초당 수백만 개의 요청, 수조 개의 행, 100TB 스토리지를 지원한다.
- 빠르고 일관된 성능을 제공한다. (single-digit MS)
- 보안, 승인 및 관리를 위해 IAM과 통합된다.
- 저비용 및 자동 확장된다.
- 유지보수 또는 패치 적용이 없으므로 항상 사용할 수 있다.
- Standard & Infrequent Access(IA) 테이블 클래스를 지원한다.
Basics
- DynamoDB는 테이블로 구성되어 있다.
- 각 테이블에 Primary Key(기본키)가 있으며 생성 시 결정해야 한다.
- 각 테이블에는 무한한 수의 항목(rows)이 있을 수 있다.
- 각 항목에는 속성이 있으며 시간 경과에 따라 추가할 수 있고 값은
null일 수 있다. - 항목의 최대 크기는 400KB다.
- 지원되는 데이터 유형은 아래와 같다.
- Scalar Types: String, Number, Binary, Boolean, Null
- Document Types: List, Map
- Set Types: String Set, Number Set, Binary Set
- 따라서, DynamoDB에서는 스키마를 빠르게 진화시킬 수 있다.
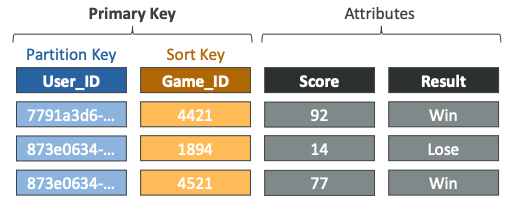
- 파티션 키와 선택적으로 정렬 키가 있으며 이 두 키가 기본 키를 구성하며 추가적으로 속성이 있다.
- 속성은
null이 될 수 있고 시간이 지남에 따라 추가할 수 있다.
Read/Write Capacity Modes
- 테이블의 용량(읽기/쓰기 처리량)을 관리하는 방법을 제어한다.
- Provisioned Mode (default)
- 초당 읽기/쓰기 횟수를 지정한다.
- 용량을 미리 계획해야 한다.
- RCU(Provisioned Read Capacity Units) 및 WCU(Write Capacity Units)에 대해 지불해야 한다.
- RCU 및 WCU에 대한 Auto-Scaling 모드를 추가할 수 있다.
- On-Demand Mode
- 워크로으데 따라 읽기/쓰기가 자동으로 확장한다.
- 용량을 계획할 필요가 없다.
- 사용하는 제품에 대한 비용을 더 많이 지불한다.
- 예측할 수 없는 워크로드, 급격한 워크로드 급증에 적합하다.
Accelerator (DAX)
- DynamoDB를 위한 완벽하게 관리되고 가용성이 뛰어난 원활한 인메모리 캐시다.
- 캐싱을 통해 읽기 혼잡을 해결할 수 있다.
- 캐시된 데이터에 대한 MS 단위의 대기시간을 보장한다.
- 애플리케이션의 로직 수정없이 기존 DynamoDB API와 호환된다.
- 캐시에 대한 5분(기본값) TTL을 가진다.
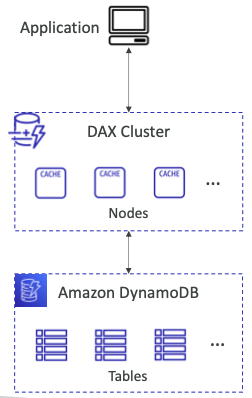
- DynamoDB 테이블과 애플리케이션이 있다.
- 몇 개의 캐시 노드로 구성된 DAX 클러스터를 만들고 이 DAX 클러스터에 연결한다.
- 내부적으로 DAX 클러스터가 DynamoDB 테이블에 연결된다.
Accelerator (DAX) vs ElastiCache
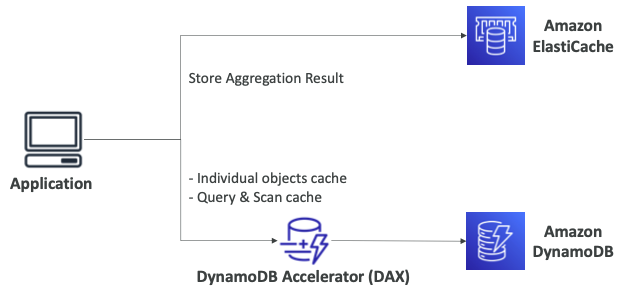
- DAX는 DynamoDB 앞에 있으며 개별 객체 캐시나 쿼리 및 스캔 캐시에 매우 유용하다.
