Incident & Event Response
- 이번 장에서는 DevOps Engineer Professional (DOP) 을 준비하며 "사고와 이벤트 대응"에 대해서 알아보도록 한다.
Amazon EventBridge
- 예약된 스크립트를 실행하여 Cron 작업을 실행할 수 있다.

- 서비스가 수행하는 것에 대응하기 위한 이벤트 규칙을 생성할 수 있다.

- 람다 함수를 트리거하거나 SQS/SNS로 메시지를 전송할 수 있다.
EventBridge Rules
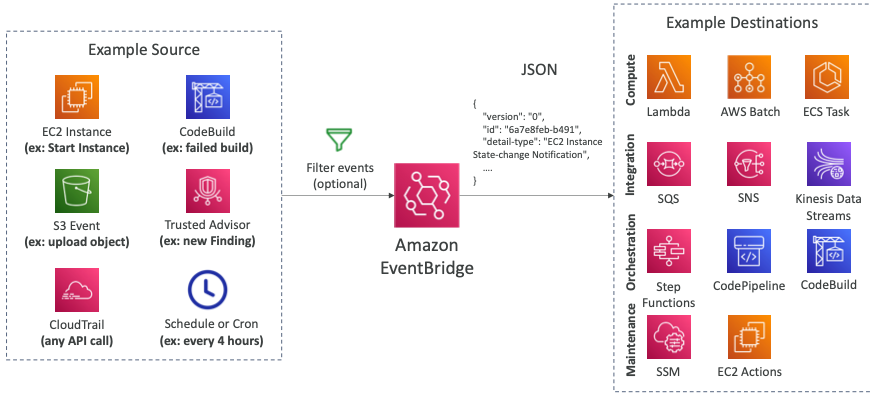
- 이벤트를 수집할 수 있는 여러 소스가 있다.
- EC2 인스턴스 (인스턴스 실행)
- CodeBuild (빌드 실패)
- S3 Event (객체 업로드)
- Trusted Advisor (새로운 보안 이슈 발견)
- CloudTrail (모든 종류의 API 호출)
- Schedule 또는 Cron (일정 시간 간격)
- 이러한 이벤트들은 EventBridge로 전송되며 필요한 경우 필터를 사용할 수 있다.
- EventBridge는 이벤트에 대한 세부사항을 보여주는 JSON 파일을 생성한다.
- 이러한 JSON 파일은 수많은 목적지로 전송될 수 있다.
Event Bus
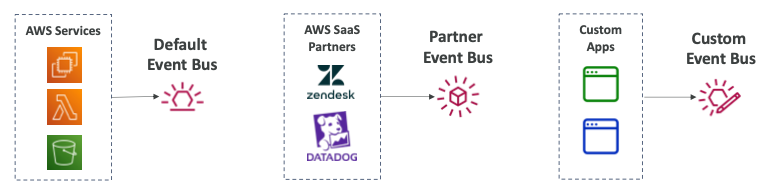
- AWS에서 제공하는 서비스는 Default 이벤트 버스로 전송된다.
- AWS SaaS 파트너 서비스는 Partner 이벤트 버스로 전송된다.
- 커스텀 애플리케이션은 Custom 이벤트 버스로 전송된다.
- 다른 AWS 계정에서 리소스 기반 정책을 사용하여 이벤트 버스에 액세스할 수 있다.
- 이벤트 버스로 전송된 이벤트를 아카이브할 수 있다.
- 이벤트는 필터링될 수 있으며 아카이브되는 이벤트는 저장 기간을 설정할 수 있다.
- 보관된 이벤트를 재생하는 기능을 제공한다.
Schema Registry
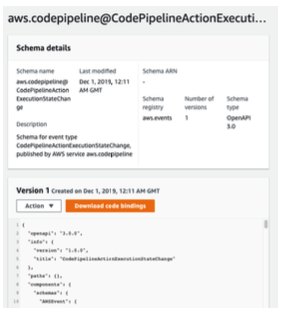
- EventBridge는 버스의 이벤트를 분석하여 스키마를 추론할 수 있다.
- 스키마 레지스트리를 사용하면 애플리케이션에 대한 코드를 생성할 수 있으므로 이벤트 버스에서 데이터가 어떻게 구성되는지 미리 알 수 있다.
- 스키마의 버전을 관리할 수 있다.
Resource-based Policy
- 특정 이벤트 버스에 대한 사용 권한을 관리할 수 있다.
- 예를 들어, 다른 AWS 계정 또는 AWS 리전의 이벤트를 허용하거나 거부할 수 있다.
- AWS 조직의 모든 이벤트를 단일 AWS 계정 또는 AWS 리전에서 집계하는 작업 등에 사용된다.

S3 Event Notifications
- S3:ObjectCreated, S3:ObjectRemoved, S3:ObjectRestore, S3:Replication 등의 이벤트를 발생시킬 수 있다.
- 객체 이름을 필터링할 수 있다. (예:
*.jpb)
- 이미지 썸네일 생성하여 S3에 업로드하는 작업 등에 사용된다.
- 원하는 만큼의 "S3 Event"를 생성할 수 있다.
- "S3 Event Notifications"는 일반적으로 몇 초 안에 이벤트를 전달하지만 때로는 1분 이상 소요될 수 있다.
