Resilient
- 이번 장에서는 DevOps Engineer Professional (DOP) 을 준비하며 "탄력성 있는 아키텍처를 구축하는 방법"에 대해서 알아보도록 한다.
Auto Scaling
Dynamic Scaling Policy
- Target Tracking Scaling
- 가장 간단하고 설치가 용이하다.
- 평균 ASG CPU 사용률을 40%로 유지하도록 설정하면 ASG는 자동으로 확장/축소하여 원하는 CPU 사용률이 되도록 한다.
- Simple / Step Scaling
- CloudWatch에서 직접 알람을 설정한다.
- CloudWatch 경보가 트리거되면(예: CPU 사용률 > 70%) 장치 2개를 추가한다.
- CloudWatch 경보가 트리거되면(예: CPU 사용률 < 30%) 장치 3개를 제거한다.
- 사용자가 직접 얼마나 추가하고 제거할지를 결정해야 한다.
- Scheduled Actions
- 알려진 사용 패턴을 기반으로 확장을 예측한다.
- 예를 들어, 금요일 오후 5시에 큰 행사가 있는 것을 알고 있는 경우 트래픽이 몰리는 시간에 최소 용량을 확장한다.
- Predictive Scaling
- 지속적으로 부하를 예측하고 사전 확장을 예약한다.
- 부하를 보고 예측에 근거해 미리 스케일링 작업이 예정된다.
- 머신 러닝 기반으로 가장 손쉬운 접근법이다.

스케일링에 사용되는 좋은 지표
- CPUUtilization: 인스턴스 전체의 평균 CPU 사용률을 확인한다.
- RequestCountPerTarget: EC2 인스턴스당 요청 수가 안정적인지 확인한다.
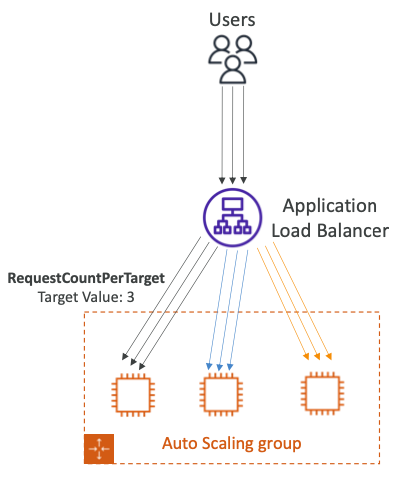
- Average Network In / Out: 응용 프로그램이 네트워크 바인딩된 경우, 많은 업로드와 다운로드가 있다면 인스턴스의 병목현상이 발견될 수 있다.
- 평균 네트워크를 스케일아웃하여 어떤 임계값에 도달하면 그에 기반해 스케일아웃한다.
- CloudWatch를 통해 푸시된 커스텀 매트릭
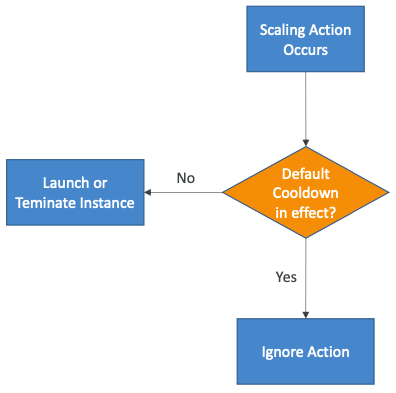
Scaling Cooldown
- 조정 활동이 발생한 후에는 "Cooldown"(기본값: 300초) 기간이 된다.
- "Cooldown"기간 동안 ASG는 추가 인스턴스를 시작하거나 종료하지 않는다. (메트릭의 안정화를 위해)
- 요청을 더 빠르게 처리하고 "Cooldown" 기간을 줄이기 위해 즉시 사용 가능한 AMI를 사용하여 구성시간을 줄일 수 있다.
- 물론 ASG에 대한 상세 모니터링이 가능하도록 해야한다. 1분마다 메트릭이 충분히 업데이트 될 수 있도록 설정한다.
ASG Lifecycle Hook
- 기본적으로 ASG에서 인스턴스가 시작되자마자 서비스가 시작된다.
- 인스턴스가 서비스되기 전에 추가 단계를 수행할 수 있다. (Pending 상태)
- 인스턴스가 시작될 때 실행할 스크립트를 정의한다.
- 인스턴스가 종료되기 전에 몇 가지 작업을 수행할 수 있다. (Terminating 상태)
- 문제 해결을 위해 인스턴스가 종료되기 전에 일시 중지한다.
- 인스턴스가 시작되어 작동하기 전에 청소, 로그 추출 혹은 특별한 상태 확인 등의 작업에 사용된다.
- EventBridge, SNS, SQS와 통합되어 사용될 수 있다.

- 기본적으로 인스턴스를 시작하면 ASG에서 곧바로 InService 상태가 된다.
- 수명 주기 후크를 사용하는 경우 InService 상태가 되기 전에 일부 작업을 실행할 수 있다.
- 스케일 아웃 이벤트가 발생하고 인스턴스가 스크립트를 실행할 시간을 남겨두어야 할 때, "EC2_Instance_Launching" 수명주기 후크를 실행할 수 있다.
Pending:Wait로 전환되고 스크립트가 완료되면Pending:Proceed상태로 전환되도록 할 수 있다.
- 인스턴스가 종료될 때도 작업을 실행할 수 있다.
- 인스턴스를 바로 종료하는 대신 로그를 일시 중지하거나 문제 해결을 위해 인스턴스를 일시 중지해야 할 수 있다.
- 종료 시작 시 인스턴스가 Terminating 상태로 전환되면 "EC2_Instance_Terminating" 수명 주기 후크를 실행할 수 있다.
Terminating:Wait상태가 되고 원하는 모든 작업을 한 다음 완료되면 ASG에 종료를 진행할 수 있다고 알린다.- 그 후 인스턴스는 예정대로 종료된다.
- 수명 주기 이벤트가 EventBridge에서 이벤트를 트리거하면 거기에서 람다 함수 등 원하는 자동화를 호출하여 이러한 수명 주기 후크를 처리할 수 있도록 구성할 수 있다.
- 인스턴스가
Terminating:Wait상태로 전환되어 종료 중인데 로그를 수집하고 싶은 상황이다. - 이벤트는 EventBridge에 있게 되고 여기서 Systems Manager Run Command를 호출하여 로그를 수집하고 이를 S3 등에 분석을 위해 보낼 수 있다.
- CloudWatch Logs로 로그를 전송할 수도 있다.
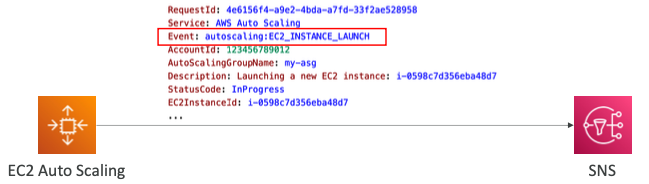
SNS Notifications
- ASG는 다음 이벤트에 대한 SNS 알림 전송을 지원한다.
autoscaling:EC2_INSTANCE_LAUNCHautoscaling:EC2_INSTANCE_LAUNCH_ERRORautoscaling:EC2_INSTANCE_TERMINATEautoscaling:EC2_INSTANCE_TERMINATE_ERROR
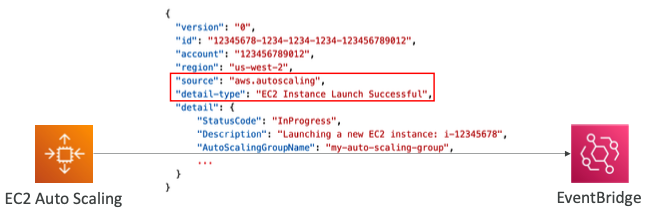
- 다음 ASG 이벤트와 일치하는 규칙을 생성할 수 있다.
- EC2 인스턴스 시작, EC2 인스턴스 시작 성공/실패
- EC2 인스턴스 종료 중, EC2 인스턴스 종료 성공/실패
- EC2 Auto Scaling 인스턴스 새로 고침 체크포인트 도달
- EC2 Auto Scaling 인스턴스 새로 고침 시작됨, 성공, 실패, 취소됨
Termination Policy
- 스케일인 이벤트, 인스턴스 새로 고침 및 AZ 재조정 중에 먼저 종료할 인스턴스를 결정하는 정책이다.
- 기본 종료 정책은 아래와 같다.
- 인스턴스가 더 많은 AZ를 선택한다.
- 가장 오래된 시작 템플릿 또는 시작 구성을 사용하여 생성된 인스턴스를 종료한다.
- 인스턴스가 동일한 시작 템플릿 사용하여 시작된 경우 다음 청구 시간에 가장 가까운 인스턴스를 종료한다.
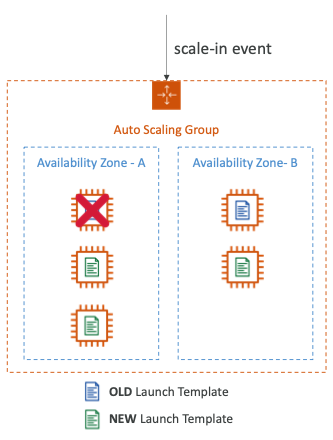
- ASG가 있고 이전 시작 템플릿으로 시작된 EC2 인스턴스가 두 개 포함되어 있다.
- 새 시작 템플릿을 통해 계속 스케일 아웃하여 이제 EC2 인스턴스가 다섯 개다.
- 이렇게 많은 용량이 필요하지 않기 때문에 스케일인 이벤트가 발생한다.
- 먼저 가장 많은 인스턴스가 있는 가용성 영역을 평가하고 예시에서는 AZ-A가 된다.
- 그런 다음 시작 템플릿을 살펴보고 가장 오래된 시작 템플릿이 있는 인스턴스를 선택한다.
- 따라서 첫 번째 인스턴스를 종료한다.
- 동일한 이전 시작 템플릿이 있는 인스턴스가 두 개라면 다음 결제 시점과 가장 가까운 인스턴스를 종료한다.
Different Termination Policy
- Default: 기본 종료 정책에 따라 인스턴스를 종료한다.
- AllocationStrategy: 나머지 인스턴스를 할당 전략에 맞추기 위해 인스턴스를 종료한다.
- 예를 들어, 스팟 인스턴스의 경우 최저가 또는 우선순위가 낮은 온디맨드 인스턴스를 종료한다.
- OldestLaunchTemplate: 가장 오래된 시작 템플릿이 있는 인스턴스를 종료한다.