- 하지만 집계 결과를 저장하려는 경우에는 ElastiCache가 적합하다.
- DynamoDB 위에서 실행한 매우 큰 계산을 저장할 때 유용하게 사용된다.
- 둘은 바로 교체하여 사용할 수 없고 사실상 서로 보완되는 서비스다.
- 대부분의 경우 DynamoDB 위에 솔루션을 캐싱하기 위해 DAX를 사용하게 된다.
Stream Processing
- 테이블의 항목 수준 수정(생성/수정/삭제) 순서가 매겨진 스트림이다.
- 사용 사례
- 실시간으로 변화에 대응 (예: 사용자 환영 이메일)
- 실시간 사용량 분석
- 파생 테이블에 삽입
- 리전 간 복제 구현
- DynamoDB 테이블 변경 시 AWS 람다 호출
- DynamoDB Streams:
- 24시간 보존
- 한정된 소비자(Consumer) 수를 가진다.
- AWS 람다 트리거 또는 DynamoDB Stream Kinesis 어댑터를 사용한 프로세스
- Kinesis Data Streams (신규):
- 1년 보존
- 높은 소비자(Consumer) 수를 가진다.
- AWS Lambda, Kinesis Data Analytics, Kinesis Data Firehose, AWS Glue Streaming ETL을 통한 프로세스...

- 애플리케이션은 DynamoDB 테이블에서 작업을 생성, 수정, 삭제하고 이는 DynamoDB Streams 또는 KDS가 된다.
- KDS를 사용하는 경우 스트림을 KDF에서 가져갈 수 있다.
- Redshift로 데이터를 보내서 분석할 수 있다.
- S3로 데이터를 보내서 아카이빙하거나 OpenSearch로 보내 인덱싱하거나 검색할 수 있다.
- DynamoDB Stream을 사용하면 처리 레이어가 있으며 DynamoDB KCL 어댑터를 사용하여 EC2 인스턴스나 람다 함수에서 애플리케이션을 실행할 수 있다.
- 여기에서 SNS에 알림을 보내거나 다른 DynamoDB 테이블에 필터링과 변환을 실행한다.
- 처리 레이어를 사용하여 OpenSearch로 데이터를 보내는 등의 원하는 작업을 할 수 있다.
Global Tables
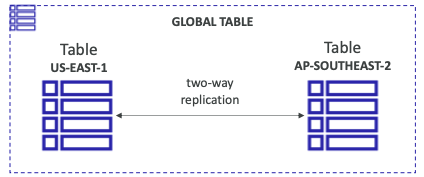
- 여러 리전에서 짧은 대기 시간으로 DynamoDB 테이블에 액세스할 수 있다.
- Active-Active 복제로 양방향 복제가 이루어진다.
- 애플리케이션은 모든 리전에서 테이블을 읽고 쓸 수 있다.
- 필수적으로 DynamoDB Streams를 사용하도록 설정해야 한다.
Time To Live (TTL)
- 만료 타임스탬프 이후 항목을 자동으로 삭제한다.
- 활용 사례: 최신 항목만 유지하여 저장된 데이터를 줄이고, 규제 의무 준수, 웹 세션 처리 등이 있다.
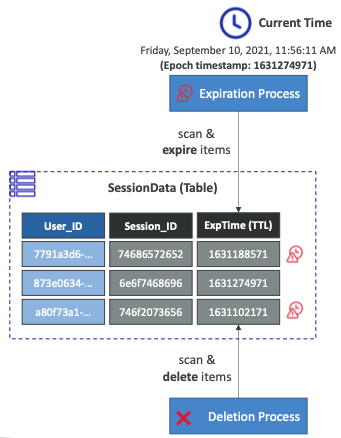
- SessionData라는 테이블이 있고 마지막 속성으로 TTL을 의미하는 속성인 ExpTime이 추가된다.
- TTL이 추가되면 Epoch 타임스탬프의 현재 시간이 ExpTime 열을 초과하게 되는 즉시 자동으로 항목이 만료되고 삭제 프로세스를 통해 최종적으로 삭제된다.
- 따라서 데이터 테이블의 항목이 일정 시간이 지나면 삭제된다.