IAM Permissions
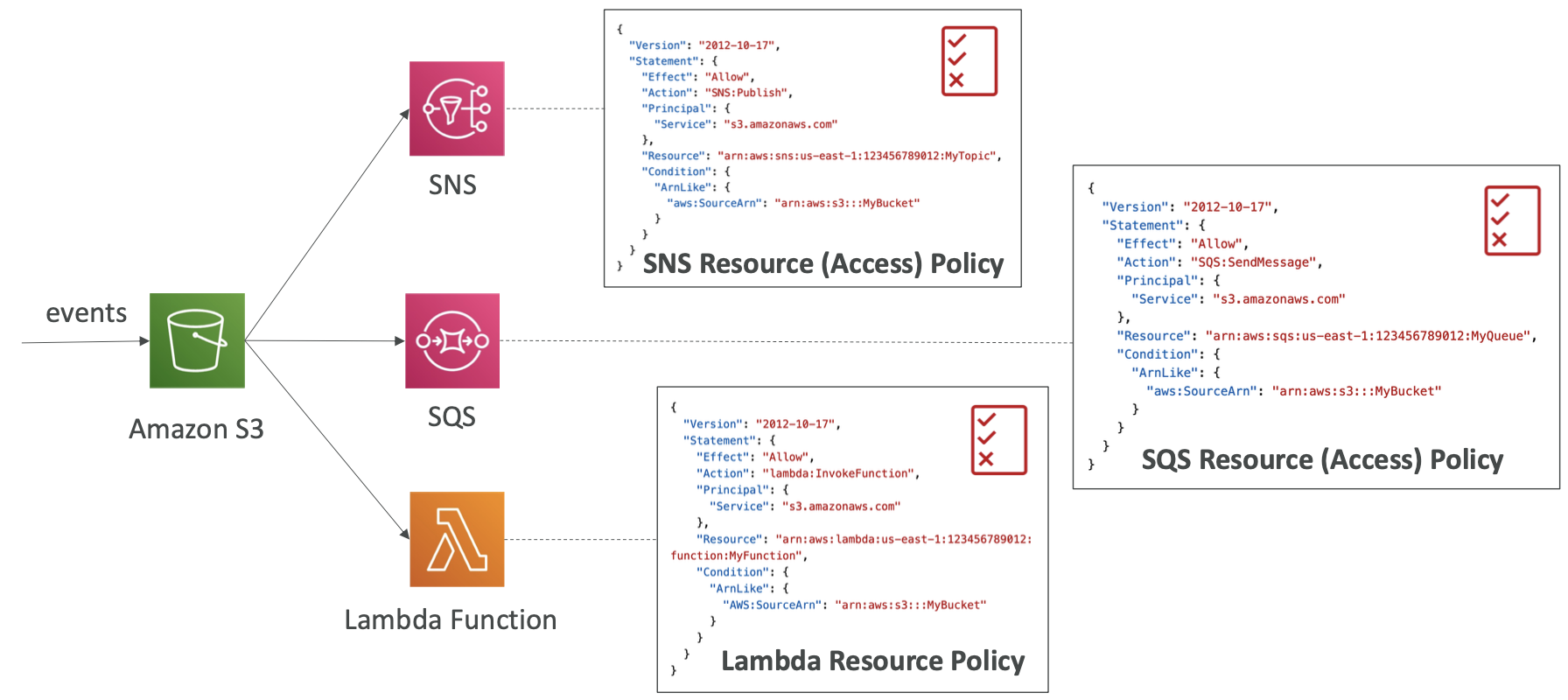
- 이벤트 알림이 작동하려면 IAM 사용 권한이 필요하다.
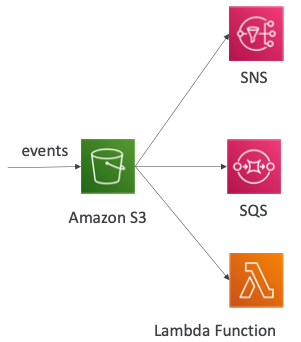
- S3 서비스는 SNS 토픽에 데이터를 전송할 수 있다.
- 이를 위해서는 SNS 리소스에 액세스 정책을 연결해야 한다.
- SNS 토픽에 연결하는 IAM 정책이 있고 S3 버킷은 이 정책을 통해 SNS 토픽에 바로 메시지를 전송할 수 있다.
- SQS를 사용할 때도 마찬가지로 SQS 리소스 액세스 정책을 생성해서 S3 서비스가 SQS 대기열에 데이터를 전송할 수 있도록 권한을 주어야 한다.
- 람다 함수의 경우에도 람다 리소스 정책을 람다 함수에 연결해서 S3가 함수를 호출할 권한을 갖도록 해야 한다.
- 이처럼 S3에 IAM 역할을 사용하지 않고 리소스 액세스 정책을 SNS 토픽, SQS 큐, 람다 함수에 대해 정의할 수 있다.
- 이러한 정책의 작동 방식은 S3 버킷 정책과 유사하다.
EventBridge와의 통합
- 이벤트들은 S3 버킷으로 간 다음 모든 이벤트는 결국 EventBridge로 가게 된다.
- EventBridge에서 이러한 규칙에 따라 이벤트를 18개 이상의 AWS 서비스로 전송할 수 있다.