- OldestLaunchConfiguration: 가장 오래된 시작 구성을 가진 인스턴스를 종료한다.
- ClosestToNextInstanceHour: 다음 청구 시간에 가장 가까운 인스턴스를 종료한다.
- NewestInstance: 최신 인스턴스를 종료한다.
- 새로운 시작 템플릿을 테스트할 때 유용하게 사용된다.
- OldestInstance: 가장 오래된 인스턴스를 종료한다.
OldestLaunchTemplate과는 다르다.- 인스턴스의 크기를 예로 들어
m5.large에서m5.4xlarge로 업그레이드하는 경우 시작 템플릿을 변경하는 것이 아니라 인스턴스 크기를 변경하기 때문이다. - 이 경우 가장 오래된 인스턴스를 삭제해야 한다.
- 이러한 정책들은 하나 이상의 정책을 사용할 수 있고 평가 순서를 지정할 수 있다.
- 람다 함수를 통해 지원되는 사용자 지정 종료 정책을 정의할 수 있다.
Scale-out Latency Problem
- ASG가 확장되면 가능한 한 빨리 인스턴스를 시작하려고 한다.
- 일부 애플리케이션에는 애플리케이션 초기화/부트스트랩 계층에 존재하는 긴 피할 수 없는 지연 시간이 포함되어 있다.
- 초기 부팅 시에만 발생할 수 있는 프로세스로 업데이트 적용, 데이터 또는 상태 수화, 스크립트 실행 등으로 인해 발생한다.
- 솔루션은 예기치 못한 수요 증가(비용 증가)를 흡수하기 위해 컴퓨팅 리소스를 과도하게 프로비저닝하거나 골든 AMI를 사용하여 부팅 시간을 줄이는 것이다.
- 아래에서 살펴볼 "Warm Pools"는 이러한 문제를 해결하기 위한 좋은 방법이다.
Warm Pools
- 사전 초기화된 인스턴스 풀을 유지하여 확장 지연 시간을 줄인다.
- 확장 이벤트에서 ASG는 새 인스턴스를 시작하는 대신 Warm Pool에서 사전 초기화된 인스턴스를 사용한다.
- Warm Pool 크기 설정
- Minimum warm pool size: 최소 크기로 어떤 경우에도 Warm Pool에 항상 있어야 하는 인스턴스의 수다.
- Max prepared capacity: ASG의 최대 용량이다. (기본값)
- Max prepared capacity: 설정된 인스턴스의 수
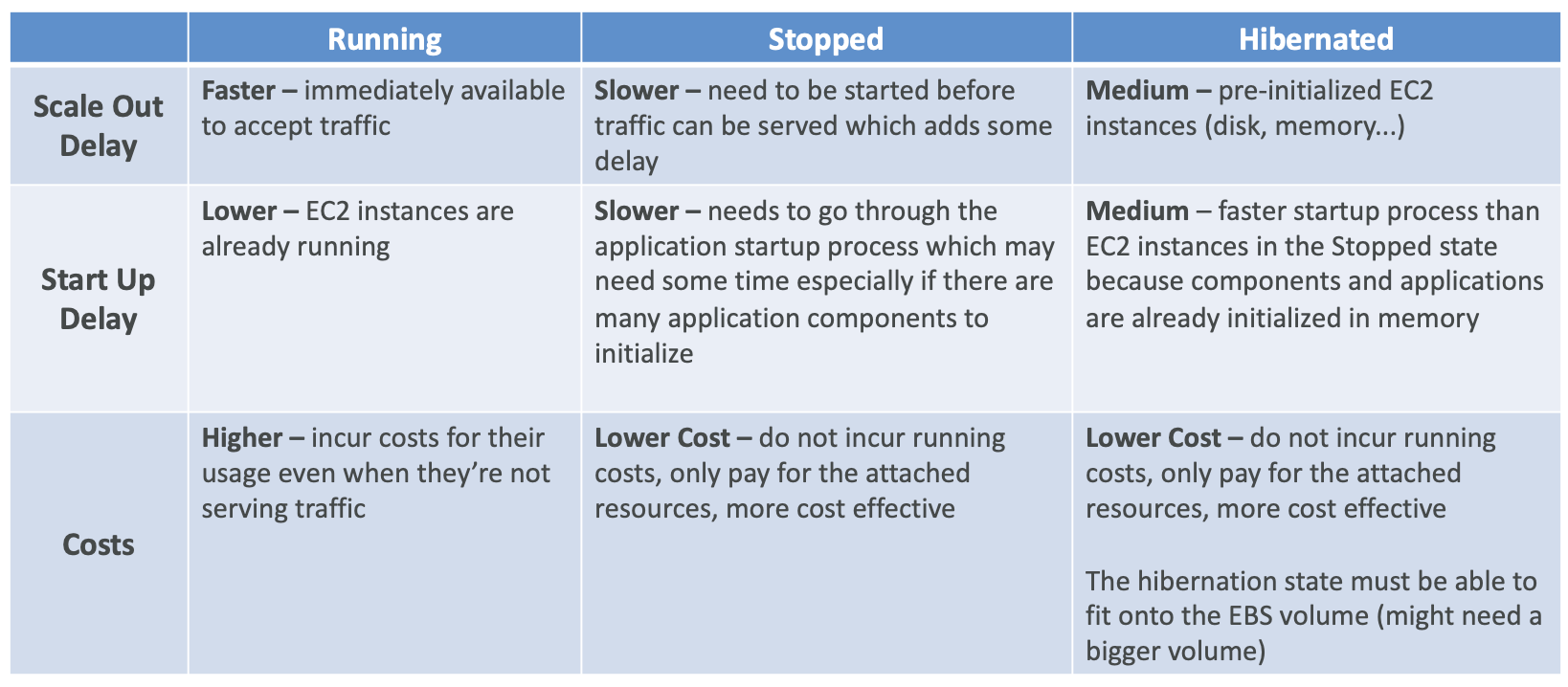
- Warm Pool Instance State: 초기화 후 Warm Pool 인스턴스를 유지할 상태다. (Started, Stopped, Hibernated)
- Warm Pools 인스턴스는 확장 정책에 영향을 미치는 ASG 지표에 기여하지 않는다.
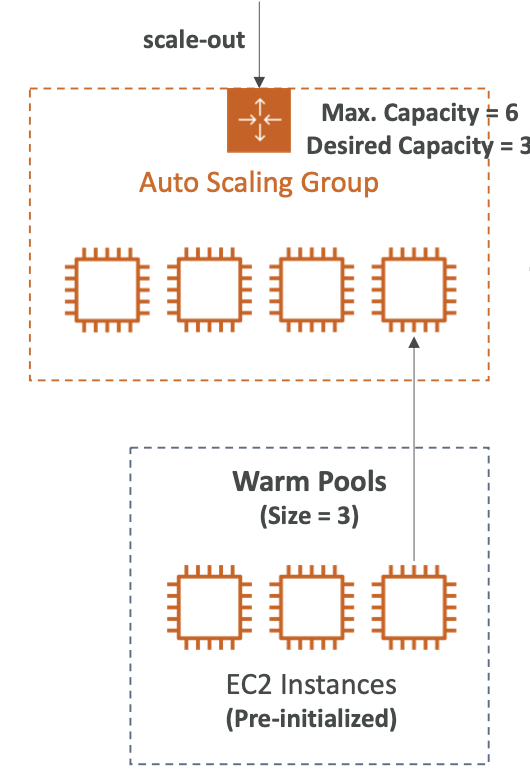
- ASG가 있고 희망 용량은 3, 최대 용량은 6이다.
- 이렇게 구성된 경우 Warm Pool의 크기는 3이된다.
- 3은 기본적으로 최대 용량과 희망 용량의 차이다. (최대 용량 - 희망 용량)
- 이 숫자는 최대 용량에 도달할 때까지 풀에서 ASG에 넣을 수 있는 최대 인스턴스의 수다.
- Warm Pool에 있는 인스턴스는 사전 초기화되어 있으며 필요한 모든 설정이 완료되어 있다.
Warm Pools Pricing: m5.large
- ASG에서 "EC2 인스턴스를 과도하게 프로비저닝"하는 경우
- 운영 비용 = $0.096/hour * 24hours/day * 30days = $69.12 + EBS 볼륨
- EC2 인스턴스가 중지되면 연결된 EBS 볼륨에 대해서만 비용을 지불한다.
- EBS 볼륨 비용 = $0.10/GB(month) * 10GB = $1.00
Warm Pools 인스턴스 상태
- Warm Pools의 인스턴스 상태는 총 세 개가 있으며 아래의 표를 참고한다.
Instance Reuse Policy
- 기본적으로 ASG는 ASG가 축소되면 인스턴스를 종료한 다음 Warm Pool에서 새 인스턴스를 시작한다.
- 인스턴스 재사용 정책을 통해 축소 이벤트가 발생할 때 인스턴스를 Warm Pool로 반환할 수 있다.