재해 복구(Disaster Recovery)를 위한 백업
- PITR(Point-In-Time Recovery)을 사용한 지속적인 백업
- 지난 35일 동안 옵션으로 활성화할 수 있다.
- 백업 윈도우 내에서 언제든지 시점 단위로 복구가 가능하다.
- 복구 프로세스를 통해 새 테이블을 생성할 수 있다.
- On-Demand 백업
- 명시적으로 삭제될 때까지 장기 보존을 위한 전체 백업을 진행한다.
- 성능이나 대기 시간에 영향을 주지 않는다.
- AWS Backup에서 구성 및 관리가 가능하다. (지역 간 복사 가능)
- 복구 프로세스가 새 테이블을 생성한다.
Amazon S3와 통합
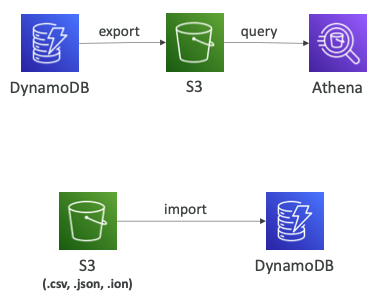
- S3로 데이터 내보내기(Export, PITR 활성화 필수)
- 지난 35일 동안 모든 시점에서 작업이 가능하다.
- 테이블의 읽기 용량에 영항을 주지 않는다.
- DynamoDB 위에서 데이터 분석 수행이 가능하다.
- 감사(Auditing)용 스냅샷을 보관할 수 있다.
- JSON, ION 형식으로 데이터를 내보낼 수 있다.
- S3에서 데이터 가져오기(Import)
- CSV, DynamoDB JSON, ION 형식으로 데이터를 가져올 수 있다.
- 쓰기 용량을 전혀 사용하지 않는다.
- 새로운 테이블을 생성한다.
- 오류가 발생하는 경우 CloudWatch Logs에 기록된다.
Database Migration Service (DMS)
- 데이터베이스를 AWS로 빠르고 안전하게 마이그레이션할 수 있으며, 복원력이 뛰어난 자가복구 기능을 제공한다.
- 마이그레이션하는 동안 소스 데이터베이스를 계속 사용할 수 있다.
- 동종 마이그레이션을 지원한다.
- 예를 들어, Oracle에서 Oracle 데이터베이스로 마이그레이션할 수 있다.
- 이기종 마이그레이션을 지원한다.
- 예를 들어, Microsoft SQL Server에서 Aurora로 마이그레이션할 수 있다.
- CDC를 사용하여 연속된 데이터 복제를 지원한다.
- 복제 작업을 수행하려면 EC2 인스턴스를 생성해야 한다.
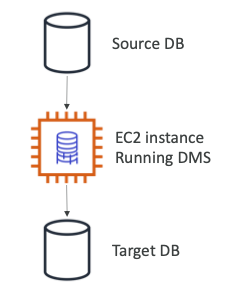
- 소스 데이터베이스는 온프레미스 서버에 있다.
- EC2 인스턴스를 생성하여 DMS 소프트웨어를 실행하면 대상 데이터베이스에 데이터를 삽입한다.
Source & Target
- Source
- 온프레미스와 EC2 인스턴스 데이터베이스: Oracle, MSSQL Server, MySQL, MariaDB, PostgreSQL, MongoDB, SAP, DB2
- Azure: Azure SQL Database
- Amazon RDS: Aurora를 포함한 모든 종류의 엔진
- Amazon S3
- DocumentDB
- Target
- 온프레미스와 EC2 인스턴스 데이터베이스: Oracle, MSSQL Server, MySQL, MariaDB, PostgreSQL, SAP
- Aurora를 포함한 모든 종류의 엔진
- Amazon Redshift
- Amazon DynamoDB
- Amazon S3
- OpenSearch Service (Source로 사용될 수 없음)
- Kinesis Data Streams (Source로 사용될 수 없음)
- DocumentDB
Schema Conversion Tool (SCT)
- 데이터베이스 스키마를 한 엔진에서 다른 엔진으로 변환할 때 사용된다.
- OLTP의 경우 SQL Server나 Oracle에서 MySQL로 변환하거나, PostgreSQL에서 Aurora로 변환할 수 있다.
- OLAP의 경우 Teradata나 Oracle에서 Redshift로 변환할 수 있다.