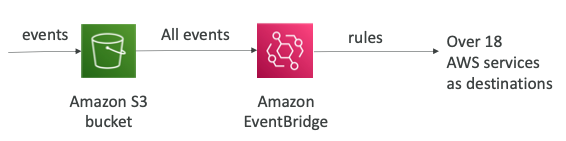
- JSON 규칙을 사용한 고급 필터링 옵션을 제공한다. (메타데이터, 객체의 크기, 이름 등)
- 여러 대상을 제공한다. (Step Functions, Kinesis Stream / Firehose 등)
- Event Bridge 기능: 아카이브, 이벤트 재생, 신뢰성 있는 제공
객체 무결성 (Object Integrity)
- S3에 객체를 업로드하면 업로드한 객체가 이전의 객체와 동일한지 확인이 필요하다.
- MD5 체크섬을 사용할 수 있다.
- 즉, 바이트로 이루어진 파일에 체크섬 알고리즘을 실행해 검사한다.
- 특정 길이의 문자열을 제공하고 이 문자열은 특정 파일에 고유해야 한다.
- 파일을 업로드한 사용자가 자신의 컴퓨터에서 MD5를 계산하고 S3는 서버에서 MD5를 계산한다.
- 두 MD5가 일치하면 업로드한 객체는 서버와 컴퓨터에서 동일하다고 할 수 있다.
- S3가 업로드를 수락하는지 거부하는지 확인하기 위해 HDP 요청 시 헤더에
Content-MD5를 추가할 수 있다.

- 반대로 S3에 있는 객체를 다운로드한 후에 비교하거나 사용자가 가진 사본이 온라인과 같은지 확인하는 경우도 있다.
- 이때 S3는 객체에 Etag를 사용한다.
- SSE-S3를 사용하는 경우에 Etag는 MD5 해시 또는 체크섬과 동일하다.
- API 호출 GetObject 메타데이터를 이용해 객체 자체가 아니라 Etag만 다운로드 한다.
- Etag를 로컬 버전의 객체와 비교하고 로컬 버전 대해서는 MD5를 계산할 수 있다.
- 두 개가 일치하면 S3에 있는 객체와 동일하다는 의미이고 일치하지 않으면 객체가 다르다는 의미이다.

- MD5 외의 체크섬도 지원된다.
- SHA-1, SHA-256, CRC32, CRC32C 등이 있다.
AWS Health Dashboard
- 모든 지역, 모든 서비스 상태를 표시한다.
- 매일의 기록 정보를 표시한다.
- 구독할 수 있는 RSS 피드가 있다.
- 이전에는 "AWS 서비스 Heath Dashboard"라고 불렀다.
- 이전에는 "AWS Personal Health Dashboard (PHD)"로 불렸다.
- "AWS Account Health Dashboard"는 AWS의 사용자에게 영향을 줄 수 있는 이벤트가 발생할 때 경고 및 해결 지침을 제공한다.
- 서비스 상태 대시보드에는 AWS 서비스의 일반 상태가 표시되지만, 계정 상태 대시보드는 AWS 리소스의 기반이 되는 AWS 서비스의 성능과 가용성에 대한 맞춤형 보기를 제공한다.
- 대시보드는 진행 중인 이벤트를 관리하는 데 도움이 되는 관련 정보를 시기적절하게 표시하고 예정된 활동을 계획하는 데 도움이 되는 사전 알림을 제공한다.
- 글로벌 서비스로 전체 AWS 조직에서 데이터를 집계할 수 있다.
- AWS 중단이 사용자와 사용자의 AWS 리소스에 어떤 직접적인 영향을 미치는지 보여준다.
- 경고, 해결, 사전 예방적, 예정된 활동을 확인할 수 있다.
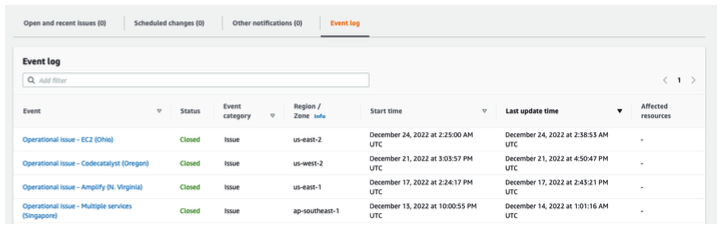
Health Event Notification
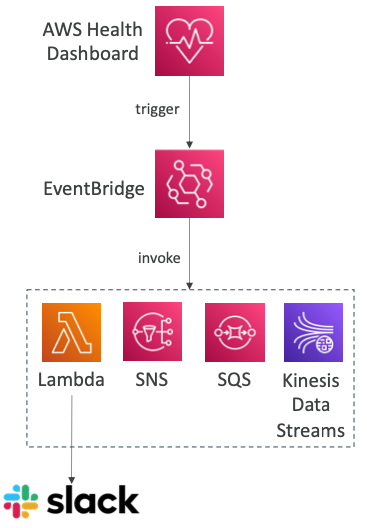
- EventBridge를 사용하여 AWS 계정의 AWS 상태 이벤트 변경 사항에 대응할 수 있다.
- 예를 들어, AWS 계정의 EC2 인스턴스 업데이트가 예약되면 이벤트 알림을 받는다.
- 이는 계정 이벤트(계정에 영향을 받는 리소스) 및 공개 이벤트(서비스의 지역적 가용성)에 대해 가능하다.
- 사용 사례: 알림 보내기, 이벤트 정보 캡처, 시정 조치 수행 등..