Lifecycle Hooks
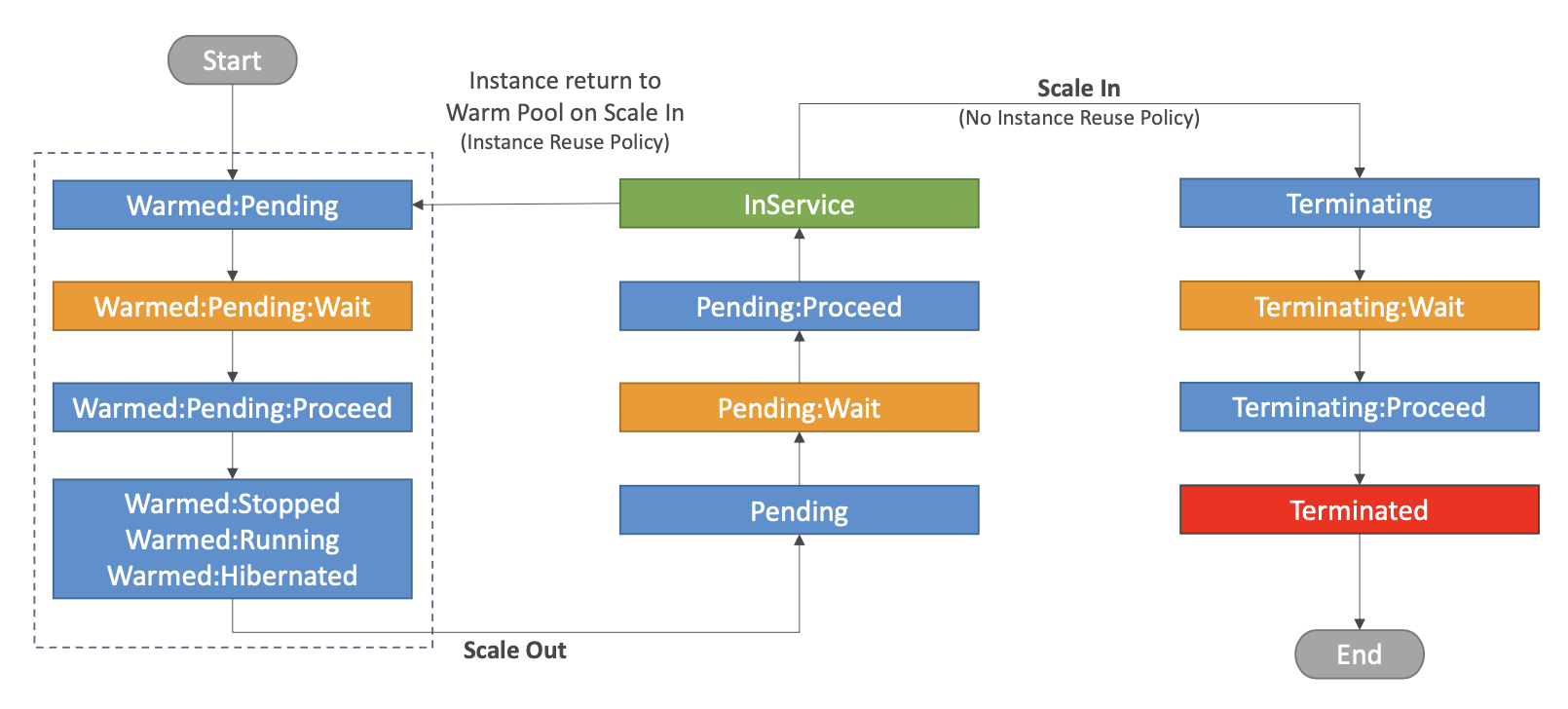
- 인스턴스가 Warm Pool에서 시작되고
Warmed:Pending상태가 되고 그러면Warmed:Pending:Wait라는 후크에 액세스할 수 있다.- 여기서 인스턴스 초기화가 완료되었음을 확인할 때까지 인스턴스는 이 상태에 머무를 수 있다.
- 이때 ASG는 Warm 인스턴스가 준비되었음을 알게 된다.
- 준비되면
Warmed:Pending:Proceed상태로 전환되고 그런 다음 Warm Pool에 선택한 상태로 전환된다. Warmed:Stopped,Warmed:Running,Warmed:Hibernated일 수 있다.- 이렇게 Warm Pool에 있는 인스턴스의 초기화를 완료했다.
- 스케일 아웃 이벤트가 있을 때마다 Warm Pool의 인스턴스는 ASG로 이동하게 된다.
- 따라서 Pending 상태로 전환된 후
Pending:Wait상태가 된다. - 일반적인 수명 주기 후크와 똑같으며 초기화 등 원하는 작업을 할 수 있다.
- 그런 다음
Pending:Proceed로 이동한 후 인스턴스는 InService 상태가 된다.
- 따라서 Pending 상태로 전환된 후
- 마찬가지로 인스턴스를 종료하는데 인스턴스 재사용 정책이 없으면 수명 주기 후크는 일반 ASG와 동일한다.
Terminating다음에Terminating:Wait,Terminating:Proceed,Terminated순으로 작동한다.
- 인스턴스 재사용 정책을 사용한다면 인스턴스가 풀로 다시 반환되고
Warmed:Pending상태로 전환된다.- 이후,
Warmed:Pending:Wait,Warmed:Pending:Proceed를 거쳐Warmed:Stopped또는Running,Hibernated가 된다.
- 이후,
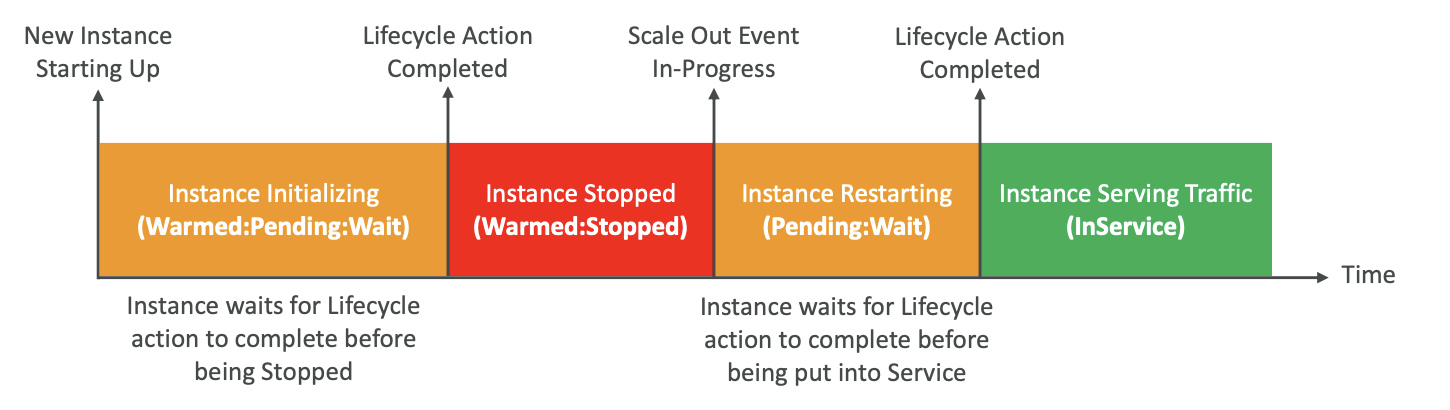
- 요약하면 스케일 아웃 이벤트의 경우 먼저 인스턴스가
Warmed:Pending:Wait상태를 보유한다.- 이 상태에서 인스턴스가 실제로 Stopped 상태나 Warm Pools에 선택한 상태로 전환되기 전에 완료할 수명 주기 작업을 실행할 수 있다.
- 그런 다음 스케일 아웃 이벤트가 발생하면
Pending:Wait상태가 되는데 이유는 인스턴스가 시작되고 있기 때문이다. - 인스턴스가 InService 상태로 되기 전에 또한 수명 주기 작업을 할 수 있다.
- 그런 다음 인스턴스는 InService 상태가 되며 트래픽을 처리하는데 사용할 수 있다.
AWS Application Auto Scaling
- 앱을 모니터링하고 자동으로 용량을 조정하여 최저 비용으로 꾸준하고 예측 가능한 성능을 유지한다.
- 한 곳에서 여러 서비스에 걸쳐 여러 리소스에 대한 확장을 설정한다.
- 다른 서비스를 탐색할 필요가 없다.
- 앱을 가리키고 확장하려는 서비스와 리소스를 선택한다.
- 각 서비스에 대한 경보 및 확장 작업을 설정할 필요가 없다.
- CloudFormation 스택, 태그 또는 EC2 ASG를 사용하여 리소스/서비스를 검색한다.
- 수요 변화에 따라 실시간으로 리소스의 용량을 자동으로 추가/제거하는 확장 계획을 구축한다.
- 대상 추적, 단계 및 예약된 확장 정책을 지원한다.

- 스케일링 계획에서 ASG 정책을 사용할 수도 있지만 프로비저닝 용량 등과 관련하여 DynamoDB 정책을 사용할 수도 있다.
Integrated AWS Services
- 수 많은 AWS 서비스들과 통합될 수 있다.
ALB - Listener Rule
- 순서대로 처리된다. (기본 규칙 사용)
- 지원되는 작업 (forward, redirect, fixed-response)
- 규칙 조건
- host-header
- http-request-method
- path-pattern
- source-ip
- http-header
- query-string
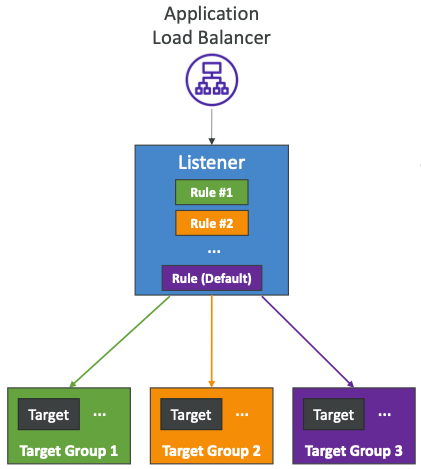
- 규칙은 ALB에서 설정하며 여러 개 또는 하나의 규칙을 보유할 수 있다.
- 마지막 규칙은 기본 규칙이라고 하며 각 규칙에는 특정 대상이 있다.
Target Group 가중치
- 단일 규칙에 대해 각 대상 그룹에 대한 가중치를 지정한다.
- 예를 들어, 여러 버전의 앱, 블루/그린 배포에 사용한다.
- 애플리케이션에 대한 트래픽 배포를 제어할 수 있다.
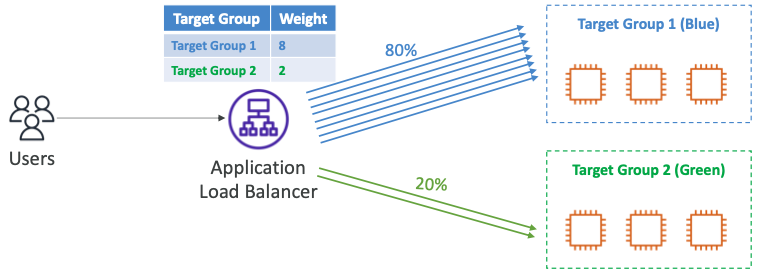
- 사용자가 있고 사용자는 ALB와 통신하고 ALB는 일반적으로 "대상 그룹 1 (블루)"과 통신하도록 연결되어 있다.
- 새로운 애플리케이션 버전인 "대상 그룹 2 (그린)"를 추가하려한다.
- 규칙에서 가중치를 설정하여 "대상 그룹 1"은 8, "대상 그룹 2"는 2로 설정한다.
- ALB는 트래픽의 80%를 첫 번째 그룹으로 보내고, 트래픽의 20%를 두 번째 그룹으로 보낸다.
- 이를 통해 대상 그룹에 관해 모니터링을 실행할 수 있고 트래픽을 올바르게 수신하는지 지표가 좋은지, 애플리케이션 버전이 예상대로 동작하는지 여부를 확인할 수 있다.
DualStack Networking
- 클라이언트가 IPv4와 IPv6를 모두 사용하여 ELB와 통신할 수 있도록 한다.