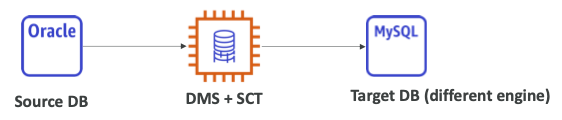
- SCT는 DMS와 함께 실행되어 소스의 데이터베이스에서 타겟으로 스키마를 변환한다.
- 동일한 DB 엔진을 마이그레이션하는 경우에는 SCT를 사용할 필요가 없다.
- 예를 들어, 온프레미스에서 사용하는 PostgreSQL DB를 RDS PostgreSQL로 마이그레이션하는 경우 동일한 엔진이므로 SCT를 사용할 필요가 없다.
Continuous Replication
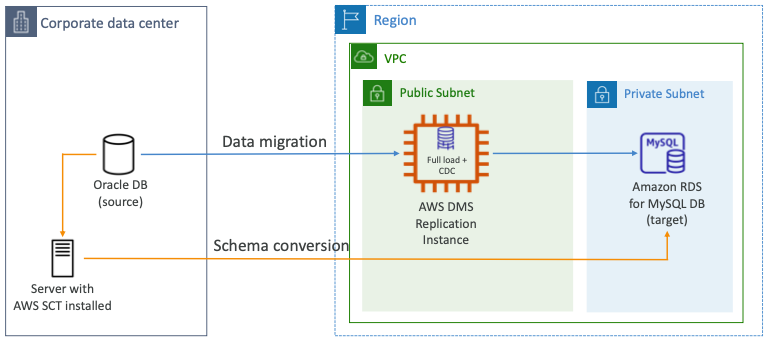
- Oracle 데이터베이스를 소스로 사용하는 기업 데이터 센터가 있고, 마이그레이션 대상으로는 MySQL DB용 RDS 데이터베이스가 있다.
- 서로 다른 유형의 데이터베이스이므로 여기서는 SCT를 사용해야 한다.
- AWS SCT가 설치된 서버를 설정하고 온프레미스에 설정할 수 있다.
- MySQL을 실행하는 RDS 데이터베이스로 스키마 변환을 실행한다.
- 지속적 복제를 위해 전체 로드와 CDC(Change Data Capture)를 실행할 DMS 복제 인스턴스를 설정할 수 있다.
- 온프레미스 데이터베이스인 소스 Oracle 데이터베이스를 읽고 프라이빗 서브넷에 데이터를 삽입하여 데이터 마이그레이션을 실행한다.
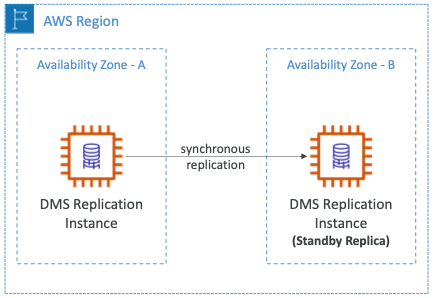
Multi-AZ Deployment
- 다중 AZ가 활성화되면 DMS는 다른 AZ에 동기식 스탠드 복제본을 프로비저닝하고 유지한다.
- 아래와 같은 장점이 있다.
- 데이터 중복성을 제공한다.
- I/O 중단을 제거한다.
- 지연 시간 급증을 최소화한다.
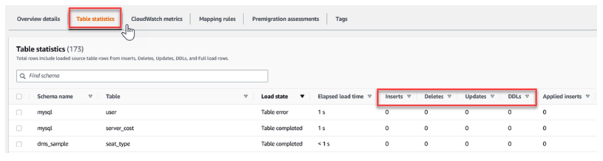
Replication Task Monitoring
- Task Status
- 작업 상태를 나타낸다. (예: 생성 중, 실행 중, 중지됨 등..)
- 작업 상태 표시줄(Task Status Bar)은 작업 진행 상황을 추정한다.
- Table State
- 테이블의 현재 상태를 포함한다. (예: 로드 전, 테이블 완료 등..)
- 각 테이블의 삽입, 삭제 및 수정 수를 확인할 수 있다.