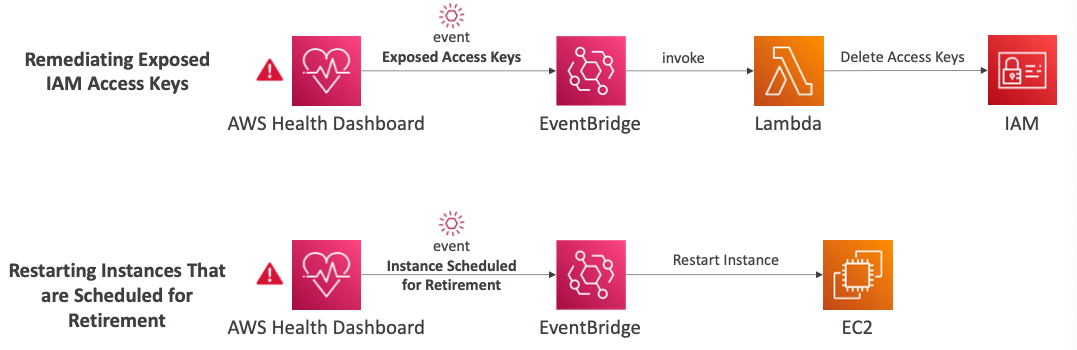
- 상태 대시보드에서 IAM 키가 노출된 이벤트가 발생했다고 가정한다.
- 상태 대시보드는 EventBridge를 트리거하고 이 이벤트에 대해 람다 함수를 통합한다.
- 그러면 람다 함수는 자동으로 액세스 키를 삭제해서 문제를 해결한다.
- 또 다른 예시로 EC2에서 일부 인스턴스가 만료 예정인 경우다.
- 우리는 인스턴스를 다시 시작하기만 하면 된다.
- AWS 상태 대시보드에서 만료 예정된 인스턴스에 대해 EventBridge의 이벤트를 트리거한다.
- 그런 다음 EventBridge에서 이벤트를 조작하고 EC2 태스크로 인스턴스를 바로 다시 시작할 수 있다.
상태 확인(Status Checks)
- 하드웨어 및 소프트웨어 문제를 식별하기 위한 자동화된 검사를 지원한다.
- System Status Checks
- AWS 시스템(소프트웨어/하드웨어, 물리적 호스트, 시스템 전원 손실 등)의 문제를 모니터링한다.
- 인스턴스 호스트에 대한 AWS의 예정된 중요 유지 관리가 있는지 "Personal Health Dashboard"에서 확인할 수 있다.
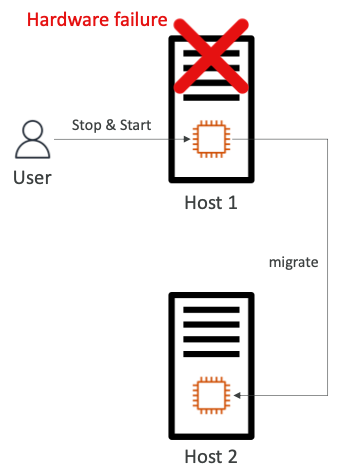
- 해결방법은 인스턴스를 중단(Stop)하고 다시 시작한다. 이때 인스턴스가 새로운 호스트로 마이그레이션 된다.
- 다른 호스트로 마이그레이션되기 때문에 인스턴스가 재실행되는 경우에 Public IP가 변경되는 것이다.
- 시스템 상태 확인은 인스턴스가 실행되는 AWS 시스템을 모니터링한다.
- 네트워크 연결 끊김
- 시스템 전원 손실
- 물리적 호스트의 소프트웨어 문제
- 네트워크 연결 가능성에 영향을 미치는 물리적 호스트의 하드웨어 문제
- AWS가 호스트를 수정할 때까지 기다리거나, 또는 EC2 인스턴스를 새 호스트로 이동 (Stop & Start, EBS가 지원되는 경우)
- Instance Status Checks
- 인스턴스의 소프트웨어/네트워크 구성을 모니터링한다. (잘못된 네트워크 구성, 소모된 메모리 등..)
- 해결방법은 인스턴스를 재부팅하거나 인스턴스의 구성을 변경한다.
- 인스턴스 상태 확인은 개별 인스턴스의 소프트웨어 및 네트워크 구성을 모니터링한다.
- 잘못된 네트워킹 또는 시작 구성
- 메모리 고갈
- 손상된 파일 시스템
- 호환되지 않는 커널
- 이러한 문제를 해결하기 위해서는 사용자의 참여가 필요하다.
- 인스턴스를 재실행하거나 인스턴스 구성을 변경해야 한다.
CW Metrics & Recovery
- CloudWatch Metrics (1분 주기)
StatusCheckFailed_SystemStatusCheckFailed_InstanceStatusCHeckFailed (둘 다 해당)
- 시스템 복구를 위한 두 가지 옵션이 있다.
- 옵션 1: CloudWatch Alarm
- 동일한 Private/Public IP, EIP, 메타데이터 및 배치 그룹을 사용하여 EC2 인스턴스를 복구한다.
- SNS를 통해서 알림을 전송한다.
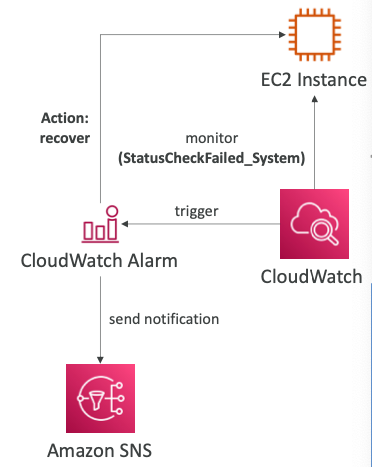
- EC2 인스턴스에서 CloudWatch 지표를 모니터링한다.