- ALB와 NLB를 모두 지원한다.
- ALB와 NLB는 별도의 대상 그룹에 혼합된 IPv4 및 IPv6 대상을 가질 수 있다.
- ELB DualStack은 클라이언트와 대상 IP 버전 간의 호환성을 보장한다.
- IPv4 클라이언트는 IPv4 대상과 통신하고, IPv6 클라이언트는 IPv6 대상과 통신한다.
- IPv4 대상만 있는 경우 ELB는 자동으로 요청을 IPv6에서 IPv4로 변환한다.
- 참고로 인스턴스가 트래픽을 수신하려면 AZ를 추가 및 활성화해야 한다.
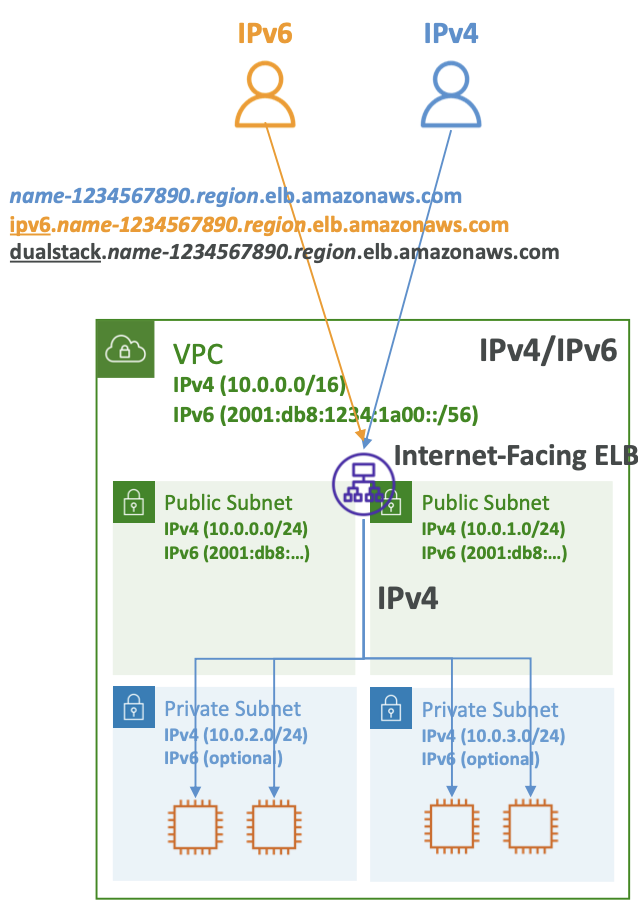
- VPC가 있고 IPv6에 활성화되어 IPv6 사이더를 포함하고 있다.
- IPv6가 있는 퍼블릭 서브넷이 있고, Internet-Facing ELB가 있다.
- 이 ELB는 세 가지 URL을 사용하여 액세스할 수 있다.
- 먼저 IPv4이며 파란색 트래픽을 확인하면 된다.
- 두 번째는 IPv6용이며 IPv6가 있는 클라이언트가 액세스할 수 있다.
- 마지막으로 DualStack이며 IPv6 및 IPv4 클라이언트에게 동일한 URL을 제공하면 DualStack이 IPv6나 IPv4 중에서 적절한 IP를 결정한다.
- 핵심은 IP 프로토콜 측면에서 클라이언트가 어떤 버전을 사용할지 모르는 경우 DualStack URL을 제공하면 자동으로 올바른 프로토콜이 사용된다는 것이다.
PrivateLink Integration
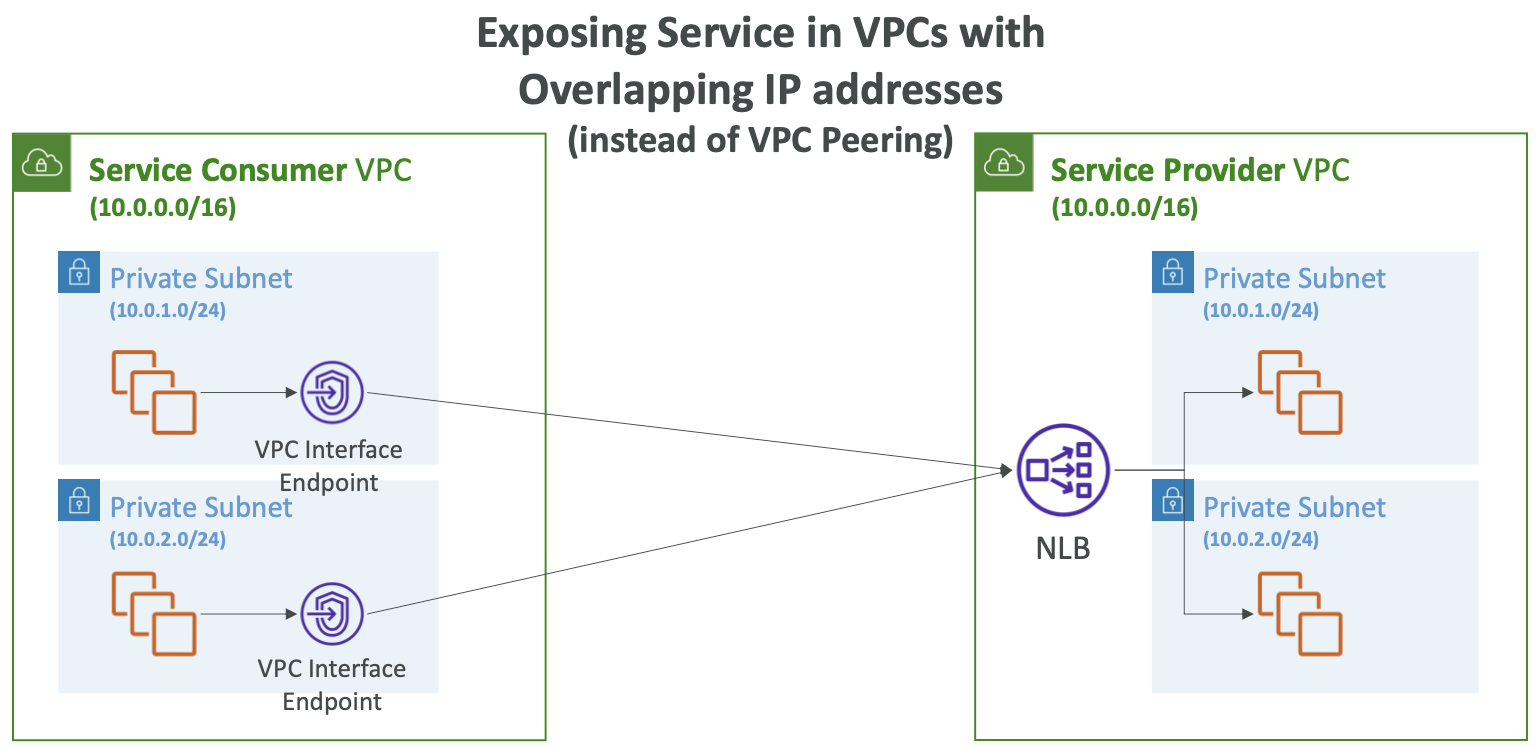
- 서비스 소비자 VPC와 서비스 공급자 VPC가 있고 IP 주소가 겹치는 경우 둘을 함께 페어링할 수 없다.
- 서비스 공급자에 애플리케이션이 있고 서비스 소비자에 애플리케이션이 있다고 가정한다.
- 이 둘 간의 통신을 관리하는 방법은 서비스 공급자 VPC에서 NLB로 서비스를 노출하고 PrivateLink를 만드는 것이다.
- 그러면 VPC 인터페이스가 생성되고 서비스 소비자 VPC를 카리키게 된다.
NAT Gateway
- AWS를 통해 관리되는 NAT로, 더 높은 대역폭, 고가용성을 제공하며 사용자가 관리할 필요가 없다.
- 사용량 및 대역폭에 따라 시간당 비용을 지불하면 된다.
- NAT 게이트웨이는 특정 가용 영역에 생성되며 Elastic IP(EIP)를 사용한다.
- 동일한 서브넷의 EC2 인스턴스에서는 사용할 수 없으며, 다른 서브넷에서 사용해야 한다.
- IGW를 필요로 한다. (Private Subnet -> NATGW -> IGW)
- 5Gbps의 대역폭을 제공하며 최대 100Gbps까지 자동으로 확장할 수 있다.
- 관리할 보안 그룹이 없거나 필요하지 않다.
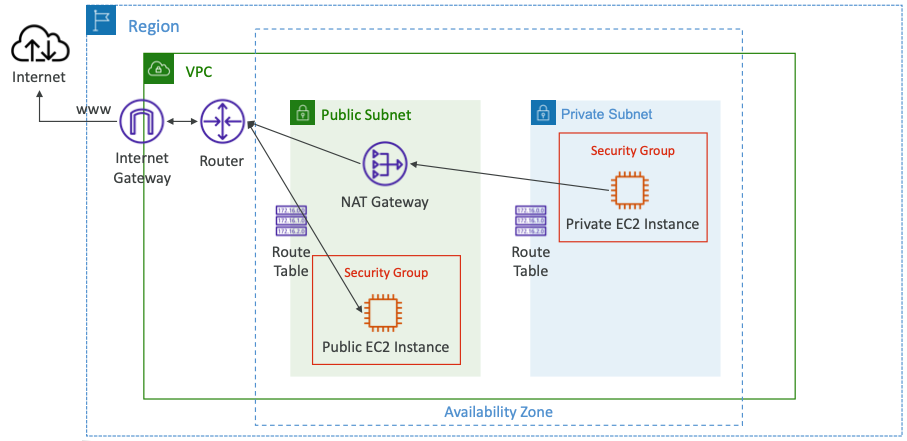
- 프라이빗 인스턴스와 프라이빗 서브넷이 있고 인터넷에 액세스할 수 없다.
- 따라서 퍼블릭 서브넷에서 NAT 게이트웨이를 만들고, NAT 게이트웨이는 퍼블릭 서브넷에 배포한다.
- 퍼블릭 서브넷은 이미 인터넷 게이트웨이에 연결되어 있다.
- 그러면 NAT 게이트웨이도 인터넷에 연결된다.
- 그런 다음 프라이빗 서브넷의 경로를 수정한다.
- 이를 수정함으로써 EC2 인스턴스를 NAT 게이트웨이에 연결할 수 있게 된다.
- NAT 게이트웨이는 단일 가용 영역 내에서 복원력이 뛰어나다.