CloudWatch Metrics
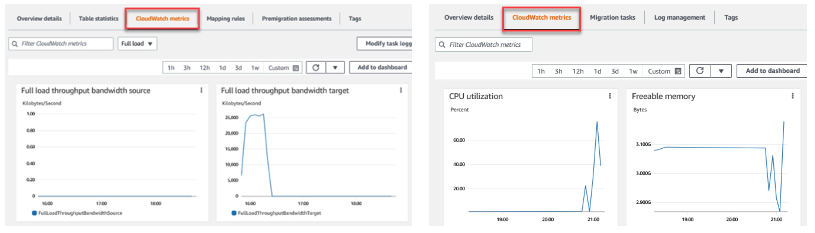
- DMS에서 얻을 수 있는 CloudWatch 지표가 있다.
- 복제 작업 지표(Replication Task Metrics)에서는 대역폭 등을 확인할 수 있다.
- 호스트 지표(Host Metrics)에서는 CPU 사용률이나 사용 가능한 메모리를 확인할 수 있다.
- 따라서 호스트 지표는 복제 호스트의 성능과 사용률 통계를 나타낸다.
- 지표에 대한 자세한 내용은 공식 홈페이지를 확인한다.
- Host Metrics
- 복제 호스트에 대한 성능 및 활용도 통계를 확인한다.
CPUUtilization,FreeableMemory,FreeStorageSpace,WriteIOPS등이 있다.
- Replication Task Metrics
- 수신 및 커밋된 변경 사항, 복제 호스트와 소스 및 대상 데이터베이스 간의 대기 시간을 포함한 복제 작업에 대한 통계를 제공한다.
FullLoadThroughputRowsSource,FullLoadThroughputRowsTarget,CDCThroughputRowsSouce,CDCThroughputRowsTarget등이 있다.
- Table Metrics
- 삽입, 수정, 삭제, DDL 완료 횟수 등 마이그레이션 진행 중인 테이블에 대한 통계를 제공한다.
Replication (CRR & SRR)
- 소스 및 대상 버킷에서 버전 관리를 활성화해야 한다.
- CRR은 Cross-Region Replication의 약자로 교차 지역 복제를 의미한다.
- SRR은 Same-Region Replication의 약자로 동일 지역 복제를 의미한다.
- 버킷은 다른 AWS 계정에 있을 수 있다.
- 복사는 비동기 방식으로 이루어진다.
- S3에 적절한 IAM 권한을 부여해야 한다.
- 사용 사례
- CRR: 규정 준수, 짧은 지연 시간 액세스, 교차 계정 복제
- SRR: 로그 집계, 운영 계정과 테스트 계정 간의 실시간 복제
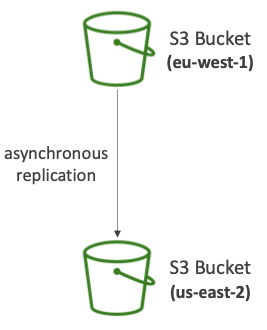
- 복제를 활성화한 후에는 새롭게 생성되는 객체만 복제된다.
- 선택적으로 S3 배치 복제를 사용하여 기존 객체를 복제할 수 있다.
- 기존 객체 및 복제에 실패한 객체를 복제한다.
- DELETE 작업의 경우
- 소스에서 타겟으로 삭제 마커를 복제할 수 있다. (선택적으로 설정 가능)
- 버전 ID가 있는 삭제는 복제되지 않는다. (악의적인 삭제를 방지하기 위해)
- 복제 체인 연결이 없다.
- 버킷 1이 버킷2로 복제되고 버킷 3으로 복제되는 경우
- 버킷 1에서 생성된 객체는 버킷 3에 복제되지 않는다.
AWS Storage Gateway
Hybrid Cloud for Storage
- AWS는 "하이브리드 클라우드"를 추진하고 있다.
- 인프라의 일부는 클라우드에 있다.
- 인프라의 일부는 온프레미스에 있다.
- 아래와 같은 여러 이유 때문에 이러한 구성을 유지해야 할 수 있다.
- 장기간의 클라우드 마이그레이션
- 보안 요구 사항
- 규정 준수 요구 사항
- IT 전략
- S3는 EFS/NFS와 달리 독점 스토리지 기술이다. 이러한 S3 데이터를 온프레미스에 노출하기 위해서 AWS Storage Gateway가 사용된다.