- 예를 들어,
StatusCheckFailed_System을 모니터링할 수 있다.
- CloudWatch 지표 상태가 1로 바뀌면 CloudWatch 알람이 트리거되고 CloudWatch 알람은 EC2 인스턴스를 적절히 배치해서 복구하는 조치를 수행한다.
- 옵션 2: Auto Scaling Group
- 최소/최대/원하는 인스턴스의 양을 설정한 상태로 유지하도록 도와주지만 "CloudWatch Alarm"을 통한 복구와는 다르게 동일한 Private/Elastic IP는 유지하지 않는다.
- 동일한 EBS 볼륨도 지원하지 않는다.
- EC2 인스턴스 하나를 복구하는 경우라면 옵션 1이 선호된다.

- EC2 인스턴스에 문제가 발생하면 인스턴스는 ASG에 의해 종료되는데 최소, 최대 크기와 원하는 크기를 1로 지정했기 때문에 새 EC2 인스턴스가 동일한 ASG에서 시작된다.
- 이 경우 EBS 볼륨이 동일하지 않고 Private IP, Elastic IP도 동일하지 않지만 적어도 인스턴스는 복구되고 실행된다.
- 자동화가 효과적으로 이루어지면 상태도 복구할 수 있다.
- 이처럼 두 가지 옵션이 있지만 특정 EC2 인스턴스가 중요한 경우 첫 번째 옵션이 훨씬 선호된다.
AWS CloudTrail
- AWS 계정에 대한 거버넌스, 컴플라이언스 및 감사(Audit)를 제공한다.
- CloudTrail은 기본적으로 활성화되어 있다.
- 아래의 항목들을 통해서 AWS 계정 내에서 발생한 이벤트 및 API 호출 기록을 확인할 수 있다.
- Console, SDK, CLI, AWS Service
- CloudTrail의 로그를 CloudWatch Logs 또는 S3에 저장할 수 있다.
- 모든 리전(기본값) 또는 단일 리전에 적용될 수 있다.
- AWS에서 의도치 않게 리소스가 삭제된 경우 CloudTrail을 확인하면 빠르게 원인을 파악할 수 있다.
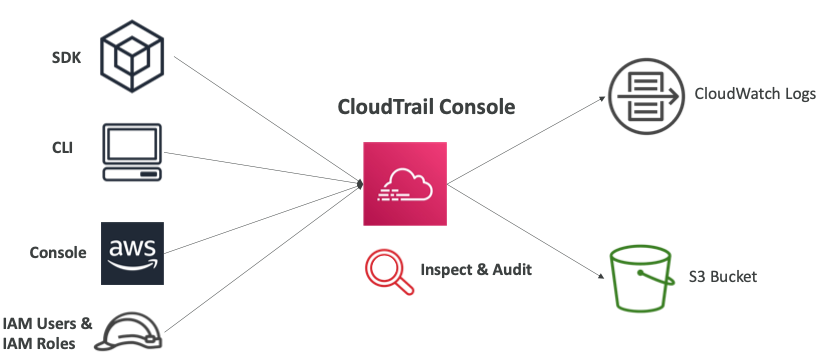
- CloudTrail이 중앙에 있고, SDK, CLI, Consol, IAM 유저, IAM 역할 혹은 다른 서비스의 동작들이 CloudTrail Console에 표시된다.
- 표시되는 정보를 기반으로 어떤 작업이 있었는지 조사하거나 감사할 수 있다.
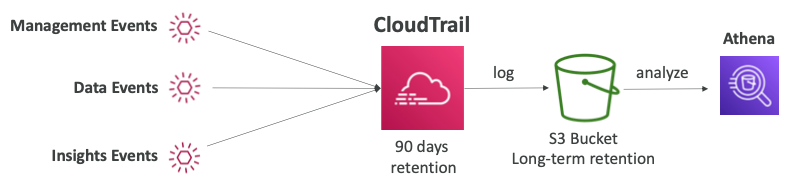
- 저장되는 데이터는 최대 90일 저장이 가능하므로 90일 이상의 이벤트를 저장하고 싶다면 CloudWatch Logs 또는 S3 버킷에 저장해야 한다.
Event
- Management Events
- AWS 계정의 리소스에 대해 수행되는 작업이다.
- 예를 들어, 아래와 같은 작업이 있다.
- 보안 구성 (IAM
AttachRolePolicy)
- 라우팅 데이터에 대한 규칙 구성 (EC2
CreateSubnet)
- 로깅 설정 (CloudTrail
CreateTrail)
- 기본적으로 CloudTrail은 Management Event를 추적하도록 구성된다.
- 읽기 이벤트 (리소스 수정 X)와 쓰기 이벤트 (리소스 수정 O)를 구분할 수 있다.
- Data Events
- 기본적으로 Data Event는 데이터의 양이 많기 때문에 기록되지 않는다.
- S3 객체 수준의 활동(예:
GetObject, DeleteObject, PutObject)을 저장하며, 읽기와 쓰기 이벤트를 분리할 수 있다.
- AWS 람다 함수 실행 활동(
Invoke API)을 기록할 수 있다.
- CloudTrail Insights Event
CloudTrail Insights Event
- CloudTrail Insights를 사용하여 계정의 비정상적인 작업을 감지할 수 있다.