- 내결함성을 위해 여러 AZ에 여러 NAT 게이트웨이를 생성해야 한다.
- 아래와 같이 다중 NAT 게이트웨이를 설치한 경우, AZ가 중단되더라도 NAT가 필요하지 않으므로 교차 AZ 장애 조치가 필요하지 않다.
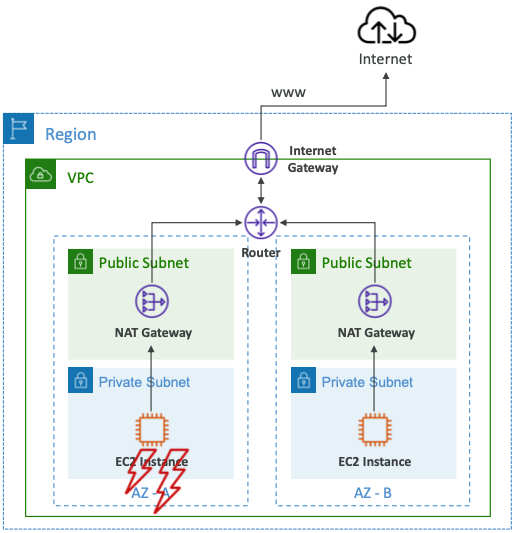
- NAT 게이트웨이가 하나 있고 하나의 특정 AZ에 있다.
- 두 번째 가용성 영역에서 두 번째 NAT 게이트웨이를 생성한다.
- 따라서 각 네트워크 트래픽이 하나의 AZ에 종속된다.
- AZ가 다운되는 경우, 이 전체 AZ가 다운되더라도 여전히 가용성 영역 B가 작동한다.
- 경로 테이블을 통해 AZ를 함께 연결할 필요가 없다.
- 이유는 AZ가 다운되면 포함된 모든 EC2 인스턴스에도 액세스할 수 없기 때문이다.
NAT 게이트웨이 vs NAT 인스턴스
- NAT 게이트웨이와 NAT 인스턴스는 아래와 같은 차이를 가지고 있다.
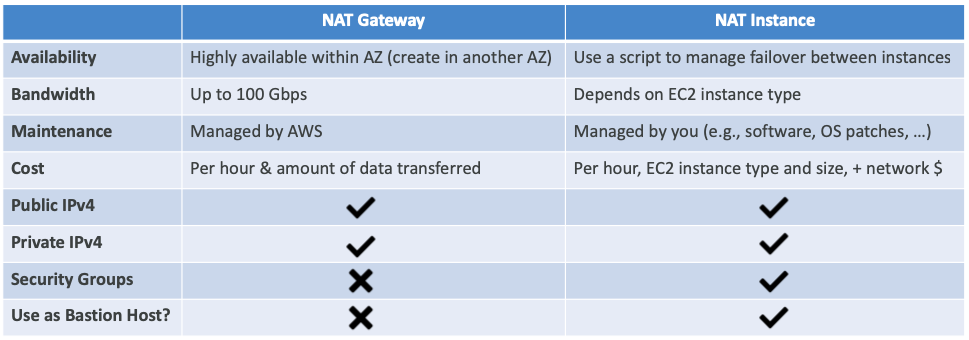
Multi AZ
- Multi-AZ를 수동으로 활성화해야 하는 서비스
- EFS, ELB, ASG, Beanstalk: AZ 할당
- RDS, ElastiCache: Multi-AZ (장애 조치를 위한 동기식 대기 DB)
- Aurora
- 데이터는 Multi-AZ에 자동으로 저장된다.
- DB 자체에 Multi-AZ를 가질 수 있다. (RDS와 동일)
- OpenSearch (관리형): 다중 마스터 설정을 통해 Multi-AZ에서 사용할 수 있다.
- Jenkins (자체 배포): 다중 마스터가 있지만 Multi-AZ에 걸쳐 배포하는지 확인해야 한다.
- 항상 Multi-AZ가 활성화되어 있는 서비스
- S3 (OneZone-Infrequent Access 제외)
- DynamoDB
- AWS 독점 서비스와 관리형 서비스는 일반적으로 Multi-AZ를 기본적으로 지원한다.
Multi-AZ Architecture
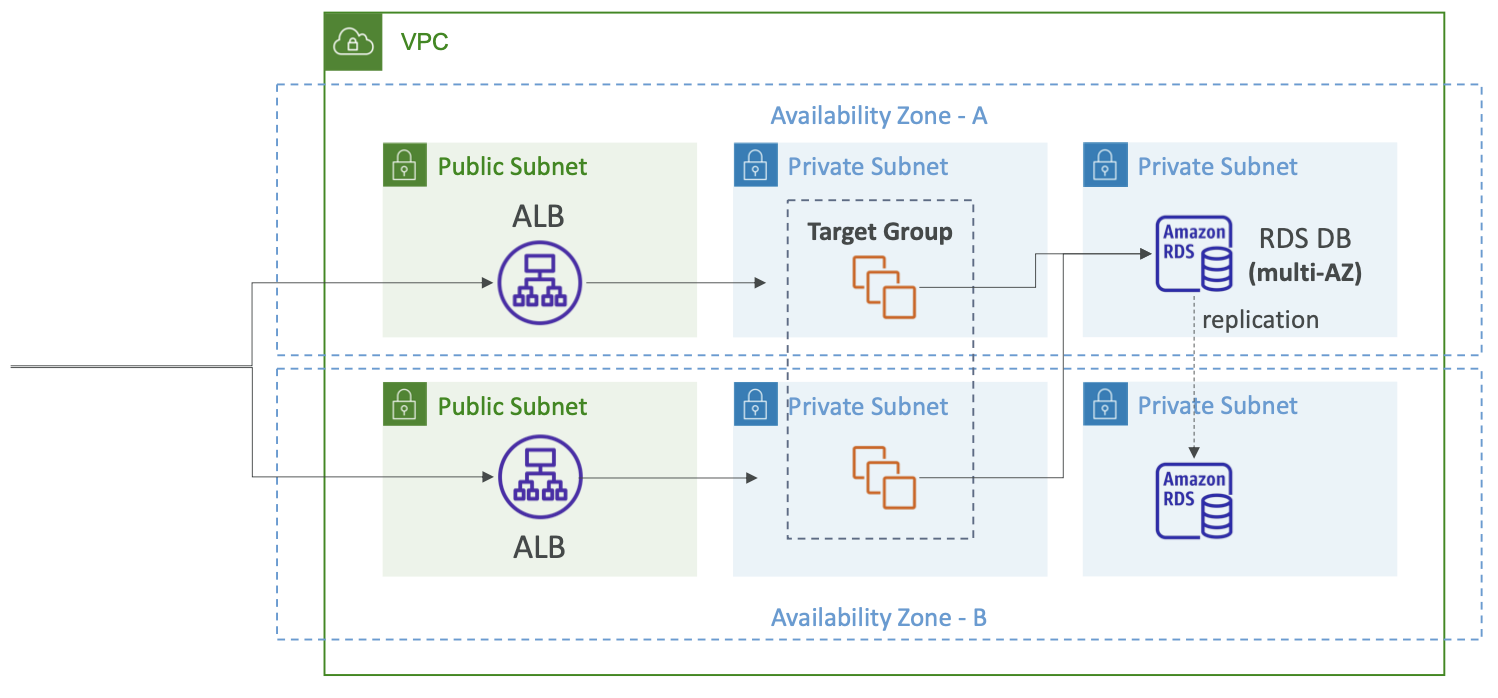
- Multi-AZ 설정의 3-Tier 아키텍처를 보면 퍼블릭 서브넷 하나와 애플리케이션 티어의 프라이빗 서브넷 하나 데이터 티어의 프라이빗 서브넷 하나가 있다.
- 로드 밸런서 ALB는 Multi-AZ에서 VPC의 여러 서브넷으로 분산된다.
- 따라서 요청이 Multi-AZ 영역에 분산된다.
- 대상 그룹도 Multi-AZ에 걸쳐 확장될 수 있다.
- 그러면 ALB는 대상 그룹에 트래픽을 전송한다.
- 네트워크 비용 절감을 위해 동일한 가용성 영역으로 보내거나 교차 영역 로드 밸런싱을 활성화한 경우에는 요청이 가용성 영역을 넘어갈 수 있다.
- 데이터베이스를 예로 들면 Multi-AZ에 배포되어 있다.
- 기본 인스턴스가 하나 있고, 대기 인스턴스가 있으며 동기식으로 복제된다.
- 따라서 데이터베이스의 애플리케이션 요청은 기본 인스턴스로 이동한다.
Blue-Green Architecture
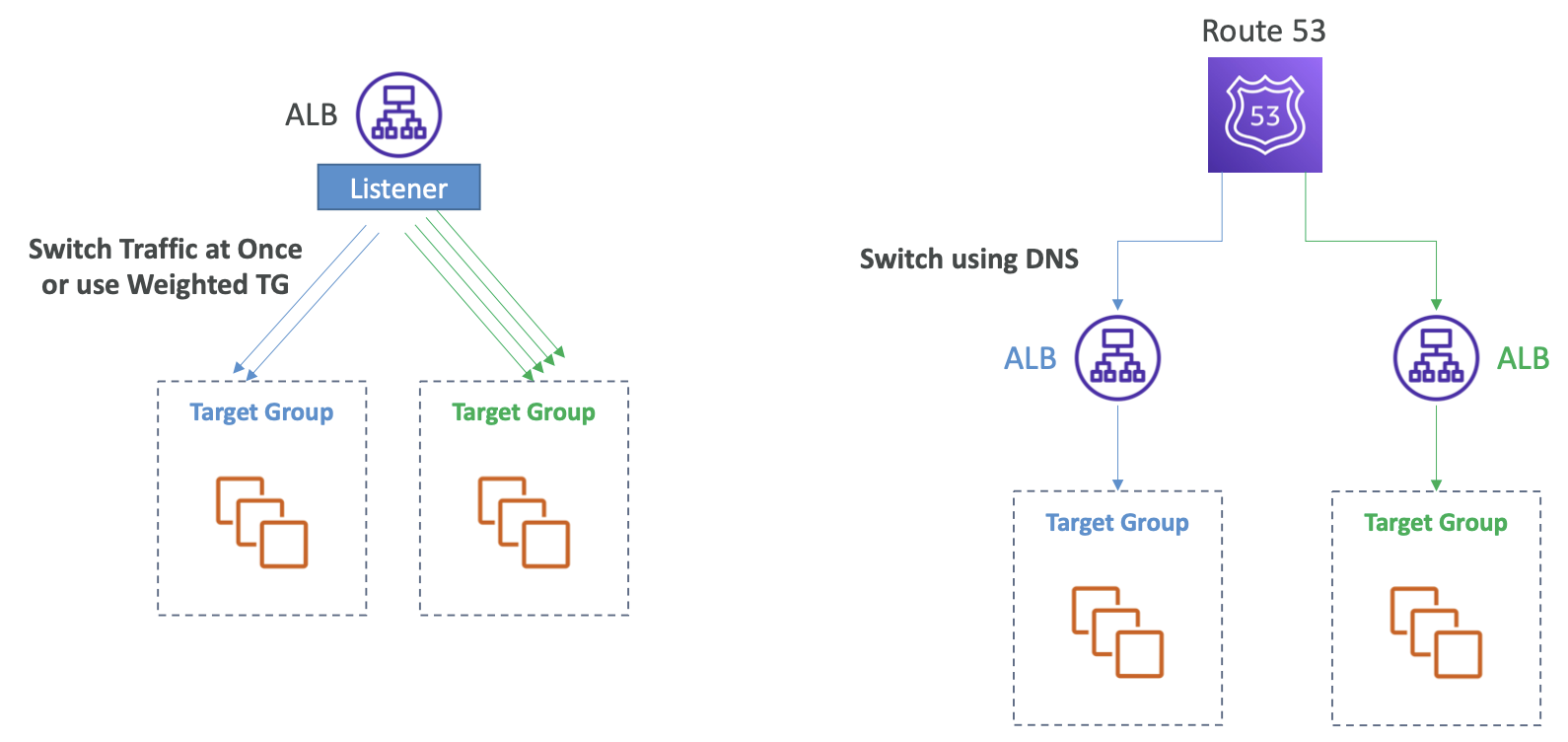
- 예시 1
- 리스너가 있고 대상 그룹이 두 개있다.