Storage Cloud Option
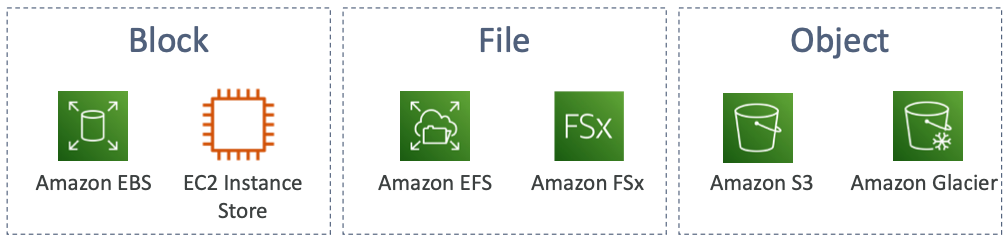
- EBS나 EC2 인스턴스 스토어는 블록 스토리지다.
- EFS나 FSx같은 파일 시스템도 있고, S3나 Glacier같은 객체 수준의 저장소도 있다.
Storage Gateway
- 온프레미스 데이터와 클라우드 데이터 간의 연결을 셍성한다.
- 재해 복구, 백업 및 복원, 계층형 스토리지, 온프레미스 캐시 및 지연 시간이 짧은 파일 액세스와 같은 작업에 사용된다.
- 총 4개의 Storage Gateway가 있다.
- S3 File Gateway
- FSx File Gateway
- Volume Gateway
- Tape Gateway
RefreshCache API
- 파일 게이트웨이에 파일을 쓸 때, Storage Gateway는 파일 공유 캐시를 자동으로 업데이트한다.
- 파일을 S3 버킷에 직접 업로드하면 파일 게이트웨이에 연결된 사용자가 파일 공유의 파일을 볼 수 없다.
RefreshCacheAPI를 호출해야 한다.
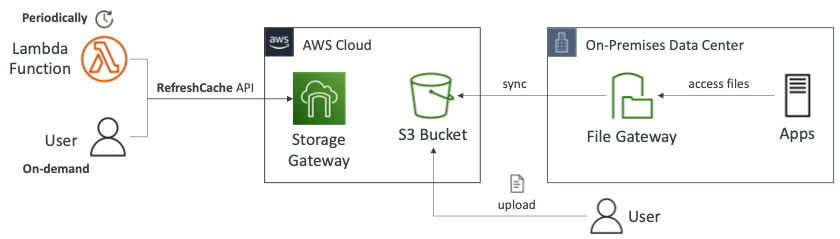
- 파일 게이트웨이는 S3로 지원되므로 사용자에게 노출할 수 있는 파일 목록이 있다.
- 사용자가 파일을 파일 게이트웨이에 직접 쓰면 해당 파일이 S3 버킷에 동기화되며 파일 게이트웨이는 이 파일에 관해 알고 있다.
- 사용자가 파일을 S3 버킷으로 직접 업로드하면 파일 게이트웨이에서는 이를 바로 알지 못한다.
- 따라서 파일 게이트웨이에 오래된 데이터가 있을 수 있다.
- 람다 함수나 온디맨드 사용자가
RefreshCacheAPI 호출을 통해서 캐시를 새로고침할 수 있다.
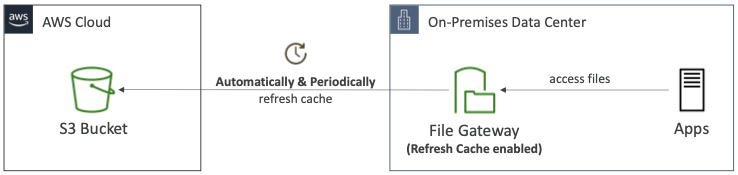
Automating Cache Refresh
- Automated Cache Refresh: 파일 게이트웨이는 캐시를 자동으로 새로 고쳐 S3 버킷의 변경 사항을 최신 상태로 유지할 수 있는 파일 게이트웨이 기능이다.
- 사용자가 파일 공유에 있는 오래된 데이터에 액세스하지 않는지 확인할 수 있다.
RefreshCacheAPI를 수동 및 주기적으로 호출할 필요가 없다.
참고한 강의
'Infrastructure > Certificate' 카테고리의 다른 글
| [DOP] Monitoring & Logging (0) | 2024.02.01 |
|---|---|
| [DOP] Resilient (Resilient Cloud Solutions) (0) | 2024.01.31 |
| [DOP] Route 53 (Resilient Cloud Solutions) (0) | 2024.01.29 |
| [DOP] Kinesis (Resilient Cloud Solutions) (0) | 2024.01.29 |
| [DOP] Container Orchestration (Resilient Cloud Solutions) (0) | 2024.01.29 |