- 부정확한 리소스 프로비저닝
- 서비스 한계 도달
- IAM 작업의 버스트
- 주기적인 유지보수 활동의 공백
- CloudTrail Insights는 일반적인 관리 이벤트를 분석하여 기준선(baseline)을 생성한다.
- 생성된 기준선으로 쓰기 이벤트를 지속적으로 분석하여 비정상적인 패턴을 탐지한다.
- CloudTrail 콘솔에 이상 징후가 표시된다.
- 이벤트가 S3로 전송된다.
- 자동화 필요에 따라 EventBridge 이벤트가 생성된다.

Event Retention
- 이벤트는 CloudTrail에 90일 동안 저장된다.
- 이 기간 이후의 이벤트를 유지하려면 S3에 저장하고 Athena를 사용하여 검색해야 한다.
EventBridge와의 통합
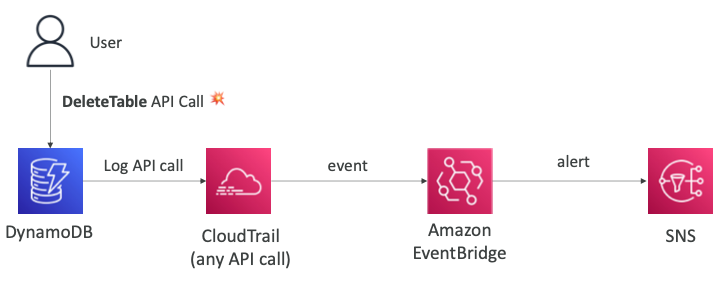
- 사용자는
DeleteTable API를 호출하여 DynamoDB의 테이블을 삭제할 수 있다.
- 이러한 API 호출은 발생할 때마다 기록이 CloudTrail에 저장된다.
- CloudTrail의 이벤트가 저장될 때, EventBridge에서 동일한 이벤트를 획득할 수 있다.
- EventBridge는 이벤트가 발생하였을 때, SNS를 통해서 경고를 생성하여 사용자에게 전달할 수 있다.
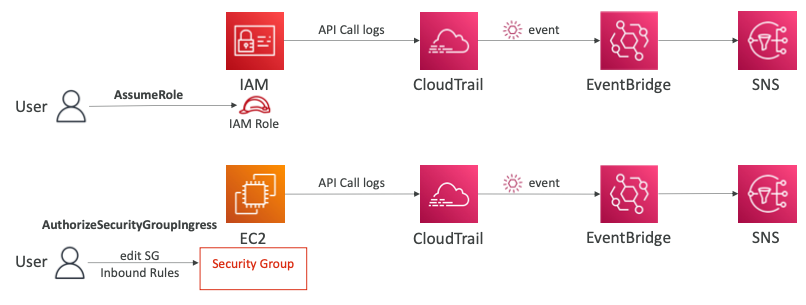
- 사용자가 역할을 수행할 때마다 알림을 요청하도록 아키텍처를 구성한다.
- 사용자는
AssumeRole이라는 IAM 서비스의 API를 호출하고 기록은 CloudTrail에 저장된다.
- EventBridge와의 통합을 이용해서 SNS 토픽에 메시지를 트리거할 수 있다.
- 유사하게 API 호출도 가로챌 수 있다.
- 사용자가 보안 그룹의 인바운드 규칙을 변경할 때마다 알림을 요청하도록 아키텍처를 구성한다.
- 사용자는 인바운드 규칙을 변경하기 위해서
AuthorizeSecurityGroupIngress API를 호출한다.
- 호출된 기록은 CloudTrail에 저장되고 EventBridge에 나타난다.
- EventBridge는 SNS에서 알림을 발생시킬 수 있다.
Dead Letter Queue (DLQ)
- 소비자가 가시성 시간 초과 내에 메시지를 처리하지 못하는 경우 메시지는 다시 대기열로 들어간다.
- 메시지가 대기열로 돌아갈 수 있는 횟수의 임계값을 설정할 수 있다.
- 최대 임계값인
MaximumReceives를 초과하면 메시지가 DLQ(Dead Letter Queue)에 들어간다.
- 디버깅에 유용하게 사용된다.
- FIFO 대기열의 경우 DLQ도 FIFO 대기열이어야 한다.
- Standard 대기열의 경우 DLQ도 Standard 대기열이어야 한다.
- DLQ 메시지가 만료되기 전에 메시지를 처리해야 한다.
- DLQ 메시지의 리텐션 기간을 설정하여 메시지가 처리되지 못한 이유를 찾는 것이 좋다. (예: 14일)
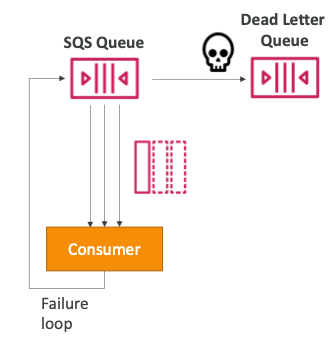
DLQ - Redrive to Source
- DLQ에서 메시지를 소비하여 문제가 된 부분을 이해하는 데 도움이 되는 기능이다.
- 코드가 수정되면 사용자 지정 코드를 작성하지 않고도 DLQ의 메시지를 소스 큐 또는 다른 큐로 다시 전달할 수 있다.