- 블루 대상 그룹이 있으며 현재 요청을 수신하고 있다.
- 동일한 리스너에 그린 대상 그룹을 추가하고 블루 대상 그룹과 그린 대상 그룹 간에 요청을 분산할 수 있다.
- 원하는 경우 대상 그룹을 전환하여 한 번에 트래픽을 모두 전환하거나, 대상 그룹에 가중치를 할당할 수도 있다.
- 예를 들어, 블루에 90%, 그린에 10%와 같은 방식으로 할당할 수 있다.
- 그린 대상 그룹이 적절하게 동작하면 천천히 또는 한꺼번에 모든 트래픽을 전환한다.
- 이러한 방식의 좋은 점은 ALB가 요청 리디렉션을 담당하므로 블루 대상 그룹에서 그린 대상 그룹으로 한 번에 트래픽을 모두 전환할 수 있다는 것이다.
- 예시 2
- 대상 그룹당 하나의 ALB가 있으며 하나의 ALB에서 다음 ALB로 전환할 수 있어야 한다.
- 이를 위해서는 DNS를 사용해야 한다.
- 따라서 Route 53이 유용하며 DNS를 사용하여 한 ALB에서 다음 ALB로 전환할 수 있다.
- 하지만 이 과정은 클라이언트가 DNS 쿼리의 결과를 캐시하기 때문에 시간이 지나야 원하는 결과를 얻을 수 있다.
- DNS 전환은 즉각적이지 않으며 한 번에 모든 트래픽을 이전할 수는 없다.
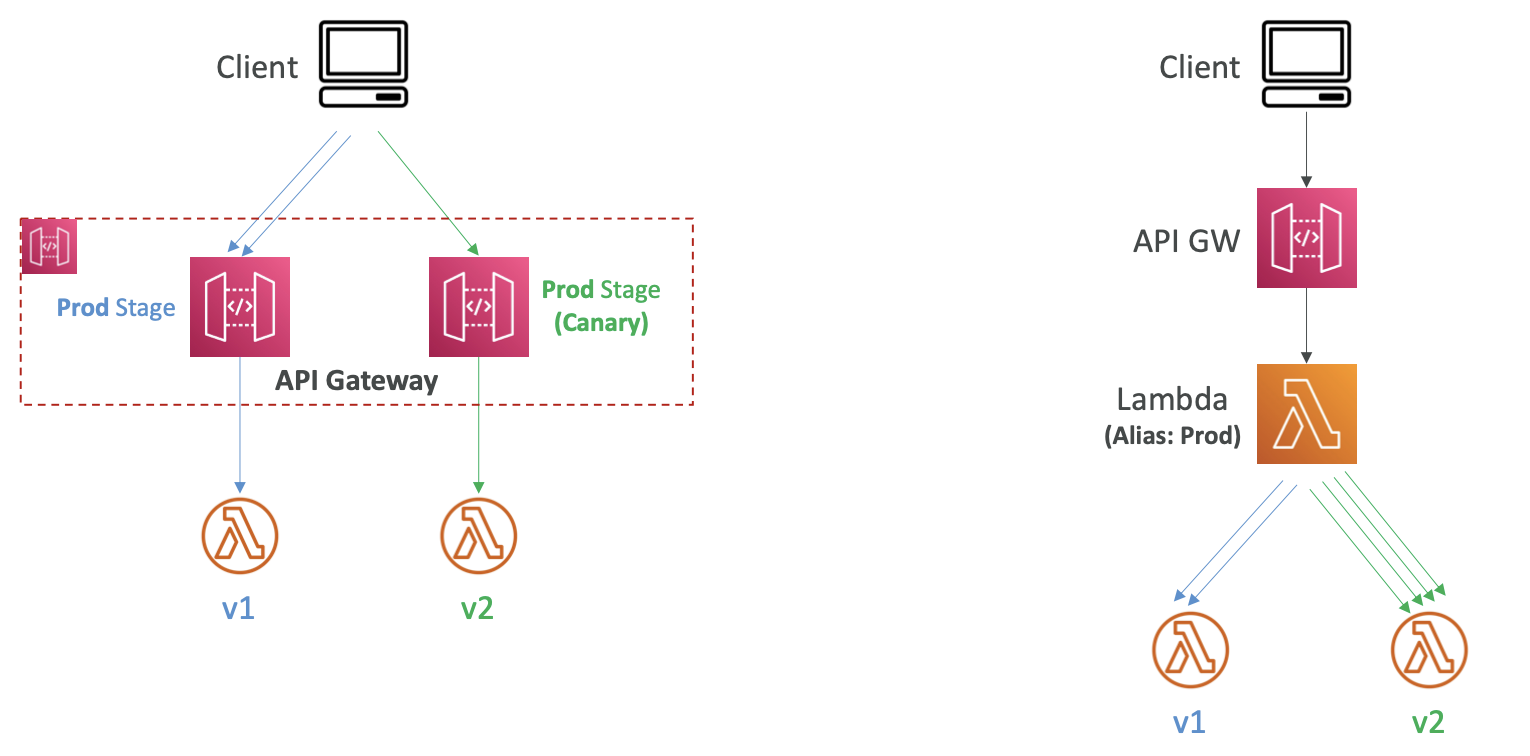
- 예시 1
- API 게이트웨이를 사용하는 경우에는 전략이 달라진다.
- v1 람다 함수에 연결된 "운영 스테이지"가 있다.
- 현재 API 게이트웨이에 대한 모든 클라이언트 요청은 이 스테이지를 거친다.
- 그린 스테이지인 "카나리 스테이지"를 배포할 수 있다.
- 이 스테이지는 v2 버전의 람다 함수에 연결된다.
- 이 상태에서 클라이언트가 내부적으로 "카나리 스테이지"로 리디렉션되어 일부 트래픽을 전송한다.
- "카나리 스테이지"의 작동 상태가 정상이라고 판단되면 스테이지를 승격할 수 있다.
- 장점은 네트워크 트래픽을 완전히 제어할 수 있고 모든 트래픽을 언제든지 운영에서 카나리로 한 번에 전환할 수 있다는 것이다.
- 예시 2
- "예시 1"의 대안은 람다 별칭을 사용하는 것이다.
- API 게이트웨이에 스테이지가 하나만 있으면 변경되지 않는다.
- 대신 람다 별칭이 v1 버전의 람다 함수를 가리킨다.
- 또한 v2를 배포하고 별칭에서 트래픽을 v1에서 v2로 전환하는 속도와 양을 제어할 수 있다.
- API 게이트웨이를 변경하지 않아도 되며, 클라이언트를 변경하지 않아도 된다.
Multi Region Services
- 다중 리전을 지원하는 다양한 서비스가 있다.
- DynamoDB Global Tables (양방향 복제, 스트림을 통한 지원)
- AWS Config Aggregators (다중 리전 & 다중 계정)
- RDS Cross Region Read Replicas (읽기 및 DR에 사용)
- Aurora Global Database (한 리전은 마스터이고 다른 리전은 읽기 전용 및 DR용)
- EBS Volumes snapshots, AMI, RDS 스냅샷을 다른 리전으로 복사 가능
- 리전 간 프라이빗 트래픽을 허용하는 VPC 피어링을 생성할 수 있다.
- Route 53은 DNS 서버의 글로벌 네트워크를 사용한다.
- S3 교차 리전 복제를 지원한다.
- 엣지 로케이션의 글로벌 CDN을 위한 CloudFront
- 엣지 로케이션의 글로벌 람다 함수를 위한 Lambda@Edge (A/B 테스트)
Multi Region with Route 53
- 상태 점검을 통해 자동화된 DNS 장애 조치를 지원한다.
- 엔드포인트(애플리케이션, 서버, 기타 AWS 리소스 등..)를 모니터링하는 상태 확인
/health경로를 생성하는데 유용하다. - 다른 상태 점검을 모니터링하는 상태 점검(계산된 상태 점검)을 제공한다.
- CloudWatch 알람을 모니터링하는 상태 점검 (예: DynamoDB 제한, 사용자 지정 지표 등..)
- 엔드포인트(애플리케이션, 서버, 기타 AWS 리소스 등..)를 모니터링하는 상태 확인
- 상태 점검은 CW 지표와 통합된다.