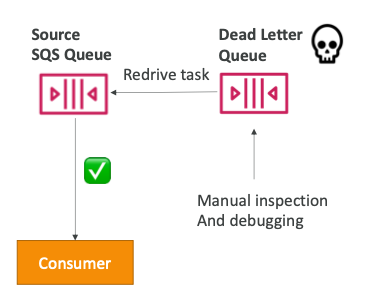
DQL - Redrive Policy
- 배달 정책을 소진한 후(배달 재시도) DLQ를 설정하지 않는 한 배달되지 않는 메시지는 삭제된다.
- Redrive Policy: DLQ(SQS 또는 SQS FIFO)의 ARN을 참조하는 JSON 객체
- DQL는 SNS 구독 수준(SNS 토픽이 아닌)에 연결된다.
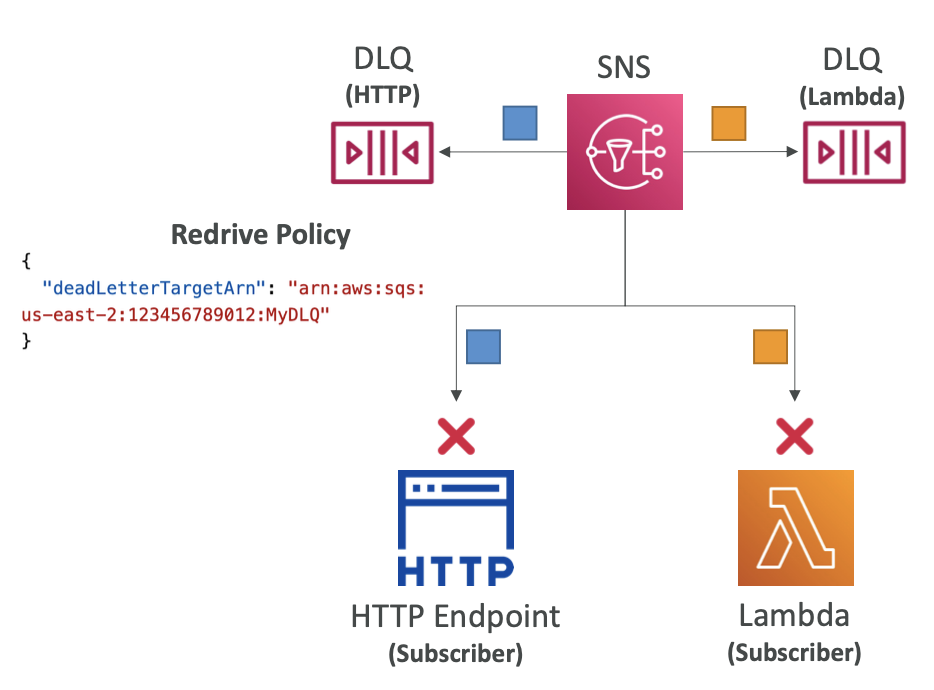
- HTTP 엔드포인트나 람다 함수 같은 SNS 토픽의 구독자가 다수 있을 수 있다.
- 때로는 전달이 제대로 이루어지지 않아서 메시지를 여러 번 반복해서 재시도해도 전달되지 않을 수 있다.
- 전달 재시도 횟수는 소진되고 메시지는 폐기되어 버리는데, 이를 방지하기 위해 DLQ를 설정한다.
- 즉, Redrive 정책을 설정해서 메시지를 폐기하지 말고 DLQ로 보내라고 지정하는 것이다.
- SNS 토픽 구독별로 DLQ 1개, Redrive 정책 1개를 정의한다.
- SNS 토픽이 아니라 구독별로 하나의 DLQ를 정의해야 한다.
- 즉, HTTP 엔드포인트 구독에 자체 DLQ가 있고 람다 구독에 자체 DLQ가 있어야 한다.
AWS X-Ray
- X-Ray는 애플리케이션의 시각 분석과 추적 기능을 제공한다.
- 대기 시간과 오류 비율에 관한 정보를 얻고 네트워크 호출이 인프라에 걸쳐 어떻게 이동하는지 추적할 수 있다.
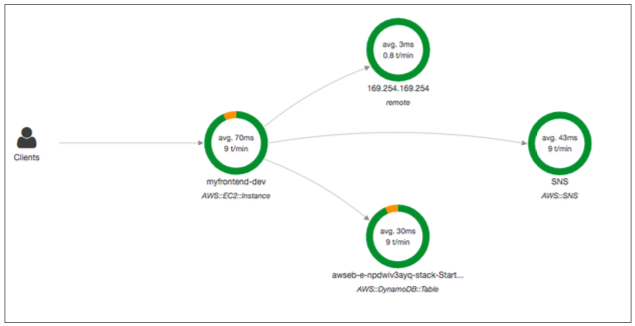
- 마이크로서비스와 같이 분산 시스템 전반에 걸친 요청을 추적할 수 있다.
- 아래의 항목들과 통합될 수 있다.
- X-Ray 에이전트가 설치된 EC2 인스턴스
- X-Ray 에이전트 또는 도커 컨테이너가 설치된 ECS
- 람다
- Beanstalk (에이전트가 자동으로 설치)
- API 게이트웨이 (504와 같은 오류를 디버깅하는데 유용)
- X-Ray 에이전트 또는 서비스에는 X-Ray에 대한 IAM 권한이 필요하다.
Elastic Beanstalk와 통합
- AWS Elastic Beanstalk 플랫폼에는 X-Ray 데몬이 포함되어 있다.