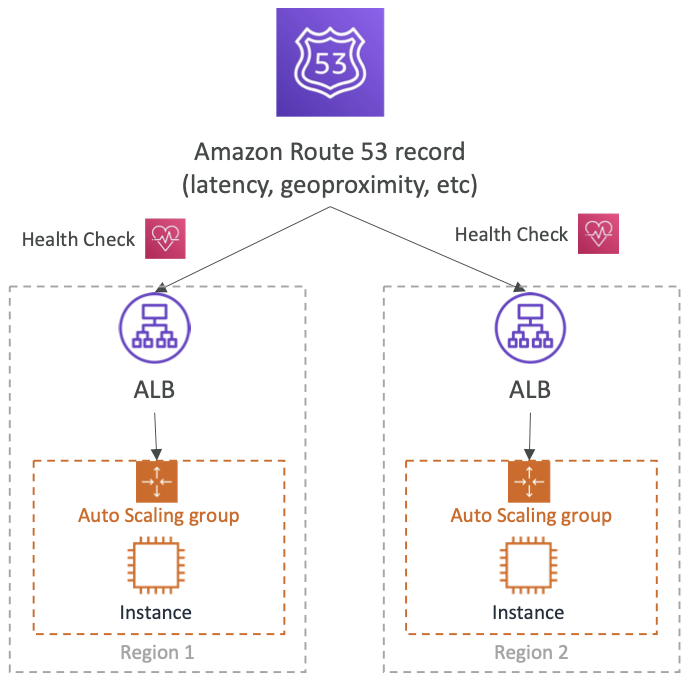
- 다중 리전에 배포된 아키텍처가 있고 Route 53을 사용하여 특정 리전으로 리디렉션한다.
- 지연 시간 레코드나, 지리적 근접성 레코드 등을 사용할 수 있다.
- 단, 상태 점검 사용과 호환되어야 한다.
Multi-Region Architectures
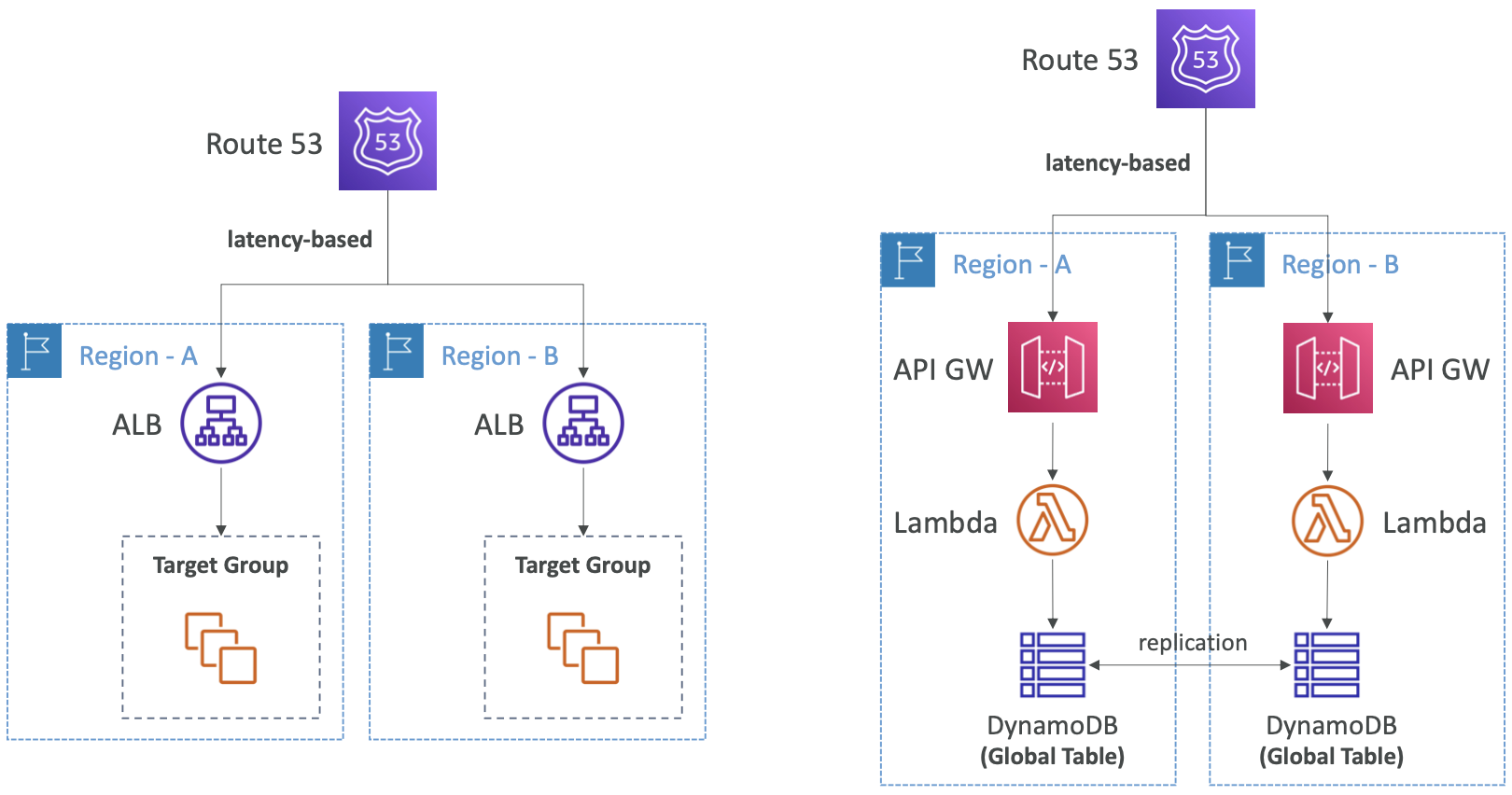
- 이전 아키텍처와 동일하게 두 개의 리전으로 이루어져 있다.
- Route 53을 지연 시간 기반으로 사용하여 사용자에게 가장 가까운 리전으로 리디렉션할 수 있다.
- 동일한 지연 시간 요구사항을 사용하지만 API 게이트웨이를 사용한다면 아키텍처의 작동 방식 면에서는 변화가 없다.
- 하지만 데이터 레이어를 사용하는 경우 DynamoDB와 같은 것을 사용할 수 있고 전역 테이블을 설정하여 다중 리전에 걸쳐 테이블이 복제되도록 할 수 있다.
- 따라서 각 리전의 각 ALB 함수는 DynamoDB에 대한 지연 시간이 짧은 데이터 액세스 권한을 보유하므로 애플리케이션의 지연 시간을 더욱 개선하는 데 좋을 수 있다.
Complex Routing
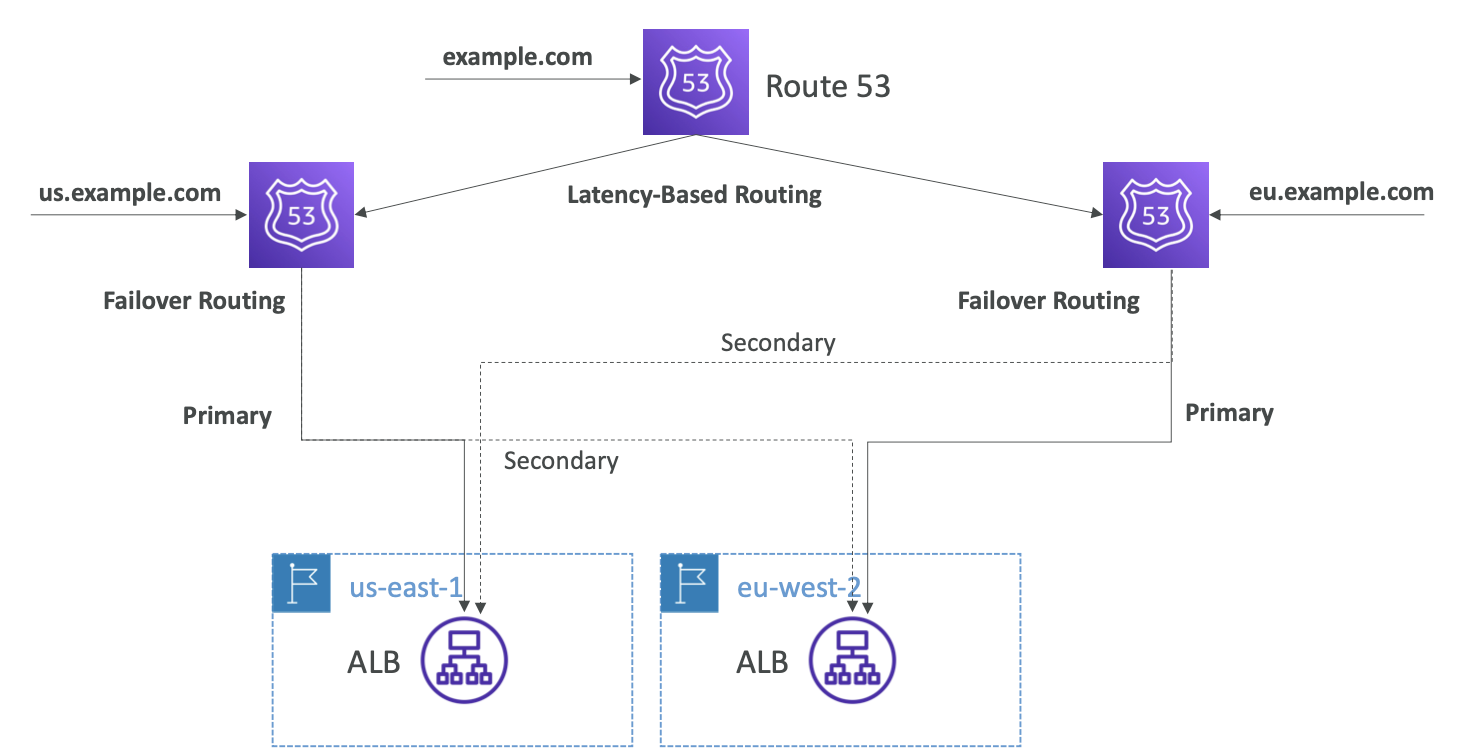
- Route 53을 사용하면 매우 복잡한 라우팅을 실행할 수 있다.
- 다른 두 개의 AZ에 애플리케이션이 있다고 가정한다.
us.example.com레코드를 설정할 수 있다.- 이 레코드는 한 리전이 기본이고 다른 리전이 보조가 되도록 하는 장애 조치 라우팅이 된다.
- 마찬가지로
eu.example.com을 만들어eu리전을 기본으로 하고us리전을 보조로 하도록 할 수 있다. - 끝으로
example.com은us.example.com과eu.example.com에 대한 지연 시간 레코드로 별칭을 가질 수 있다. - 따라서 다양한 방법으로 도메인 이름에 액세스하면서도 최상의 지연 시간으로 장애에 대한 복원력을 유지할 수 있다.
Disaster Recovery
- 회사의 사업 지속성 또는 재무에 부정적인 영향을 미치는 모든 사건을 재해(Disaster)로 정의할 수 있다.
- 재해 복구(DR)는 재해에 대비하고 복구하는 것을 의미한다.
- 다양한 종류의 재해 복구 방법이 있다.
- 온프레미스 -> 온프레미스: 전통적인 DR이며 매우 많은 비용이 발생한다.
- 온프레미스 -> AWS 클라우드: 하이브리드 재해 복구다.
- AWS 클라우드 리전 A -> AWS 클라우드 리전 B
- 재해 복구를 위한 두 개의 용어를 기억해야 한다.
- RPO: Recovery Point Objective
- RTO: Recovery Time Objective
RPO & RTO

- RPO는 "복구 지점 목표"로 백업을 얼마나 자주 실행하는지에 따라 결정된다.
- 재해가 발생하면 기본적으로 RPO와 재해 발생시점 사이의 시간은 데이터가 손실된다.
- 예를 들어, 매시간 데이터를 백업했는데 재해가 발생하면 한 시간 전으로 돌아갈 수 있으므로 한 시간의 데이터가 손실된다.
- 실제로는 요구 사항에 따라 다르지만 RPO는 재해 발생 시 데이터 손실을 어느 정도 수용할 의향이 있는지에 따라 결정된다.
- RTO는 재해가 발생한 시점부터 복구될 때까지의 시간이다.
- 따라서 재해 발생 시점과 RTO 사이에는 애플리케이션의 가동 중지 시간이 있다.
- 기본적으로 RPO 최적화는 RTO 솔루션과 아키텍처 결정을 추진하며, 비용과 직결된다.
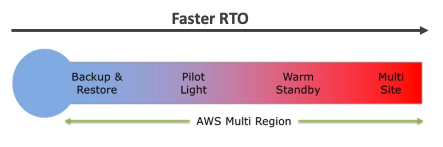
Strategy
- 일반적으로 사용되는 재해 복구 전략은 네 가지가 있다.
- Backup and Restore
- Pilot Light
- Warm Standby
- Hot Site / Multi Site Approach
Backup & Restore (High RPO)
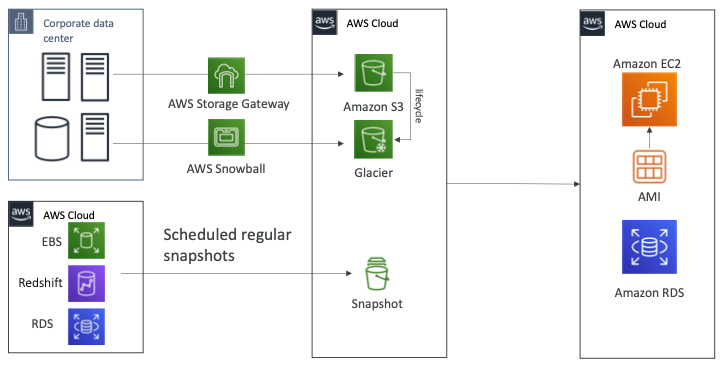
- 회사에 데이터 센터가 있고 AWS 클라우드에는 S3 버킷이 있다.
- 데이터를 백업하는 경우 AWS 스토리지 게이트웨이를 사용할 수 있다.
- 비용 최적화를 목적으로 S3 라이프사이클 정책을 통해 Glacier로 데이터를 전환할 수 있다.
- 스노우볼 패밀리를 사용하는 경우 일주일에 한 번씩 대용량의 데이터를 Glacier로 이전할 수도 있다.
- 이러한 경우 RPO는 일주일정도가 된다.
- AWS 클라우드를 사용한다면 EBS 볼륨, Redshift, RDS를 사용하게 되고 RPO는 24시간 혹은 1시간정도 된다.
- 얼마나 자주 스냅샷을 생성하는지에 따라 RPO가 결정된다.
- 재해가 발생하면 모든 데이터를 복원해야 하며 AMI를 이용해 EC2 인스턴스를 재생성하고 애플리케이션을 실행할 수 있다.
- 스냅샷을 사용하여 바로 복원하고 RDS 데이터베이스나 EBS 볼륨, Redshift 등을 재생성할 수 있다.
- 데이터를 복원하는데 시간이 많이 걸리며 RTO 또한 높지만, 비용이 저렴하다.
Pilot Light
- 작은 버전의 앱이 항상 클라우드에서 실행되고 있다.
- 백업 및 복원과 매우 유사하게 작동한다.
- 중요한 시스템이 이미 설치되어 있으므로 백업 및 복원보다는 속도가 빠르다.
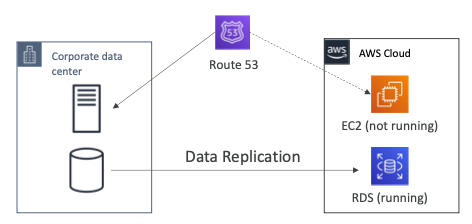
- 데이터 센터에 서버와 데이터베이스가 있고 AWS 클라우드에는 EC2 인스턴스와 RDS가 있다.
- 데이터 센터의 데이터베이스는 지속적으로 RDS로 데이터가 복제되고 있다.
- 만약 재해가 발생하면 EC2 인스턴스를 실행하고 Route53은 트래픽을 EC2 인스턴스로 전환한다.
Warm Standby
- 전체 시스템이 가동 중이지만 최소한의 규모로 실행되고 있다.
- 재해가 발생하는 경우 운영 수준의 트래픽을 처리할 수 있을 정도로 확장될 수 있다.
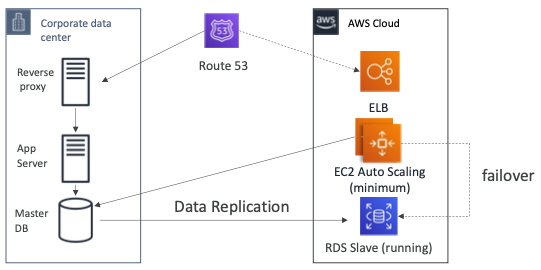
- 데이터 센터에는 리버스 프록시, 앱 서버, 마스터 DB가 실행되고 있다.
- Route 53은 회사의 데이터 센터로 트래픽을 전달하고 있다.
- 데이터 센터의 DB에서 클라우드의 RDS로 데이터 복제가 이루어지고 있다.
- AWS의 EC2 Auto Scaling Group은 최소한의 용량으로 실행되고 있으여 데이터 센터의 DB와 통신하고 있다.
- 재해가 발생하는 경우 Route53은 페일오버하여 트래픽을 AWS의 ELB로 전달하도록 수정한다.
- EC2 인스턴스 또한 데이터 센터의 DB가 아니라 RDS를 바라보도록 페일오버할 수 있다.
- 이전에 살펴본 전략보다 RPO와 RTO를 낮출 수 있지만 많은 비용이 발생한다.
Multi Site / Hot Site Approach
- 매우 낮은 RTO를 제공하지만 매우 높은 비용을 지불해야 한다.
- 운영 수준의 트래픽을 처리할 수 있는 시스템을 온프레미스 서버와 클라우드에서 실행하고 있다.
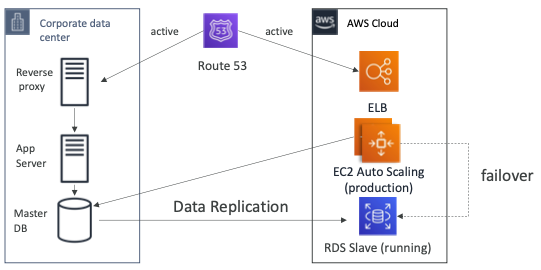
- 온프레미스 서버와 AWS 서버에서 운영 수준의 애플리케이션이 실행 중이므로 Route 53은 양쪽으로 트래픽을 전달한다.
- 온프레미스에 재해가 발생하는 경우 EC2 인스턴스는 RDS Slave 데이터베이스에 페일오버할 수 있다.
AWS Multi Region
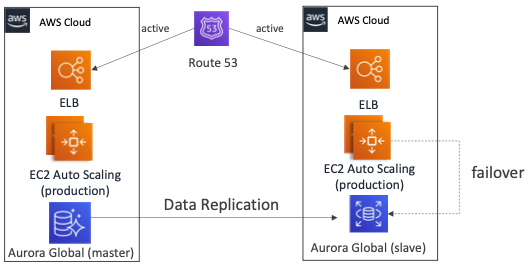
- 클라우드에서 다중 리전을 사용하는 경우에도 재해 복구 전략을 만들 수 있다.
- 하나의 리전에 Aurora Global 마스터 DB가 있고 다른 리전에 Aurora Global Slave DB가 있으며 데이터는 지속적으로 복제되고 있다.
- Route53은 두 리전으로 트래픽을 전달하고 있기 때문에 하나의 리전에 재해가 발생하더라도 사용자의 트래픽을 처리할 수 있다.
Tips
- Backup
- EBS 스냅샷, RDS 자동화된 백업 및 스냅샷 등..
- S3 / S3 IA / Glacier, 라이프사이클 정책, 지역 간 복제에 대한 정기적인 추진
- 온프레미스 데이터를 스노우볼 또는 스토리지 게이트웨이를 통해 클라우드로 복제
- High Availability
- Route 53을 사용하여 DNS를 리전에서 리전으로 마이그레이션
- RDS Multi-AZ, ElastiCache Multi-AZ, EFS, S3
- 기본적으로 Direct Connect를 사용하는 경우 재해 복구 용도로 Site to Site VPN을 사용할 수 있다.
- Replication
- RDS 복제(지역 간), Aurora + Global Database
- 온프레미스에서 RDS로 데이터베이스 복제
- 스토리지 게이트웨이
- Automation
- 완전히 새로운 환경을 재현하기 위한 CloudFormation / Elastic Beanstalk
- 알람이 실패하는 경우 CloudWatch를 사용하여 EC2 인스턴스 복구 및 재부팅
- 맞춤형 자동화를 위한 AWS 람다 함수
- Chaos
- 넷플릭스는 EC2를 무작위로 종료하는 "simian-army"를 가지고 있다.
참고한 강의
'Infrastructure > Certificate' 카테고리의 다른 글
| [DOP] Incident Event Response (0) | 2024.02.01 |
|---|---|
| [DOP] Monitoring & Logging (0) | 2024.02.01 |
| [DOP] Storage & Database (Resilient Cloud Solutions) (0) | 2024.01.31 |
| [DOP] Route 53 (Resilient Cloud Solutions) (0) | 2024.01.29 |
| [DOP] Kinesis (Resilient Cloud Solutions) (0) | 2024.01.29 |