- Elastic Beanstalk 콘솔에서 옵션을 설정하거나 구성 파일 (
.ebextensions/xray-daemon.config)를 사용하여 데몬을 실행할 수 있다.
option_settings:
aws:elasticbeanstalk:xray:
XRayEnabled: true
- X-Ray 데몬이 올바르게 작동할 수 있도록 인스턴스 프로필에 올바른 IAM 권한을 부여해야 한다.
- 그런 다음 애플리케이션 코드가 X-Ray SDK로 계측되었는지 확인해야 한다.
- 참고로 멀티 컨테이너 도커에는 X-Ray 데몬이 제공되지 않는다.
AWS Distro for OpenTelemetry
- 오픈 소스 프로젝트 OpenTelemetry 프로젝트의 안전한 운영 환경을 지원하는 AWS 지원 배포 서비스다.
- 단일 API, 라이브러리, 에이전트 및 수집기 서비스 세트를 제공한다.
- 앱에서 분산 추적 및 측정항목을 수집한다.
- AWS 리소스 및 서비스에서 메타데이터를 수집한다.
- 코드를 변경하지 않고 추적을 수집하는 자동 계측 에이전트다.
- 여러 AWS 서비스 및 파트너 솔루션에 추적 및 지표를 보낼 수 있다.
- X-Ray, CloudWatch, Prometheus 등..
- AWS (예: EC2, ECS, EKS, Fargate, Lambda) 및 온프레미스에서 실행되는 앱을 계측한다.
- Telemetry의 오픈 소스 API로 표준화하거나 동시에 여러 대상으로 추적을 보내려는 경우 X-Ray에서 "AWS Distro for Telemetry"로 마이그레이션할 수 있다.
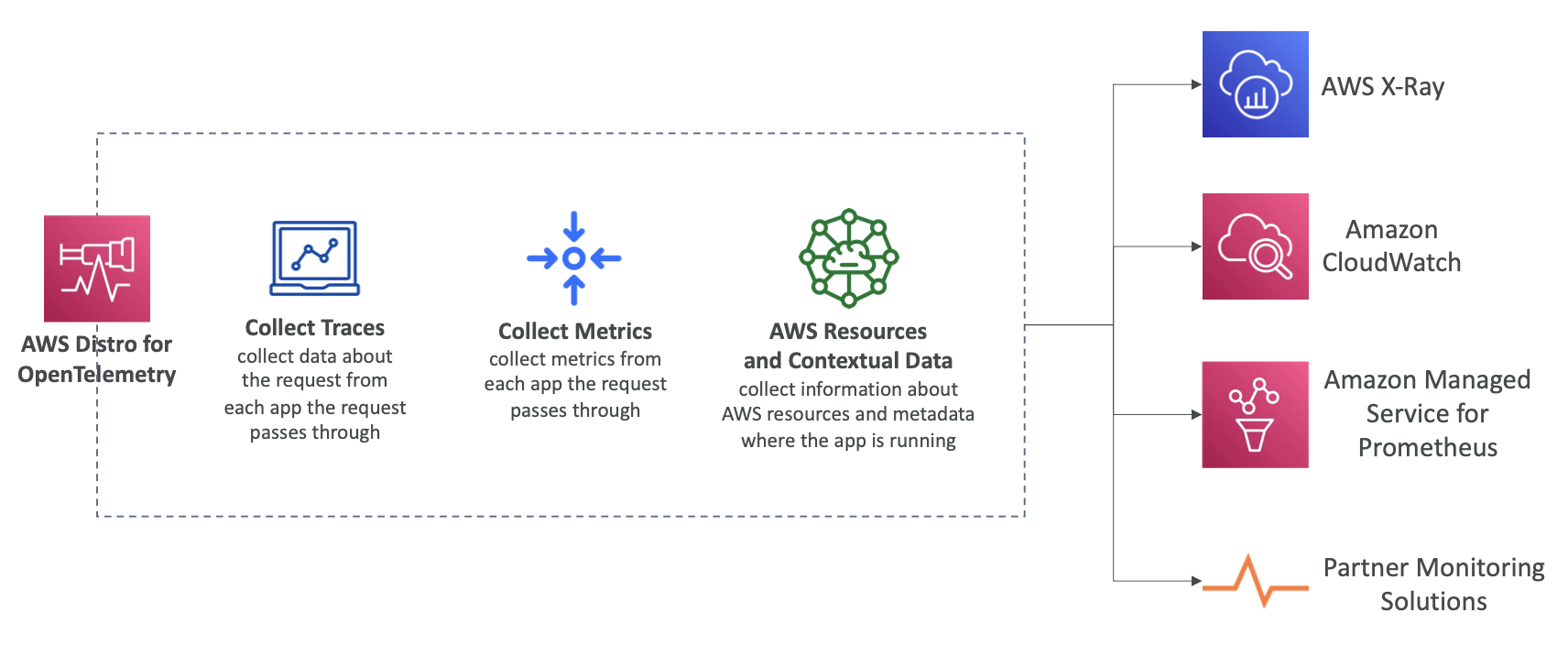
- 요약하면 Distro for OpenTelemetry에서 각 애플리케이션이 전달하는 요청의 추적을 수집한다.
- 각 애플리케이션의 지표도 수집한다.
- 또한 AWS Distro를 통해 AWS 리소스에 대한 컨텍스트 데이터도 수집할 수 있다.
- 수집된 데이터는 X-Ray, CloudWatch, Prometheus 등 OpenTelemetry가 지원하는 파트너 모니터링 솔루션으로 전송된다.
참고한 강의



